scrapy爬豆瓣电影
2015-06-19 00:04
597 查看
usage:
scrapy crawl first
一、抓取效果
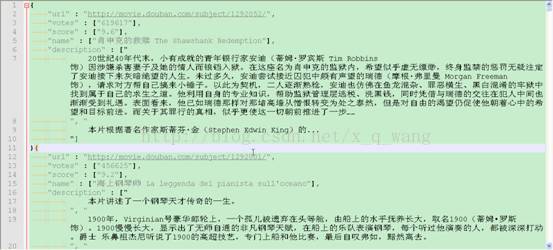
二、源码下载
http://download.csdn.net/detail/wxq714586001/8821149
三、总结
done:
1、解决了将unicode字符串(类似于‘\uxxx\n\t\t’)转换为实际的文字,困扰了很久。
2、用正则表达式替换字符串。
3、scrapy的基本使用方法。
todo:
1、爬了一段时间就被豆瓣禁了。
2、存储了一些无效的链接。
scrapy crawl first
一、抓取效果
二、源码下载
http://download.csdn.net/detail/wxq714586001/8821149
三、总结
done:
1、解决了将unicode字符串(类似于‘\uxxx\n\t\t’)转换为实际的文字,困扰了很久。
2、用正则表达式替换字符串。
3、scrapy的基本使用方法。
todo:
1、爬了一段时间就被豆瓣禁了。
2、存储了一些无效的链接。

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例