淘宝开源项目TbSchedule的部署和使用
2015-06-17 17:57
549 查看
tbschedule项目其实可以分为两部分:
schedule管理控制台。负责控制、监控任务执行状态
实际执行job的客户端程序。
在实际使用时,首先要启动zookeeper, 然后部署tbschedule web界面的管理控制台,最后启动实际执行job的客户机器。这里zookeeper并不实际控制任务调度,它只是负责与N台执行job的客户端通讯,协调、管理、监控这些机器的运行信息。实际分配任务的是tbschedule管理控制台,控制台从zookeeper获取job的运行信息。
tbSchedule通过控制
定义时间计量单位。这里表示一个
定义快照(snapshot)文件的存储位置。zookeeper会将节点信息定时写入到这个目录中。这个目录必须存在,否则启动时会报错。
指定客户端连接端口。 zookeeper会在这个端口监听连接请求。
这个参数仅在集群部署时起作用。格式为:
配置完成后,切换到
即可启动zookeeper,默认会在后台运行,如果想在前端运行,需要执行:
注意,当你在启动第一个zookeeper时控制台会大量报错,这是因为其它的zookeeper还没有启动。无视即可。
即可。
如果你想手动编译、构建项目而不是使用
时
第一次访问控制台时会出现以下配置页面:
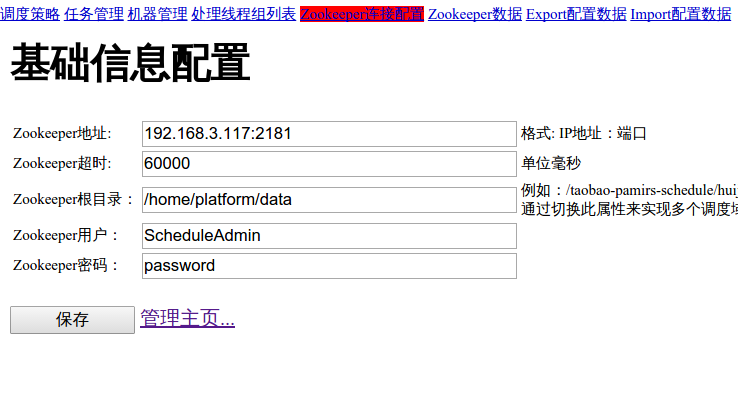
第一行指定zookeeper的地址、端口,第二行是超时时间。用户名和密码在这里没有任何用处,无视即可。要注意的是第三行Zookeeper的根目录,这并不是指的部署zookeeper时指定的
填写完成后点
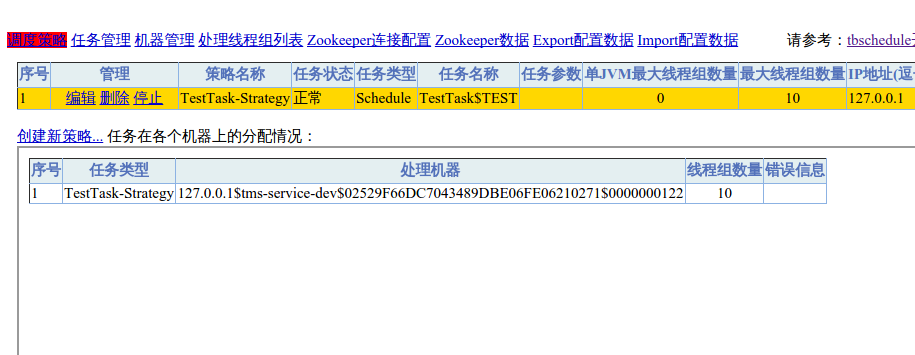
至此tbSchedule控制台部署完毕。
把测试跑一遍。跑之前要修改项目中
当我们要执行一个job时,需要创建新项目,引入
启动job。依赖如下:
同时别忘了集成spring。
Main方法代码如下:
执行这个方法后,你的程序就会向zookeeper发起连接,注册当前机器,请求任务队列,最后根据调度配置执行job。
job的执行代码需要配置成一个
这个bean的骨架如下:
其中泛型参数
tbSchedule的调用流程为:
执行
执行
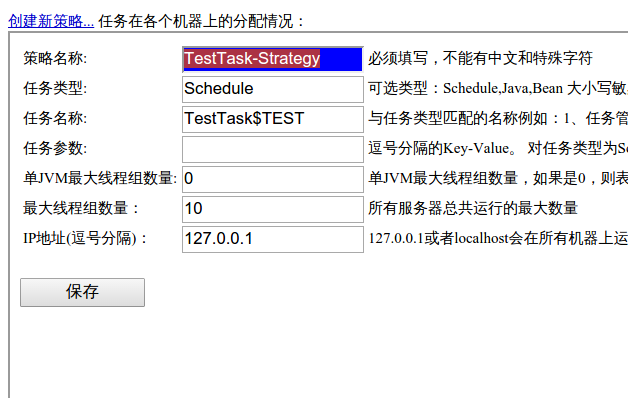
注意,任务名称格式为
任务管理 -> 创建新任务:
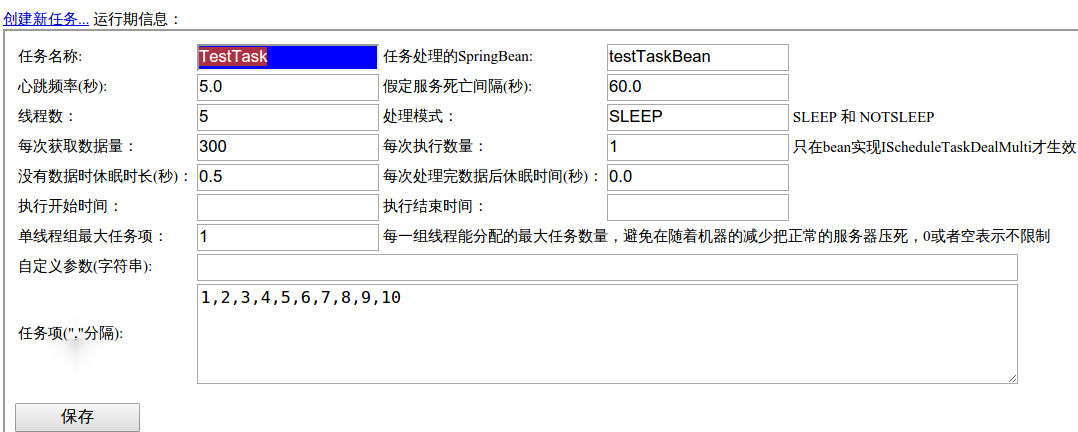
这是对单个job的调度配置信息。
重要参数说明:
任务名称
就是刚才在配置策略时填写的名称(
处理模式
当某一个线程任务处理完毕,从任务池中取不到任务的时候,检查其它线程是否处于活动状态。如果是,则自己休眠; 如果其它线程都已经因为没有任务进入休眠,当前线程是最后一个活动线程的时候,就调用业务接口,获取需要处理的任务,放入任务池中, 同时唤醒其它休眠线程开始工作。
当一个线程任务处理完毕,从任务池中取不到任务的时候,立即调用业务接口获取需要处理的任务,放入任务池中。
任务项
可以把任务划分为1,2,3,4,5,6,7,8, 9, 10一共10个任务碎片,10个任务碎片会被分配到10(刚才在
schedule管理控制台。负责控制、监控任务执行状态
实际执行job的客户端程序。
在实际使用时,首先要启动zookeeper, 然后部署tbschedule web界面的管理控制台,最后启动实际执行job的客户机器。这里zookeeper并不实际控制任务调度,它只是负责与N台执行job的客户端通讯,协调、管理、监控这些机器的运行信息。实际分配任务的是tbschedule管理控制台,控制台从zookeeper获取job的运行信息。
tbSchedule通过控制
ZNode的创建、修改、删除来间接控制Job的执行,执行Job的客户端会监听它们对应
ZNode的状态更新事件,从而达到通过tbSchedule控制Job执行的目的。
部署zookeeper
去http://zookeeper.apache.org/releases.html#download下载最新稳定版本。下载完成后解压,将/conf目录下的
XXX.cfg更名为
zoo.cfg,因为zookeeper启动时会在这个目录下找
zoo.cfg读取配置信息。这个文件里有几个重要的参数需要说明一下:
tickTime=2000
定义时间计量单位。这里表示一个
tick为2秒。以后在配置时间相关的东西时,都是以
tick为单位的。
dataDir=/tmp
定义快照(snapshot)文件的存储位置。zookeeper会将节点信息定时写入到这个目录中。这个目录必须存在,否则启动时会报错。
clientPort=2181
指定客户端连接端口。 zookeeper会在这个端口监听连接请求。
server.1=127.0.0.1:2000:3000
这个参数仅在集群部署时起作用。格式为:
server.id=host:port:port。
id表示服务器的唯一标识,一般从1开始计数。第一个
port表示zookeeper集群机器之间的通讯端口,第二个
port表示当集群机器在选举
leader时使用的通讯端口。只有当集群第一次启动,或
master机崩溃时,才会进行
leader选举。
配置完成后,切换到
/bin目录,执行:
./zkServer.sh start
即可启动zookeeper,默认会在后台运行,如果想在前端运行,需要执行:
./zkServer.sh start-foreground
Zookeeper集群部署
集群部署时,除了需要指定zoo.cfg中
server.X:XXXX:XX:XX参数外,还要在每台机器的
dataDir目录下创建一个名为
myid的文件,内容为当前机器的标识数字,与
server.X中的
X相同。完成配置后,依次启动每个zookeeper即可。
注意,当你在启动第一个zookeeper时控制台会大量报错,这是因为其它的zookeeper还没有启动。无视即可。
tbSchedule控制台部署
tbSchedule就是个用servlet/JSP写的web项目,我们可以直接把
war包部署到
tomcat中,然后在浏览器访问
http://localhost:8080/ScheduleConsole
即可。
如果你想手动编译、构建项目而不是使用
war包,要小心一个坑,那就是执行
mvn clean install -Dmaven.test.skip=true
时
maven会报找不到构件的错误。查其原因,是因为这个项目太老了,当时是用maven2构建的,项目中用到的依赖版本也比较老了,而且它们所在的repository已经停用了,因此无法自动下载。解决方法,直接
exclusion缺少的依赖即可:
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.3.3</version> <exclusions> <exclusion> <groupId>com.sun.jmx</groupId> <artifactId>jmxri</artifactId> </exclusion> <exclusion> <groupId>com.sun.jdmk</groupId> <artifactId>jmxtools</artifactId> </exclusion> <exclusion> <groupId>javax.jms</groupId> <artifactId>jms</artifactId> </exclusion> </exclusions> </dependency>
第一次访问控制台时会出现以下配置页面:
第一行指定zookeeper的地址、端口,第二行是超时时间。用户名和密码在这里没有任何用处,无视即可。要注意的是第三行Zookeeper的根目录,这并不是指的部署zookeeper时指定的
dataDir,而是一个你自己指定的、与当前管理控制台在同一个机器上的目录,tbSchedule管理控制台会将任务的配置信息(如执行开始时间,调度策略)保存到该目录下,这样下次启动管理控制台时就可以直接从目录中读取配置信息了。
填写完成后点
保存,此时上面会出现一行红字,无视之。直接点击
管理主页即可进入管理页面:
至此tbSchedule控制台部署完毕。
tbSchedule客户端编写
tbSchedule项目的test/目录下有很多测试类,可以执行
mvn test
把测试跑一遍。跑之前要修改项目中
schedule.xml文件正确填写zookeeper的连接地址。测试跑通则说明tbSchedule管理控制台和zookeeper都部署无误。
当我们要执行一个job时,需要创建新项目,引入
tbschedule依赖,实现指定接口,然后打成
jar包,通过
java -jar 你的jar名.jar
启动job。依赖如下:
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.6</version> </dependency> <dependency> <groupId>com.taobao.pamirs.schedule</groupId> <artifactId>tbschedule</artifactId> <version>3.2.18</version> </dependency>
同时别忘了集成spring。
Main方法代码如下:
public static void main(String[] args) throws Exception {
ApplicationContext ctx = new ClassPathXmlApplicationContext(
"spring-config.xml");
TBScheduleManagerFactory scheduleManagerFactory = new TBScheduleManagerFactory();
Properties p = new Properties();
p.put("zkConnectString", "192.168.3.117:2181");
p.put("rootPath", "/home/platform/data");
p.put("zkSessionTimeout", "60000");
p.put("userName", "ScheduleAdmin");
p.put("password", "password");
p.put("isCheckParentPath", "true");
scheduleManagerFactory.setApplicationContext(ctx);
scheduleManagerFactory.init(p);
scheduleManagerFactory.setZkConfig(convert(p));
}执行这个方法后,你的程序就会向zookeeper发起连接,注册当前机器,请求任务队列,最后根据调度配置执行job。
job的执行代码需要配置成一个
spring bean:
<bean id="testTaskBean" class="com.anzhi.schedule.task.TestTaskBean" > <property name="jdbcTemplate" ref="jdbcTemplate" /> </bean>
这个bean的骨架如下:
public class TestTaskBean implements IScheduleTaskDealSingle<PassportModel> {
/**
* 选择任务. 从DB中读取数据, 将取出的数据返回
* @param taskParameter
* @param ownSign
* @param taskItemNum
* @param taskItemList
* @param eachFetchDataNum
* @return
* @throws Exception
*/
public List<PassportModel> selectTasks(String taskParameter, String ownSign,
int taskItemNum, List<TaskItemDefine> taskItemList,
int eachFetchDataNum) throws Exception {
List<PassportModel> list = new ArrayList<PassportModel>(1);
list.add(new PassportModel());
return list;
}
/**
* 向目标表中插入数据
* @param model
* @param ownSign
* @return
* @throws Exception
*/
public boolean execute(PassportModel model, String ownSign)
throws Exception {
try {
//insertData(model);
System.out.println("执行任务");
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
}其中泛型参数
Passport是我们自定义的类。
tbSchedule的调用流程为:
执行
selectTasks()方法,该方法返回一个
List对象,表示你选择出的任务列表。
执行
execute()方法,tbschedule会遍历你在
selectTasks()方法中返回的
List,然后对每一个元素都调用
execute()方法。
任务调度的配置
进入tbSchedule管理控制台,创建一个新策略:注意,任务名称格式为
创建的任务名$自定义字符串。其中你自定义的字符串会被传递到
selectTasks()方法中的
ownSign参数中。
任务管理 -> 创建新任务:
这是对单个job的调度配置信息。
重要参数说明:
任务名称
就是刚才在配置策略时填写的名称(
$之前的部分)。
处理模式
SLEEP模式
当某一个线程任务处理完毕,从任务池中取不到任务的时候,检查其它线程是否处于活动状态。如果是,则自己休眠; 如果其它线程都已经因为没有任务进入休眠,当前线程是最后一个活动线程的时候,就调用业务接口,获取需要处理的任务,放入任务池中, 同时唤醒其它休眠线程开始工作。
NOTSLEEP模式
当一个线程任务处理完毕,从任务池中取不到任务的时候,立即调用业务接口获取需要处理的任务,放入任务池中。
任务项
可以把任务划分为1,2,3,4,5,6,7,8, 9, 10一共10个任务碎片,10个任务碎片会被分配到10(刚才在
创建调度策略中配置的)个线程组,那么每个线程组对应1个任务碎片,运行时任务项参数又被传递到bean任务类selectTasks方法的List queryCondition参数,例如第1个线程组调用selectTasks方法是queryCondition参数条件为1 ,第2个线程组执行参数条件为2。 我们需要在方法中自己解析这个数值,根据值的不同执行不同部分的任务。因为一个线程组会有多个线程,因此可以实现并行计算。
执行job
完成以上工作后,运行编写的job客户端,job即可被调度执行。

相关文章推荐
- c#定时器和global实现自动job示例
- 关于开源项目《Scavenger》
- Smarty --roles of template designer and programmer
- job requirements
- oracle job 设置自动执行,执行错误,如何解决呢?
- java job(spring)
- 创建ORACLE JOB
- sql server 2005 代理作业
- oracle 创建job
- oracle定时任务以及DBLink创建
- dbms_scheduler包中job(作业)学习
- job的使用
- 多个mapreduce过程的组合模式
- The classical mistake in the job interview
- Cover Letter
- Curriculum Vitae
- JOB DESCRIPTION
- 创建ORACLE JOB
- 使用Java程序调用本地转换盒作业,资源库中的转换和作业(kettle4.2)