xloadtree实现web动态目录树(分层加载)
2015-06-11 10:34
211 查看
最近在做老师的项目,第一个任务:做一个java web目录树要求实现数据的动态加载,即点击一个节点加载一层数据,经过一个星期的尝试探索期间用了几个比较流行的树插件
(js包),最终用xloadtree实现了。(选js包的原因是因为自己web网页基础就是一坨翔啊T_T,看到这里大神请绕道)
什么是xloadtree,这里放一个链接看完就会略知一二,点击打开链接
现在可以看看我是怎么做的,大家可以先把相关的资源包下载下来,点击打开链接
建数据库什么的大家应该都会,在这里就不啰嗦了
1,我先写了一个Node类,建类的原因当然是为了好封装啊,开发便捷,面向对象啊什么的(哈哈哈
 )
)
一般对象的属性会和数据库表中的属性保持一致,我的如下:
public class Node {
private String node_id;
private String parent_id;
private String node_name;
private String ref_url;
public Node() {
// TODO Auto-generated constructor stub
}
public String getNode_id() {
return node_id;
}
public void setNode_id(String node_id) {
this.node_id = node_id;
}
public String getParent_id() {
return parent_id;
}
public void setParent_id(String parent_id) {
this.parent_id = parent_id;
}
public String getNode_name() {
return node_name;
}
public void setNode_name(String node_name) {
this.node_name = node_name;
}
public String getRef_url() {
return ref_url;
}
public void setRef_url(String ref_url) {
this.ref_url = ref_url;
}
}2,数据库操作类,(我用的是sqlite数据库,这个数据库的优点就是,只需一个jar包就能写数据库,槽点吗?谁用谁知道
)
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import bean.Node;
public class DBHelper {
String driver_name = "org.sqlite.JDBC";
String db_url = "jdbc:sqlite://g:/tree.db";
public Connection getConnection(){
try {
Class.forName(driver_name);
Connection conn = DriverManager.getConnection(db_url);
return conn;
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch(SQLException se){
se.printStackTrace();
}
return null;
}
public ArrayList<Node> getNodeInfo(Connection conn,String id){
String sql = "select * from tree where node_id='"+id+"'";
PreparedStatement pre = null;
ResultSet rs = null;
ArrayList<Node> list = new ArrayList<Node>();
try {
pre = conn.prepareStatement(sql);
rs =pre.executeQuery();
if(rs!=null){
list = new ArrayList<Node>();
}
while (rs!=null&&rs.next()){
Node node = new Node();
node.setNode_id(rs.getString("node_id"));
node.setNode_name(rs.getString("node_name"));
node.setParent_id(rs.getString("parent_id"));
node.setRef_url(rs.getString("ref_url"));
list.add(node);
}
rs.close();
pre.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
pre = null;
conn = null;
rs = null;
}
return list;
}
public ArrayList<Node> getNodeInfoByParentId(Connection conn,String id){
System.out.println("id is "+id);
String sql = "select * from tree where parent_id="+id+"";
System.out.println("sql= "+sql);
PreparedStatement pre = null;
ResultSet rs = null;
ArrayList<Node> list =null;
try {
pre = conn.prepareStatement(sql);
rs =pre.executeQuery();
if(rs!=null){
list = new ArrayList<Node>();
}
while (rs!=null&&rs.next()){
Node node = new Node();
node.setNode_id(rs.getString("node_id"));
node.setNode_name(rs.getString("node_name"));
node.setParent_id(rs.getString("parent_id"));
node.setRef_url(rs.getString("ref_url"));
list.add(node);
}
rs.close();
pre.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
pre = null;
conn = null;
rs = null;
}
return list;
}
}上面有2个函数分别是根据node的id来查询数据,这个是为了树的初始化的时候后来加载根节点,另id直接等于0(根节点)。第二个函数就是以此节点id为parent_id来查询数据,如果返回的结果集不为空则说明该节点是有子节点的,我们就给该节点加tree.xml(前提是你看了xloadtree的相关知识
)
下面是节点的初始页面用jsp(jsp+javascript)写的:
<%@ page language="java" import="java.util.*" pageEncoding="GB18030"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<%@page import="db.DBHelper" %>
<%@page import="bean.Node" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>My JSP 'xTree.jsp' starting page</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script type="text/javascript" src="xtree.js"></script>
<script type="text/javascript" src="xmlextras.js"></script>
<script type="text/javascript" src="xloadtree.js"></script>
<link type="text/css" rel="stylesheet" href="xtree.css" />
</head>
<body>
<%
String node_id=request.getParameter("id");
ArrayList<Node> list=null;
if(node_id==null){
DBHelper helper = new DBHelper();
list= helper.getNodeInfo(helper.getConnection(),"0");
}
String name = list.get(0).getNode_name();
int times =3;
%>
<script type="text/javascript">
webFXTreeConfig.rootIcon = "images/folder.png";
webFXTreeConfig.openRootIcon = "images/openfolder.png";
webFXTreeConfig.folderIcon = "images/folder.png";
webFXTreeConfig.openFolderIcon = "images/openfolder.png";
webFXTreeConfig.fileIcon = "images/file.png";
webFXTreeConfig.lMinusIcon = "images/Lminus.png";
webFXTreeConfig.lPlusIcon = "images/Lplus.png";
webFXTreeConfig.tMinusIcon = "images/Tminus.png";
webFXTreeConfig.tPlusIcon = "images/Tplus.png";
webFXTreeConfig.iIcon = "images/I.png";
webFXTreeConfig.lIcon = "images/L.png";
webFXTreeConfig.tIcon = "images/T.png";
var tree = new WebFXTree("Root");
var node_id = "<%=list.get(0).getNode_id()%>";
var node_name = "<%=name%>";
tree.add(new WebFXLoadTreeItem(node_name,"TreeXML.jsp?id='"+node_id+"'"));
document.write(tree);
</script>
</body>
</html>这些代码最重要的是tree.add(new WebFXLoadTreeItem(node_name,"TreeXML.jsp?id='"+node_id+"'"));实现和TreeXML.jsp的通信,TreeXML.jsp是处理分层加载的页面,即点击节点发送id给它,然后处理,代码如下:
<%
request.setCharacterEncoding("utf-8");
response.setContentType("text/xml;charset=utf-8");
out.println("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
out.println("<tree>");
String id = request.getParameter("id");
ArrayList<Node> list=null;
DBHelper helper = new DBHelper();
list= helper.getNodeInfoByParentId(helper.getConnection(),id);
if(list!=null){
for(int i=0;i<list.size();i++){
System.out.println("jin lai le");
ArrayList<Node> list2 = null;
list2 = helper.getNodeInfoByParentId(helper.getConnection(),list.get(i).getNode_id());
if(!list2.isEmpty()){
out.println("<tree text=\""+list.get(i).getNode_name()+"\" src=\"TreeXML.jsp?id="+list.get(i).getNode_id()+"\"/>");
}else{
out.println("<tree text=\""+list.get(i).getNode_name()+"\"/>");
}
}
}
list.clear();
out.println("</tree>");
%>
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@page import="db.DBHelper" %>
<%@page import="bean.Node" %>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>最后显示结果:
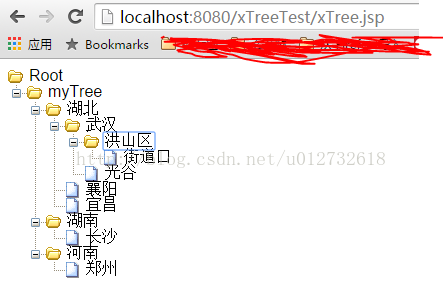
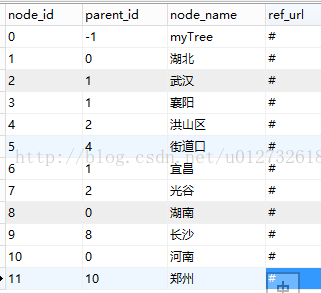
数据库截图:
后记:有不明白的欢迎留言

相关文章推荐
- xloadtree实现web动态目录树(分层加载)
- 分析xloadtree, 用ajax实现的动态目录树
- xloadtree实现动态树的加载
- [HTML/JS]利用JQuery的load函数动态加载其它页面的内容的实现代码代替Ifram
- 【HTML/JS】利用JQuery的load函数动态加载其它页面的内容的实现代码
- 笔记 C# 实现后台 动态加载 页面标题 Dynamic Load Page Title
- 【转】用ExtJS 实现动态载入树(Load tree)
- 用ExtJS 实现动态载入树(Load tree)
- spring+webwork的动态加载实现osgi的插件思想
- 用ExtJS 实现动态载入树(Load tree)
- 用ExtJS 实现动态载入树(Load tree)
- javascript树形菜单(一):Tigra Tree Menu,实现动态数据加载
- [UE4]C++实现动态加载的问题:LoadClass<T>()和LoadObject<T>() 及 静态加载问题:ConstructorHelpers::FClassFinder()和FObjectFinder()
- [UE4]C++实现动态加载的问题:LoadClass<T>()和LoadObject<T>()
- 利用JQuery的load函数动态加载其它页面的内容的实现代码
- Silverlight实用窍门系列:31.Silverlight中WebClient+StreamResourceInfo+反射实现动态加载外部XAP程序【附带源码】
- [UE4]C++实现动态加载的问题:LoadClass<T>()和LoadObject<T>()
- Ajaxload动态加载动画生成工具的实现(ajaxload的本地移植)
- 31.Silverlight中WebClient+StreamResourceInfo+反射实现动态加载外部XAP程序
- (更新版)ExtJS Tree利用json(直接传List TreeNode,不需要转化为JSONArray)在Struts 2实现Ajax动态加载树结点