机器学习--误差理论
2015-06-08 16:53
513 查看
本文转自:
http://blog.csdn.net/linkin1005/article/details/42563229
一、偏倚(bias)和方差(variance)
在讨论线性回归时,我们用一次线性函数
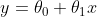
对训练样本进行拟合(如图1所示);然而,我们可以通过二次多项式函数对训练样本进行拟合(如图2所示),函数对样本的拟合程序看上去更“好”;当我们利用五次多项式函数对样本进行拟合(如图3所示),函数通过了所有样本,成为了一次“完美”的拟合。



图3建立的模型,在训练集中通过x可以很好的预测y,然而,我们却不能预期该模型能够很好的预测训练集外的数据。换句话说,这个模型没有很好的泛化能力。因此,模型的泛化误差(generalization error)不仅包括其在样本上的期望误差,还包括在训练集上的误差。
图1和图3中的模型都有较大的泛化误差,然而他们的误差原因却不相同。图1建立了一个线性模型,但是该模型并没有精确的捕捉到训练集数据的结构,我们称图1有较大的偏倚(bias),也称欠拟合;图3通过5次多项式函数很好的对样本进行了拟合,然而,如果将建立的模型进行泛化,并不能很好的对训练集之外数据进行预测,我们称图3有较大的,也称过拟合。
通常,在偏倚和方差之间,这样一种规律:如果模型过于简单,其具有大的偏倚,而如果模型过于复杂,它就有大的方差。调整模型的复杂度,建立适当的误差模型,就变得极其重要了。
二、预备知识
首先我们先介绍两个非常有用的引理:
引理1:一致限(the union bound)令
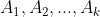
为k个不同的事件(不一定相互独立),那么有:
\le&space;P(A_1)+...+P(A_k))
一致限说明:k个事件中任一个事件发生的概率小于等于这k个事件发生的概率和(等号成立的条件为这k个事件相两两互斥)。
引理2:Hoeffding 不等式(Hoeffding inequality)令
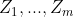
为m个独立同分布的随机变量,由参数为
的伯努利分布(即
=\phi,P(Z_i=0)=1-\phi)
)生成。令

,为这些随机变量的均值,对于任意
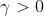
有:
\le2exp(-2\gamma^2m))
>1-2exp(-2\gamma^2m))
在机器学习中,引理2称为Chernoff边界(Chernoff bound),它说明:假设我们用随机变量的均值

去估计参数
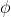
,估计的参数和实际参数的差超过一个特定数值的概率有一确定的上界,并且随着样本量m的增大,
与
很接近的概率也越来越大。
通过以上两个引理,我们能够引出机器学习中很重要结论。
为简单起见,我们只讨论二分类问题,即类标签为

。
假设给定的训练集为
},y^{(i)});i=1,...,m\})
,且各训练样本
},y^{(i)}))
独立同分布,皆为某个特定分布D生成。对于一个假设函数(hypothesis),定义训练误差(training
error)(也称为经验风险(empirical risk)或经验误差(empiriacal error))为:
=\frac{1}{m}\underset{i=1}{\overset{m}{\sum}}\&hash;\{h(x^{(i)})\neq&space;y^{(i)}\})
训练误差为模型在训练样本中的错分类的比例,如果我们要强调
)
是依赖训练集的,也可以将其写作
)
。
我们再定义泛化误差(generalization error):
=P_{(x,y)\sim&space;D}(h(x)\neq&space;y))
这里得到的是一个概率,表示通过特定的分布D生成的样本(x,y)中的y与通过预测函数h(x)生成的结果不同的概率。
注意,我们假设训练集的数据是通过某种分布D生成的,我们以此为依据来衡量假设函数。这里的假设有时称为PAC(probablyapproximately correct)假设。
在线性分类中,假设函数
=1\{\theta^{T}x\ge0\})
中参数
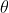
如何得来?其中一个方法就是调整参数
,使得训练误差最小,即:
)
我们称这样的方法为经验风险最小化(empirical risk mininmization,ERM),其中

,基于ERM原则的算法可视作最基本的学习算法。线性回归和logistic回归都可以看作是遵守ERM的算法。
我们定义假设类集合
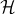
(hypothesis class)为所有假设函数的集合。例如线性分类问题中,

,其为所有的
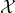
(输入的定义域),对应的线性决策边界。
因此,ERM也可以认为是一组分类器的集合中,使得训练误差最小的那个分类器,即:
)
3.有穷集
我们定义假设类集合

由k个假设类(hypotheses)构成。其中,
为k个由
至{0,1}的映射函数构成,ERM从集合中k个元素选择

使得训练误差最小。
为了确保
和泛化误差的差值是有上界的,即如果训练误差很小,那么泛化误差也不会太大,我们需要完成两个步骤:首先,证明对于任意h,
)
是对
)
的可靠估计;其次,证明
)
存在上界。
我们令

,随机变量Z服从伯努利分布,样本由分布

生成:即:
\sim&space;\mathcal&space;D)
。并且定义:
\neq&space;y\})
,即Z为指示变量,用来标记被假设函数
)
错误分类的样本。
泛化误差
定义为随机变量Z的期望,训练误差
)
为训练样本被假设函数误分类的比例,即:
=\frac{1}{m}\underset{j=1}{\overset{m}{\sum}}Z_j=\frac{1}{m}\underset{i=1}{\overset{m}{\sum}}\&hash;\{h_{j}(x^{(i)})\neq&space;y^{(i)}\})
利用Hoeffding不等式,可以得到:
-\hat{\varepsilon}(h_i)|>\gamma&space;)\le2exp(-2\gamma^{2}m))
从上式可以看出,对于特定的的
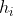
,当m很大时,训练误差和泛化误差很接近的概率很大。但是,我们不仅仅需要考察对于特定的
,训练误差和泛化误差的接近程度,而是需要验证对于所有的
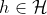
不等式也成立。
现令
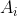
代表事件
-\hat{\varepsilon}(h_i)|>\gamma)
,对于任意
,存在
\le2exp(-2\gamma^2m))
,因此,由引理1可得:
-\hat{\varepsilon}(h_i)|>\gamma)&=P(A_1\cup...\cup&space;A_k)\\&\le\underset{i=1}{\overset{k}{\sum}}P(A_i)\\&\le\underset{i=1}{\overset{k}{\sum}}2exp(-2\gamma^2m)\\&=2k\,exp(-2\gamma^2m)\end{aligned})
也可以得到他的等价式:
-\hat{\varepsilon}(h_i)\right|>\gamma)&=P(\forall&space;h\in\mathcal&space;H&space;.&space;\left|\varepsilon(h_i)-\hat{\varepsilon}(h_i)\right|\le\gamma)\\&space;&\ge1-2k\,exp(-2\gamma^2m)&space;\end{aligned})
上式表示了假设集
内任意假设函数的训练误差和泛化误差的的接近程度小于一个常数
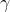
的概率有下界,并且随着样本量的增加,训练误差接近泛化误差的概率随之增大。上式的结果称为一致收敛。下面以此不等式引出个推论:
样本量下界:
以上的不等式有三个元素:样本量m,误差阈值
和概率,通过任意两个元素,可以确定第三个元素。例如,我们可以关心下列问题:如果给定
和
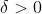
,我们需要多大的样本量才能保证训练误差和泛化误差相差不超过
的概率最小为
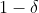
?令
)
可以解出m:

上面的不等式确定了一个m的下界,该下界称为算法的样本复杂度(algorithm’s sample complex),也就是说,如果我们想通过样本对总体有个较为准确的估计,我们需要采集最小的样本量是多少。
误差界限:
如果我们固定m和
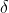
的值,求解
,可以得到:
-\varepsilon(h)|\le\sqrt{\frac{1}{2m}log\frac{2k}{\delta}})
假设一致收敛成立,那么对于所有
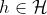
,有
-\hat{\varepsilon}(h)|\le&space;\gamma)
,那么,可以得到样本泛化误差和总体泛化误差的距离:
令
)
,
)
,即h*表示在集合
中使得泛化误差最小的那个假设函数。那么有:
&\le\hat{\varepsilon}(\hat{h})+\gamma\\&\le&space;\hat{\varepsilon}(h^*)+\gamma\\&\le\varepsilon(h^*)+2\gamma&space;\end{aligned})
上式第一行不等式依据的是
和
\le&space;\hat{\varepsilon}(h))
,不等式第二行是由
)
是对样本最小的误差的假设函数,因此小于
,第三行是根据不等式
。从不等式可以看出,对于
(即利用训练集得到的假设函数)的泛化误差在任何情况下也不会比最理想的泛化误差多
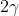
。结合前面的结论,我们可以得到定理1:
定理1:令
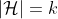
,且m和
值固定,在误差小于一个阈值的概率为至少为
的情形下,有:
\le(\underset{h\in\mathcal&space;H}{min}\varepsilon(h))+2\sqrt{\frac{1}{2m}log\frac{2k}{\delta}})
定理1给出了一个很重要的结论:如果我们扩充假设类集合的范围,即由原来的假设类
扩充为
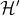
即
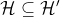
,则上式第一项(可以非正式的视其为偏差)的值会变小,因为扩充假设类集,可能有更好的假设函数使得最小泛化误差下降;第二项(可以非正式的视其为方差)的值会增大,因为k的值增加了。因此,如果假设类过小,则第一项过大,会造成欠拟合,通过扩充假设类
,可以使得第一项的值下降,但是第二项值上升,如果扩充过大,会造成过拟合,同样会增加泛化误差。因此要想得到最小的泛化误差,需要在选择合适的
,即在方差和偏差之间进行权衡。

假如固定
和
,去求解m,我们可以得到一条关于样本复杂度的推论:
推论1:令
,
和
为定值,再令
\le&space;min_{h\in&space;\mathcal&space;H}\varepsilon(h)+2\gamma)
的概率不低于
,那么样本量需满足:
)
4.无穷集
前一节我们介绍了在假设类集合是有穷集的情况下泛化误差、训练误差和样本量之间的关系。然而,存在很多以实数为参数的模型,假设类集合中元素数量是无穷的(如线性分类问题)。我们将如何处理?
下面以线性分类为例,假设分类的决策边界由线性函数表示,且该线性函数有d个实数参数。如果我们用计算机表示这些实数,根据IEEE双精度浮点数的标准,用64位二进制表示一个实数,那么,这d个实数需要用64d个2进制位表示,因此,这里假设类集合最多由

个元素构成。由推论1可得,如果需要保证
\le&space;\varepsilon(h^*)+2\gamma)
的概率不小于
,需满足
=O(\frac{d}{\gamma^2}log\frac{1}{\delta})=O_{\gamma,\delta}(d))
,因此可以看出,训练样本量和模型参数数量为线性关系。事实上,依赖64位浮点数无法得出准确的参数,然而,
如果我们尝试去最小化训练误差,也会得出理想的假设函数。
前文的结论是依赖于
的参数设置。如在线性分类器中

,此处有n+1个参数。如果这样定义分类器:
+(u_1^2-v_1^2)x_1+...+(u_n^2-v_n^2)x_n\})
,此时有2n+2个参数,但是这二者定义了相同的
:在n维空间的线性分类器。
最后通过引入VC维的概念,将误差理论推广到更加一般的情形:
VC维
给定一个集合;
},...,x^{(d)}\})
,
}\in\mathcal&space;X)
,这d个点可以用
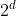
种方法正负样本。如果存在
可以将这
种标记的情况都能够有效分类,我们就称
可以散列(shatter)S。通过
集合中的某个假设函数h,可以对这个点构成的任何情况进行无误差的分类。将一个假设集能够无误差分类的最大的点的数量称为改假设集的VC维,记作
)
。
下面举例说明,假设有三个点如下图所示:

这三个样本点有23=8种分类可能,如果使用线性分类器对其进行分类,可以得到“零训练误差”,如下图所示:








然而,线性分类器最多对3个点构成的所有可能分类情况进行无误差分类。如果超过3个点线性分类器将无法进行分类。如下图所示:

这里的结论可能很悲观,线性分类器在二维平面上至多只能给3个点进行无误差的分类。(更一般的,k维线性分类器最多只能给k+1个点进行无误差分类。)然而,实际的应用中,并不需要构建一个模型使得对于训练集进行无误差的分类,甚至分类过于精确,会使得模型的泛化能力变得很弱,因此VC维仅仅是保证理论的严密,以及可以相关证明的前提条件,并不能完全做为分类算法准确程度的度量。
最后,介绍两个重要的定理:
定理2:令
为给定的假设集,且
)
,在概率不小于
的情况下,对于任意
,有:
-\hat{\varepsilon}(h)|\le&space;O(\sqrt{\frac{d}{m}log\frac{m}{d}+\frac{1}{m}log\frac{1}{\delta}}&space;))
同样有
\le\varepsilon(h^*)+O(\sqrt{\frac{d}{m}log\frac{m}{d}+\frac{1}{m}log\frac{1}{\delta}}&space;))
也就是说,如果一个假设集
,VC维是有限的,那么,随着m的增大,任意
的训练误差和泛化误差一致收敛。并且有如下推论:
推论2:假设
-\hat{\varepsilon}(h)|\le\gamma)
且对于所有
要确保其概率不低于
,需满足
)
。
推论2的含义是,如果需要确保训练误差和泛化误差的差值在一个给定的范围内,并且发生的概率不低于
,需要的样本数量和假设集的VC维大小呈线性相关。
5.总结
Andrew Ng的讲义给的标题是学习理论(LearningTheory),然而本文给出了训练误差和泛化误差的一般性定义;并介绍了ERM原则;证明了泛化误差和训练误差间差距、样本量和误差概率之间的关系;最后通过引入VC维,推出了更一般的情况下他们之间的关系。因此文章标题为误差理论。
http://blog.csdn.net/linkin1005/article/details/42563229
一、偏倚(bias)和方差(variance)
在讨论线性回归时,我们用一次线性函数
对训练样本进行拟合(如图1所示);然而,我们可以通过二次多项式函数对训练样本进行拟合(如图2所示),函数对样本的拟合程序看上去更“好”;当我们利用五次多项式函数对样本进行拟合(如图3所示),函数通过了所有样本,成为了一次“完美”的拟合。
图3建立的模型,在训练集中通过x可以很好的预测y,然而,我们却不能预期该模型能够很好的预测训练集外的数据。换句话说,这个模型没有很好的泛化能力。因此,模型的泛化误差(generalization error)不仅包括其在样本上的期望误差,还包括在训练集上的误差。
图1和图3中的模型都有较大的泛化误差,然而他们的误差原因却不相同。图1建立了一个线性模型,但是该模型并没有精确的捕捉到训练集数据的结构,我们称图1有较大的偏倚(bias),也称欠拟合;图3通过5次多项式函数很好的对样本进行了拟合,然而,如果将建立的模型进行泛化,并不能很好的对训练集之外数据进行预测,我们称图3有较大的,也称过拟合。
通常,在偏倚和方差之间,这样一种规律:如果模型过于简单,其具有大的偏倚,而如果模型过于复杂,它就有大的方差。调整模型的复杂度,建立适当的误差模型,就变得极其重要了。
二、预备知识
首先我们先介绍两个非常有用的引理:
引理1:一致限(the union bound)令
为k个不同的事件(不一定相互独立),那么有:
一致限说明:k个事件中任一个事件发生的概率小于等于这k个事件发生的概率和(等号成立的条件为这k个事件相两两互斥)。
引理2:Hoeffding 不等式(Hoeffding inequality)令
为m个独立同分布的随机变量,由参数为
的伯努利分布(即
)生成。令
,为这些随机变量的均值,对于任意
有:
在机器学习中,引理2称为Chernoff边界(Chernoff bound),它说明:假设我们用随机变量的均值
去估计参数
,估计的参数和实际参数的差超过一个特定数值的概率有一确定的上界,并且随着样本量m的增大,
与
很接近的概率也越来越大。
通过以上两个引理,我们能够引出机器学习中很重要结论。
为简单起见,我们只讨论二分类问题,即类标签为
。
假设给定的训练集为
,且各训练样本
独立同分布,皆为某个特定分布D生成。对于一个假设函数(hypothesis),定义训练误差(training
error)(也称为经验风险(empirical risk)或经验误差(empiriacal error))为:
训练误差为模型在训练样本中的错分类的比例,如果我们要强调
是依赖训练集的,也可以将其写作
。
我们再定义泛化误差(generalization error):
这里得到的是一个概率,表示通过特定的分布D生成的样本(x,y)中的y与通过预测函数h(x)生成的结果不同的概率。
注意,我们假设训练集的数据是通过某种分布D生成的,我们以此为依据来衡量假设函数。这里的假设有时称为PAC(probablyapproximately correct)假设。
在线性分类中,假设函数
中参数
如何得来?其中一个方法就是调整参数
,使得训练误差最小,即:
我们称这样的方法为经验风险最小化(empirical risk mininmization,ERM),其中
,基于ERM原则的算法可视作最基本的学习算法。线性回归和logistic回归都可以看作是遵守ERM的算法。
我们定义假设类集合
(hypothesis class)为所有假设函数的集合。例如线性分类问题中,
,其为所有的
(输入的定义域),对应的线性决策边界。
因此,ERM也可以认为是一组分类器的集合中,使得训练误差最小的那个分类器,即:
3.有穷集
我们定义假设类集合
由k个假设类(hypotheses)构成。其中,
为k个由
至{0,1}的映射函数构成,ERM从集合中k个元素选择
使得训练误差最小。
为了确保
和泛化误差的差值是有上界的,即如果训练误差很小,那么泛化误差也不会太大,我们需要完成两个步骤:首先,证明对于任意h,
是对
的可靠估计;其次,证明
存在上界。
我们令
,随机变量Z服从伯努利分布,样本由分布
生成:即:
。并且定义:
,即Z为指示变量,用来标记被假设函数
错误分类的样本。
泛化误差
定义为随机变量Z的期望,训练误差
为训练样本被假设函数误分类的比例,即:
利用Hoeffding不等式,可以得到:
从上式可以看出,对于特定的的
,当m很大时,训练误差和泛化误差很接近的概率很大。但是,我们不仅仅需要考察对于特定的
,训练误差和泛化误差的接近程度,而是需要验证对于所有的
不等式也成立。
现令
代表事件
,对于任意
,存在
,因此,由引理1可得:
也可以得到他的等价式:
上式表示了假设集
内任意假设函数的训练误差和泛化误差的的接近程度小于一个常数
的概率有下界,并且随着样本量的增加,训练误差接近泛化误差的概率随之增大。上式的结果称为一致收敛。下面以此不等式引出个推论:
样本量下界:
以上的不等式有三个元素:样本量m,误差阈值
和概率,通过任意两个元素,可以确定第三个元素。例如,我们可以关心下列问题:如果给定
和
,我们需要多大的样本量才能保证训练误差和泛化误差相差不超过
的概率最小为
?令
可以解出m:
上面的不等式确定了一个m的下界,该下界称为算法的样本复杂度(algorithm’s sample complex),也就是说,如果我们想通过样本对总体有个较为准确的估计,我们需要采集最小的样本量是多少。
误差界限:
如果我们固定m和
的值,求解
,可以得到:
假设一致收敛成立,那么对于所有
,有
,那么,可以得到样本泛化误差和总体泛化误差的距离:
令
,
,即h*表示在集合
中使得泛化误差最小的那个假设函数。那么有:
上式第一行不等式依据的是
和
,不等式第二行是由
是对样本最小的误差的假设函数,因此小于
,第三行是根据不等式
。从不等式可以看出,对于
(即利用训练集得到的假设函数)的泛化误差在任何情况下也不会比最理想的泛化误差多
。结合前面的结论,我们可以得到定理1:
定理1:令
,且m和
值固定,在误差小于一个阈值的概率为至少为
的情形下,有:
定理1给出了一个很重要的结论:如果我们扩充假设类集合的范围,即由原来的假设类
扩充为
即
,则上式第一项(可以非正式的视其为偏差)的值会变小,因为扩充假设类集,可能有更好的假设函数使得最小泛化误差下降;第二项(可以非正式的视其为方差)的值会增大,因为k的值增加了。因此,如果假设类过小,则第一项过大,会造成欠拟合,通过扩充假设类
,可以使得第一项的值下降,但是第二项值上升,如果扩充过大,会造成过拟合,同样会增加泛化误差。因此要想得到最小的泛化误差,需要在选择合适的
,即在方差和偏差之间进行权衡。
假如固定
和
,去求解m,我们可以得到一条关于样本复杂度的推论:
推论1:令
,
和
为定值,再令
的概率不低于
,那么样本量需满足:
4.无穷集
前一节我们介绍了在假设类集合是有穷集的情况下泛化误差、训练误差和样本量之间的关系。然而,存在很多以实数为参数的模型,假设类集合中元素数量是无穷的(如线性分类问题)。我们将如何处理?
下面以线性分类为例,假设分类的决策边界由线性函数表示,且该线性函数有d个实数参数。如果我们用计算机表示这些实数,根据IEEE双精度浮点数的标准,用64位二进制表示一个实数,那么,这d个实数需要用64d个2进制位表示,因此,这里假设类集合最多由
个元素构成。由推论1可得,如果需要保证
的概率不小于
,需满足
,因此可以看出,训练样本量和模型参数数量为线性关系。事实上,依赖64位浮点数无法得出准确的参数,然而,
如果我们尝试去最小化训练误差,也会得出理想的假设函数。
前文的结论是依赖于
的参数设置。如在线性分类器中
,此处有n+1个参数。如果这样定义分类器:
,此时有2n+2个参数,但是这二者定义了相同的
:在n维空间的线性分类器。
最后通过引入VC维的概念,将误差理论推广到更加一般的情形:
VC维
给定一个集合;
,
,这d个点可以用
种方法正负样本。如果存在
可以将这
种标记的情况都能够有效分类,我们就称
可以散列(shatter)S。通过
集合中的某个假设函数h,可以对这个点构成的任何情况进行无误差的分类。将一个假设集能够无误差分类的最大的点的数量称为改假设集的VC维,记作
。
下面举例说明,假设有三个点如下图所示:
这三个样本点有23=8种分类可能,如果使用线性分类器对其进行分类,可以得到“零训练误差”,如下图所示:
然而,线性分类器最多对3个点构成的所有可能分类情况进行无误差分类。如果超过3个点线性分类器将无法进行分类。如下图所示:
这里的结论可能很悲观,线性分类器在二维平面上至多只能给3个点进行无误差的分类。(更一般的,k维线性分类器最多只能给k+1个点进行无误差分类。)然而,实际的应用中,并不需要构建一个模型使得对于训练集进行无误差的分类,甚至分类过于精确,会使得模型的泛化能力变得很弱,因此VC维仅仅是保证理论的严密,以及可以相关证明的前提条件,并不能完全做为分类算法准确程度的度量。
最后,介绍两个重要的定理:
定理2:令
为给定的假设集,且
,在概率不小于
的情况下,对于任意
,有:
同样有
也就是说,如果一个假设集
,VC维是有限的,那么,随着m的增大,任意
的训练误差和泛化误差一致收敛。并且有如下推论:
推论2:假设
且对于所有
要确保其概率不低于
,需满足
。
推论2的含义是,如果需要确保训练误差和泛化误差的差值在一个给定的范围内,并且发生的概率不低于
,需要的样本数量和假设集的VC维大小呈线性相关。
5.总结
Andrew Ng的讲义给的标题是学习理论(LearningTheory),然而本文给出了训练误差和泛化误差的一般性定义;并介绍了ERM原则;证明了泛化误差和训练误差间差距、样本量和误差概率之间的关系;最后通过引入VC维,推出了更一般的情况下他们之间的关系。因此文章标题为误差理论。

相关文章推荐
- JFinal源码走读_3_ActiveRecord初始化
- spring 第一篇(1-1):让java开发变得更简单(上)
- [工作]Eclipse开发,JFace and SWT
- Ubuntu 上安装 LAMP 服务器
- Java 验证 身份证号码是否规范
- 关于SOCKET中send和recv函数工作原理总结
- 几个查看系统状态的工具简介
- 机器学习--因子分析
- IO-04 混合类型数据格式化输入(5)
- 解密Oracle备份工具-exp/imp 推荐
- MSSQL 创建约束
- Effective C++学习笔记
- 实体类中含集合或者map的json转换
- eclipse 快捷键
- Effective C++学习笔记 分类: C/C++ 2015-06-08 16:52 27人阅读 评论(0) 收藏
- linux如何安装jdk和配置TOMCAT
- git commit 合并
- Date:2015/06/08白天
- Oracle Study之--Oracle 11gR2 RAC crs启动故障
- 线程池原理及创建(C++实现)