关于c++内存的一点总结20150603
2015-06-03 06:01
489 查看
对C/C++内存的管理一直是比较敏感的知识点,这方面的知识涉及到和底层硬件直接打交道,我关键又学那么长一段时间硬件,对这块知识点理解的又不是那么全面,借这段时间空暇时间多,稍微的做个总结,以后如果有更加深刻的理解的在做补充,如果有理解偏差,也请大家指正
1:初步的了解c++对内存的分布
内存的空间,c++一共将这块空间分成了5个部分,就好比一个公司为了好管理,将公司分为5个部门一样,每个部门有专门的部门职能,c++也是为了更好的管理,诺大的内存空间c++根据自己的需求,将内存空间大致的分成五个部
4000
分:堆区、栈区、自由存储区、全局\静态存储区、常量存储区。根据划分的5个区的名字,已经大致的理解了这5个区的功能,具体的功能官方的解释有正规的解释,这里按照我的理解大致的解释一下,也欢迎大家指正
1、堆区:这个区间是程序员自己申请一些空间的地方,如果程序员自己申请了一节空间类型大小明确的空间,就会在这个区间里面,由于是自己申请的,这段空间用完后得自己释放,不释放的话程序结束操作系统会自动释放,所以堆区的空间自由度灵活点,一般我们特地的通过关键词new来申请这段空间,申请完之后通多delete来释放这段空间
2、栈区:这个区间是编译器根据程序员的行为,按照需要的时候临时的划分一块区间,不需要的时候编译器自动释放,不需要程序员来管控,这个区间一般存储的就是些变量(局部)、函数的参数等一些临时的变量
/*********************************************************************************************************************************
上面的堆栈是程序员论坛上经常见到的话题,我用一个简单的例子按照我的理解解释一下
#include<iostream>
using namespace std;
int main()
{
int a=12;
int b=15;
int *p=new int;
*p=15; //断点1
cout<<&a<<endl;
cout<<p<<endl;
p=&a; //断点2
cout<<&a<<endl;
cout<<p<<endl;
return 0; //断点3
}在程序的三个地方设置了三个断点
程序在vs2012的环境下,debug模式下调试运行
首先程序运行到断点1
看下a的地址,b的地址和指针p的地址


上面地址的位置:
a的地址:0x001EFDA8
b的地址:0x001EFD9C
*p的地址:0x001EFD90
p指针新建的地址:0x003B9E68
通过上面四个地址,我们可以这么理解,变量a、变量b、以及指针的存储地址&(*p)都是有编译器自动开辟空间存储的,开辟的这部分内存空间成为栈
而定义一个指针p开辟的新空间,也就是p指向的空间0x003B9E68这个空间叫做堆,它的内存空间是开发者在一块内存区域内开辟的一段空间,可以发现,这两块空间的地址是不连续的,由于debug模式下,造成a,b,变量之间有间隙,实际release模式下是不存在的,这里,我们也注意下各个空间内的值,注意观察下值的变化
然后我们接着将程序运行到断点2,程序主要的处理过程是给p指向的内存赋值15,这时候,p指向的内存地址的值应该变成0f 00 00 00编码才对,其他的地址应该没有变化,我们调出内存图验证一下
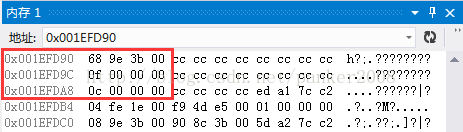
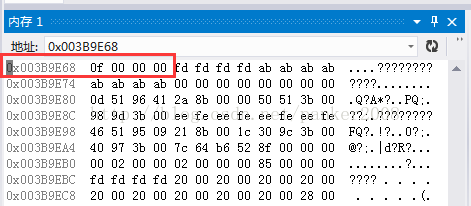
运行后发现和自己的预想一样
那么,如果运行到断点3内存变化会发生什么变化啊,这个我也不清楚,我也是猜的,先看下代码的处理过程
p=&a; //断点2
cout<<&a<<endl;
cout<<p<<endl;
return 0; //断点3
断点2到断点3代码将a的地址传递给了指针p,让指针p指向a的地址,照这个逻辑推理下去,按照很多人给我们的解释是,堆空间的地址必须得通过delete关键词来释放,如果不释放,他会一直占用,知道程序结束被操作系统回收,按照这个点,我做了下面的推断
如果到断点3,推断:
1、变量a,b的地址不会改变
2、a,b栈内的值也不会变化
3、p指针所在的内存地址也不会变化
4、但是p指针的值会变化,因为它指向的地址已经发生了变化
5、p原先指向的地址的值也不会变化,因为那个地址内的值我们没有做任何处理
我们还是让程序运行到断点3,查看内存的变化

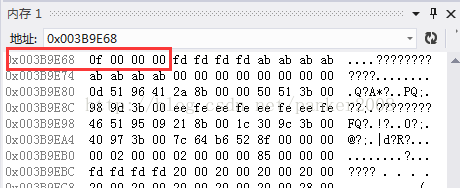
通过比较,我发现了p的值由原先的68 9e 3b 00 变成了a8 fd 1e 00,程序就是按照上面推断的5项的结论来的,推断是正确的,我们重新查看p指向的地址,则是变量a的地址了
通过三个断点发现一些其他的问题,这个我没有验证,只能在以后验证了,问题罗列一下
1:变量的入栈也叫压栈是从内存高位进入,先进后出的原则对么
2:程序的地址标记入栈的地址位低于先入栈的地址位
3:堆区的地址位是不是在内存分配上高于栈区的地址位,我发现p指向的堆区的地址位为0x003B9E68明显大于a的地址位0x001EFDA8
大致对堆栈的理解也只能总结这么多,大致的了解堆栈的区别
/*********************************************************************************************************************************
3、自由存储区:和堆的功能类似,不过它是通过malloc和free来分配和释放的
4、全局\静态存储区:它是存储全局变量和静态变量的一块内存区域
5、常量存储区:它是内存用来存放常量的一块区域,不允许更改其值
内存的5种方式都通过上述堆载的方法全部调试过,同样每个都会遗留或多或少的问题,等以后知识面深的话,在做详细的分析吧,这里只是总结一下关于内存分配的一方面的知识。
2:整体上了解的c++的大概的内存方式后,整体上已经清楚数据入堆栈的原理,现在从细节上分析上面的各个区间的区别,也是参考一些文献加上自己的理解,总结一下,忽的在别的文章上解决了上面的一些问题
由于这篇文字总结不是一天写成的,断断续续的写了几次,后期又发现了前期的一些错误,也不想去更改了,毕竟能把自己最初为什么是这样想的,当时为什么会卡到这个问题上的思维保留下来,等以后还有时间去总结了,就像总结c++一样似的,在来个更简单扼要的总结吧
堆和栈的区别:
a:管理方式的不同:栈是编译器管理,堆是程序员自己管的,人管就容易出错,比如内存泄露
b:空间大小不同:栈的空间比较小,多小多大编译器决定的,堆空间大,多大多小,程序员决定的,但是不能超过极限
c:碎片问题:堆每次开新空间都得申请,空间地址不连续,很容易碎片,栈不会,它是依次分配的
d:方向不同:堆是向内存地址增大的方向扩充,栈是像内存地址减小的地方扩充(解决了上面的第一个问题)
e:分配方式:堆只能动态分配,栈动静都能分配
f:执行效率:栈是编译器分配的,堆是库分配的,栈的速度明显快堆,但是对于数据空间较大的,还是用堆来解决
所以我个人截止目前我个人的理解是能用栈时候不用堆,当数据过于大的时候或者需要后期灵活调用的时候,我会比较它们的利弊,然后决定用那一个
1:初步的了解c++对内存的分布
内存的空间,c++一共将这块空间分成了5个部分,就好比一个公司为了好管理,将公司分为5个部门一样,每个部门有专门的部门职能,c++也是为了更好的管理,诺大的内存空间c++根据自己的需求,将内存空间大致的分成五个部
4000
分:堆区、栈区、自由存储区、全局\静态存储区、常量存储区。根据划分的5个区的名字,已经大致的理解了这5个区的功能,具体的功能官方的解释有正规的解释,这里按照我的理解大致的解释一下,也欢迎大家指正
1、堆区:这个区间是程序员自己申请一些空间的地方,如果程序员自己申请了一节空间类型大小明确的空间,就会在这个区间里面,由于是自己申请的,这段空间用完后得自己释放,不释放的话程序结束操作系统会自动释放,所以堆区的空间自由度灵活点,一般我们特地的通过关键词new来申请这段空间,申请完之后通多delete来释放这段空间
2、栈区:这个区间是编译器根据程序员的行为,按照需要的时候临时的划分一块区间,不需要的时候编译器自动释放,不需要程序员来管控,这个区间一般存储的就是些变量(局部)、函数的参数等一些临时的变量
/*********************************************************************************************************************************
上面的堆栈是程序员论坛上经常见到的话题,我用一个简单的例子按照我的理解解释一下
#include<iostream>
using namespace std;
int main()
{
int a=12;
int b=15;
int *p=new int;
*p=15; //断点1
cout<<&a<<endl;
cout<<p<<endl;
p=&a; //断点2
cout<<&a<<endl;
cout<<p<<endl;
return 0; //断点3
}在程序的三个地方设置了三个断点
程序在vs2012的环境下,debug模式下调试运行
首先程序运行到断点1
看下a的地址,b的地址和指针p的地址
上面地址的位置:
a的地址:0x001EFDA8
b的地址:0x001EFD9C
*p的地址:0x001EFD90
p指针新建的地址:0x003B9E68
通过上面四个地址,我们可以这么理解,变量a、变量b、以及指针的存储地址&(*p)都是有编译器自动开辟空间存储的,开辟的这部分内存空间成为栈
而定义一个指针p开辟的新空间,也就是p指向的空间0x003B9E68这个空间叫做堆,它的内存空间是开发者在一块内存区域内开辟的一段空间,可以发现,这两块空间的地址是不连续的,由于debug模式下,造成a,b,变量之间有间隙,实际release模式下是不存在的,这里,我们也注意下各个空间内的值,注意观察下值的变化
然后我们接着将程序运行到断点2,程序主要的处理过程是给p指向的内存赋值15,这时候,p指向的内存地址的值应该变成0f 00 00 00编码才对,其他的地址应该没有变化,我们调出内存图验证一下
运行后发现和自己的预想一样
那么,如果运行到断点3内存变化会发生什么变化啊,这个我也不清楚,我也是猜的,先看下代码的处理过程
p=&a; //断点2
cout<<&a<<endl;
cout<<p<<endl;
return 0; //断点3
断点2到断点3代码将a的地址传递给了指针p,让指针p指向a的地址,照这个逻辑推理下去,按照很多人给我们的解释是,堆空间的地址必须得通过delete关键词来释放,如果不释放,他会一直占用,知道程序结束被操作系统回收,按照这个点,我做了下面的推断
如果到断点3,推断:
1、变量a,b的地址不会改变
2、a,b栈内的值也不会变化
3、p指针所在的内存地址也不会变化
4、但是p指针的值会变化,因为它指向的地址已经发生了变化
5、p原先指向的地址的值也不会变化,因为那个地址内的值我们没有做任何处理
我们还是让程序运行到断点3,查看内存的变化
通过比较,我发现了p的值由原先的68 9e 3b 00 变成了a8 fd 1e 00,程序就是按照上面推断的5项的结论来的,推断是正确的,我们重新查看p指向的地址,则是变量a的地址了
通过三个断点发现一些其他的问题,这个我没有验证,只能在以后验证了,问题罗列一下
1:变量的入栈也叫压栈是从内存高位进入,先进后出的原则对么
2:程序的地址标记入栈的地址位低于先入栈的地址位
3:堆区的地址位是不是在内存分配上高于栈区的地址位,我发现p指向的堆区的地址位为0x003B9E68明显大于a的地址位0x001EFDA8
大致对堆栈的理解也只能总结这么多,大致的了解堆栈的区别
/*********************************************************************************************************************************
3、自由存储区:和堆的功能类似,不过它是通过malloc和free来分配和释放的
4、全局\静态存储区:它是存储全局变量和静态变量的一块内存区域
5、常量存储区:它是内存用来存放常量的一块区域,不允许更改其值
内存的5种方式都通过上述堆载的方法全部调试过,同样每个都会遗留或多或少的问题,等以后知识面深的话,在做详细的分析吧,这里只是总结一下关于内存分配的一方面的知识。
2:整体上了解的c++的大概的内存方式后,整体上已经清楚数据入堆栈的原理,现在从细节上分析上面的各个区间的区别,也是参考一些文献加上自己的理解,总结一下,忽的在别的文章上解决了上面的一些问题
由于这篇文字总结不是一天写成的,断断续续的写了几次,后期又发现了前期的一些错误,也不想去更改了,毕竟能把自己最初为什么是这样想的,当时为什么会卡到这个问题上的思维保留下来,等以后还有时间去总结了,就像总结c++一样似的,在来个更简单扼要的总结吧
堆和栈的区别:
a:管理方式的不同:栈是编译器管理,堆是程序员自己管的,人管就容易出错,比如内存泄露
b:空间大小不同:栈的空间比较小,多小多大编译器决定的,堆空间大,多大多小,程序员决定的,但是不能超过极限
c:碎片问题:堆每次开新空间都得申请,空间地址不连续,很容易碎片,栈不会,它是依次分配的
d:方向不同:堆是向内存地址增大的方向扩充,栈是像内存地址减小的地方扩充(解决了上面的第一个问题)
e:分配方式:堆只能动态分配,栈动静都能分配
f:执行效率:栈是编译器分配的,堆是库分配的,栈的速度明显快堆,但是对于数据空间较大的,还是用堆来解决
所以我个人截止目前我个人的理解是能用栈时候不用堆,当数据过于大的时候或者需要后期灵活调用的时候,我会比较它们的利弊,然后决定用那一个

相关文章推荐
- IE7降低内存和降低CPU的几个技巧
- 如何高效的使用内存
- DOS下内存的配置
- XP/win2003下发现1G的内存比512M还慢的解决方法
- PowerShell实现动态获取当前脚本运行时消耗的内存
- C#实现把dgv里的数据完整的复制到一张内存表的方法
- C语言内存对齐实例详解
- C++基于栈实现铁轨问题
- C语言栈的表示与实现实例详解
- C语言实现颠倒栈的方法
- 全局变量与局部变量在内存中的区别详细解析
- 算法系列15天速成 第十天 栈
- VB读取线程、句柄及写入内存的API代码实例
- php运行提示:Fatal error Allowed memory size内存不足的解决方法
- IE浏览器IFrame对象内存不释放问题解决方法
- 一看就懂:图解C#中的值类型、引用类型、栈、堆、ref、out
- C#之CLR内存深入分析
- Array栈方法和队列方法的特点说明
- JavaScript 变量、作用域及内存