Python包RLPY初识(一)
2015-06-03 00:17
288 查看
第一次发博客有点小紧张 _(:зゝ∠)_
(本文将简单介绍一下Python包RLPY)
下面先给出链接:该网站可查看RLPY架包的文档说明
安装RLPY可选择直接使用pip安装工具:pip install -U rlpy
MACOS:xcode-select –install
另外还可以下载源码后执行python setup.py install安装。
过程中可能需要另外一些Python架包的支持,可以戳这里Anaconda,里面包含了许多Python科学计算的架包,除了Python包之外还需要TK,安装完Anaconda之后可以直接运行conda install tk安装。
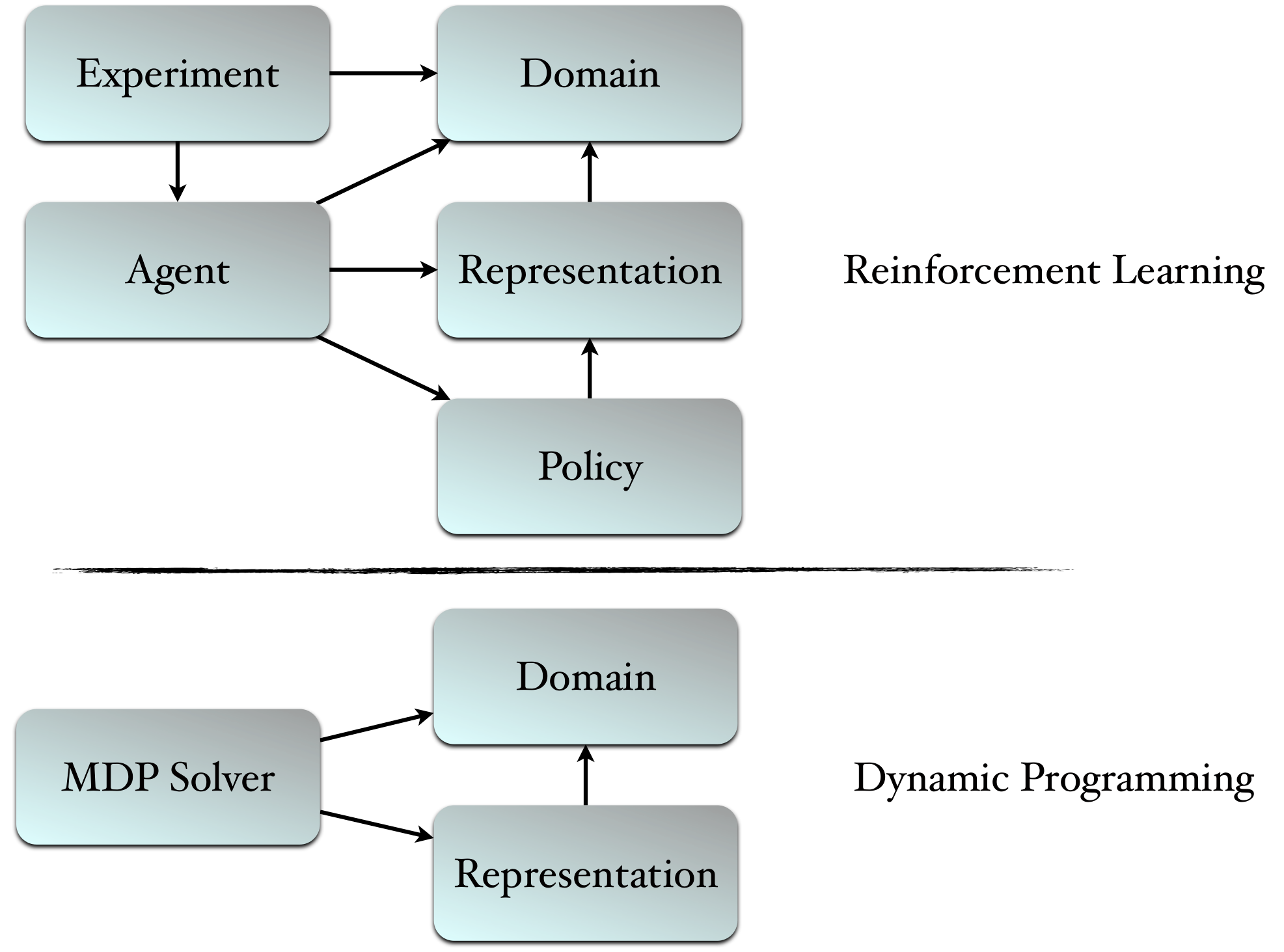
主要有两种方法,一种是使用Reinforcement Learning进行实验。如果环境完全已知,可以构建一个马尔可夫决策过程模型,则可使用动态规划来解决问题。
如果环境未知,可以使用强化学习的其他方法,将会用到上半张图中4个基础类,具体实现继承这4个类并实现类中方法即可。
[b]我们分别来看一下这四个基础类的作用:[/b]
Agent: 是学习过程发生的地方,通过agent将从Domain中观察到的信息按需传递给representation和policy类。
Policy: 决定在当前状态下agent要采取的行动(离散的),决策机制通常基于估计的值函数。
Representation:用来建立agent的关于Domain的一个值函数模型。agent通过与Domain交互获得一些状态更新,再将信息传递给representation类,representation类需要更新值函数,同时还要维持特征空间在一个较低的维度。agent可以向representation类询问当前状态下的V(s)值以及Q(s,a)值(V:代表s状态下的值,Q:代表s状态下采取a行动的值)
Domain: 是agent需要做出决策的场所(一个场景),即我们需要解决的MDP问题。
最后experiment类是用来驱动整个实验进行的,用来配置上面4个类,联系4个类,还可以对当前策略进行评估。
下一章我将介绍RLPY包自带的Gridworld例子。
如果有什么写的不好或者不对的地方大家可以尽量提出,感激不尽。
(本文将简单介绍一下Python包RLPY)
下面先给出链接:该网站可查看RLPY架包的文档说明
安装RLPY可选择直接使用pip安装工具:pip install -U rlpy
MACOS:xcode-select –install
另外还可以下载源码后执行python setup.py install安装。
过程中可能需要另外一些Python架包的支持,可以戳这里Anaconda,里面包含了许多Python科学计算的架包,除了Python包之外还需要TK,安装完Anaconda之后可以直接运行conda install tk安装。
RLPY是用来干什么的
RLPY是用python所编写的代码框架,可用来进行基于值函数过程的连续决策实验。主要是用来进行基于reinforcement learning(强化学习)的实验。话不多说先上主要类图主要有两种方法,一种是使用Reinforcement Learning进行实验。如果环境完全已知,可以构建一个马尔可夫决策过程模型,则可使用动态规划来解决问题。
如果环境未知,可以使用强化学习的其他方法,将会用到上半张图中4个基础类,具体实现继承这4个类并实现类中方法即可。
[b]我们分别来看一下这四个基础类的作用:[/b]
Agent: 是学习过程发生的地方,通过agent将从Domain中观察到的信息按需传递给representation和policy类。
Policy: 决定在当前状态下agent要采取的行动(离散的),决策机制通常基于估计的值函数。
Representation:用来建立agent的关于Domain的一个值函数模型。agent通过与Domain交互获得一些状态更新,再将信息传递给representation类,representation类需要更新值函数,同时还要维持特征空间在一个较低的维度。agent可以向representation类询问当前状态下的V(s)值以及Q(s,a)值(V:代表s状态下的值,Q:代表s状态下采取a行动的值)
Domain: 是agent需要做出决策的场所(一个场景),即我们需要解决的MDP问题。
最后experiment类是用来驱动整个实验进行的,用来配置上面4个类,联系4个类,还可以对当前策略进行评估。
下一章我将介绍RLPY包自带的Gridworld例子。
如果有什么写的不好或者不对的地方大家可以尽量提出,感激不尽。

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- Python 七步捉虫法
- Python实现的基于ADB的Android远程工具