Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
2015-05-28 20:44
821 查看
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程
上述安装教程已实践,可行。(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所以没有在Ubuntu上装,至于如何在Ubuntu上安装Scrapy,网上有挺多教程的)
Scrapy的入门教程见下面链接:Scrapy入门教程
上面的入门教程是很基础的,先跟着作者走一遍,要动起来哟,不要只是阅读上面的那篇入门教程。
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
douban_spider.py
代码有了,我来一步步讲解哈。
前言:我要爬的是豆瓣的数据,我有了很多电影的名字,但是我需要电影的详情,我用了一下豆瓣电影的网站,发现当我在搜索框里输入“Last Days in Vietnam”时url会变成http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam&cat=1002 然后我就试着直接输入http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam这个url,搜索结果是一样的,很显然这就是get方式,这样我们就找到了规律:http://movie.douban.com/subject_search?search_text=后面加上我们的电影名字并用加号分割就行了。
我们的电影名字(大量的电影名字)是存在movie_name.txt这个文件中里面的(一行一个电影名字):
我们可以先用python脚本(shell脚本也行)将电影名之间的空格处理为+,也可以在爬虫中读取电影名后进行一次replace处理(我是先处理成+的)。爬虫读取电影名字文件,然后构建url,然后就根据得到的网页找到搜索到的第一个电影的url(其实第一个电影未必一定是我们要的,但是这种情况是少数,我们暂时不理会它),得到第一个电影的url后,再继续爬,这次爬到的页面就含有我们想要的电影信息,需要使用XPath来获得html文件中元素节点,最后将获得的信息存到TutorialItem中,通过pipelines写入到data.dat文件中。
XPath的教程在这里:w3school的基础教程和scrapy官网上的Xpath 这些东西【入门教程】中都有说。
1、start_requests方法:
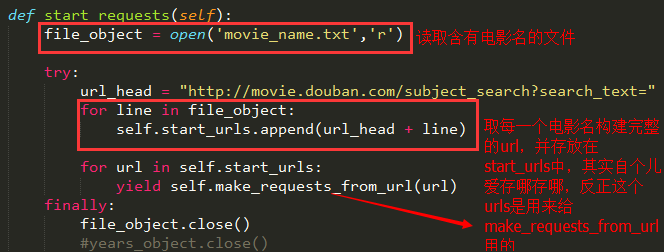
在【入门教程】那篇文章中没有用到这个方法,而是直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,首先我们看看start_requests这个方法是干嘛的:

可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
start_requests官方解释在这里
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接:
2、parse方法:
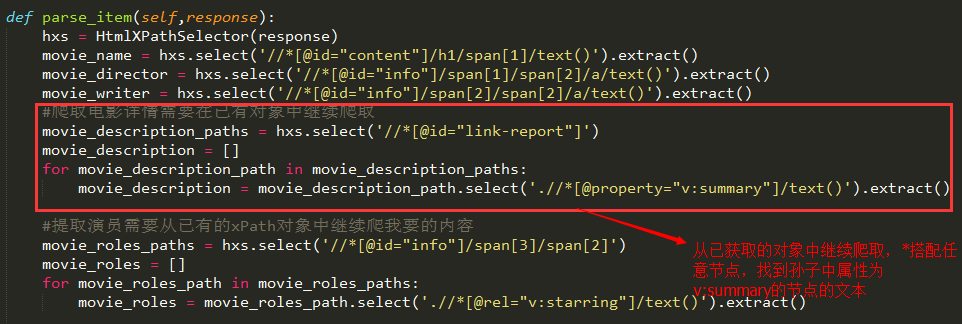
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法:

parse_item是我们自定义的方法,用来处理新连接的request后获得的response:
递归爬虫的方法这里和这里有。
好了,结束了,这里还有一篇Scrapy的提高篇,有兴趣的去看看吧。
写写博客是为了记录一下自己实践的过程,也希望能对需要者有用吧!
上述安装教程已实践,可行。(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所以没有在Ubuntu上装,至于如何在Ubuntu上安装Scrapy,网上有挺多教程的)
Scrapy的入门教程见下面链接:Scrapy入门教程
上面的入门教程是很基础的,先跟着作者走一遍,要动起来哟,不要只是阅读上面的那篇入门教程。
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
#coding=utf-8
import sys
reload(sys)
#python默认环境编码时ascii
sys.setdefaultencoding("utf-8")
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.selector import HtmlXPathSelector
from tutorial.items import TutorialItem
import re
class DoubanSpider(BaseSpider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = []
def start_requests(self):
file_object = open('movie_name.txt','r')
try:
url_head = "http://movie.douban.com/subject_search?search_text="
for line in file_object:
self.start_urls.append(url_head + line)
for url in self.start_urls:
yield self.make_requests_from_url(url)
finally:
file_object.close()
#years_object.close()
def parse(self, response):
#open("test.html",'wb').write(response.body)
hxs = HtmlXPathSelector(response)
#movie_name = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@title').extract()
movie_link = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[1]/a/@href').extract()
#movie_desc = hxs.select('//*[@id="content"]/div/div[1]/div[2]/table[1]/tr/td[2]/div/p/text()').extract()
if movie_link:
yield Request(movie_link[0],callback=self.parse_item)
def parse_item(self,response):
hxs = HtmlXPathSelector(response)
movie_name = hxs.select('//*[@id="content"]/h1/span[1]/text()').extract()
movie_director = hxs.select('//*[@id="info"]/span[1]/span[2]/a/text()').extract()
movie_writer = hxs.select('//*[@id="info"]/span[2]/span[2]/a/text()').extract()
#爬取电影详情需要在已有对象中继续爬取
movie_description_paths = hxs.select('//*[@id="link-report"]')
movie_description = []
for movie_description_path in movie_description_paths:
movie_description = movie_description_path.select('.//*[@property="v:summary"]/text()').extract()
#提取演员需要从已有的xPath对象中继续爬我要的内容
movie_roles_paths = hxs.select('//*[@id="info"]/span[3]/span[2]')
movie_roles = []
for movie_roles_path in movie_roles_paths:
movie_roles = movie_roles_path.select('.//*[@rel="v:starring"]/text()').extract()
#获取电影详细信息序列
movie_detail = hxs.select('//*[@id="info"]').extract()
item = TutorialItem()
item['movie_name'] = ''.join(movie_name).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
#item['movie_link'] = movie_link[0]
item['movie_director'] = movie_director[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_director) > 0 else ''
#由于逗号是拿来分割电影所有信息的,所以需要处理逗号;引号也要处理,否则插入数据库会有问题
item['movie_description'] = movie_description[0].strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';') if len(movie_description) > 0 else ''
item['movie_writer'] = ';'.join(movie_writer).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
item['movie_roles'] = ';'.join(movie_roles).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
#item['movie_language'] = movie_language[0].strip() if len(movie_language) > 0 else ''
#item['movie_date'] = ''.join(movie_date).strip()
#item['movie_long'] = ''.join(movie_long).strip()
#电影详情信息字符串
movie_detail_str = ''.join(movie_detail).strip()
#print movie_detail_str
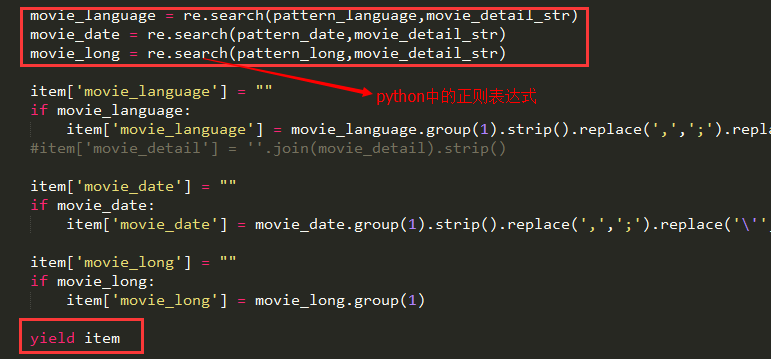
movie_language_str = ".*语言:</span> (.+?)<br><span.*".decode("utf8")
movie_date_str = ".*上映日期:</span> <span property=\"v:initialReleaseDate\" content=\"(\S+?)\">(\S+?)</span>.*".decode("utf8")
movie_long_str = ".*片长:</span> <span property=\"v:runtime\" content=\"(\d+).*".decode("utf8")
pattern_language =re.compile(movie_language_str,re.S)
pattern_date = re.compile(movie_date_str,re.S)
pattern_long = re.compile(movie_long_str,re.S)
movie_language = re.search(pattern_language,movie_detail_str)
movie_date = re.search(pattern_date,movie_detail_str)
movie_long = re.search(pattern_long,movie_detail_str)
item['movie_language'] = ""
if movie_language:
item['movie_language'] = movie_language.group(1).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
#item['movie_detail'] = ''.join(movie_detail).strip()
item['movie_date'] = ""
if movie_date:
item['movie_date'] = movie_date.group(1).strip().replace(',',';').replace('\'','\\\'').replace('\"','\\\"').replace(':',';')
item['movie_long'] = ""
if movie_long:
item['movie_long'] = movie_long.group(1)
yield itemdouban_spider.py
代码有了,我来一步步讲解哈。
前言:我要爬的是豆瓣的数据,我有了很多电影的名字,但是我需要电影的详情,我用了一下豆瓣电影的网站,发现当我在搜索框里输入“Last Days in Vietnam”时url会变成http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam&cat=1002 然后我就试着直接输入http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam这个url,搜索结果是一样的,很显然这就是get方式,这样我们就找到了规律:http://movie.douban.com/subject_search?search_text=后面加上我们的电影名字并用加号分割就行了。
我们的电影名字(大量的电影名字)是存在movie_name.txt这个文件中里面的(一行一个电影名字):
我们可以先用python脚本(shell脚本也行)将电影名之间的空格处理为+,也可以在爬虫中读取电影名后进行一次replace处理(我是先处理成+的)。爬虫读取电影名字文件,然后构建url,然后就根据得到的网页找到搜索到的第一个电影的url(其实第一个电影未必一定是我们要的,但是这种情况是少数,我们暂时不理会它),得到第一个电影的url后,再继续爬,这次爬到的页面就含有我们想要的电影信息,需要使用XPath来获得html文件中元素节点,最后将获得的信息存到TutorialItem中,通过pipelines写入到data.dat文件中。
XPath的教程在这里:w3school的基础教程和scrapy官网上的Xpath 这些东西【入门教程】中都有说。
1、start_requests方法:
在【入门教程】那篇文章中没有用到这个方法,而是直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,首先我们看看start_requests这个方法是干嘛的:
可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
start_requests官方解释在这里
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接:
2、parse方法:
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法:
parse_item是我们自定义的方法,用来处理新连接的request后获得的response:
递归爬虫的方法这里和这里有。
HtmlXPathSelector的解释在这里
为了获得我想要的数据我也是蛮拼的,由于豆瓣电影详情的节点是没太大规律了,我后面还用了正则表达式去获取我要的内容,具体看上面的代码中parse_item这个方法吧:好了,结束了,这里还有一篇Scrapy的提高篇,有兴趣的去看看吧。
写写博客是为了记录一下自己实践的过程,也希望能对需要者有用吧!

相关文章推荐
- fzu2153 A simple geometric problems
- 【数据结构】双循环链表(c++)
- Python学习_13_继承和元类
- [转]C# winform与Javascript的相互调用
- 提高第37课时,自测
- MVC简介
- RHCS图形界面建立GFS共享中
- Cookie小案例
- virgo虚拟桌面
- win7重定向函数引发的问题
- 使用Xcode和Instruments调试解决iOS内存泄露
- UAC提升权限的细节
- destoon去掉版权
- SPA(Single-page application) 单页应用
- (转)几个常用的操作系统进程调度算法
- Netty那点事(二)Netty中的buffer
- 客运综合管理系统项目解析-检票管理-检票
- Servlet自学第27讲:Session与Cookie对比总结
- 明源售楼系统技术解析—诚意认购(一)
- HDU 2222 Keywords Search (AC自动机)