git plumbing 更加底层命令解析-深入理解GIT
2015-05-25 15:25
531 查看
原文: http://rypress.com/tutorials/git/plumbing
本文详细介绍GIT Plumbing--更加底层的git命令,你将会对git在内部是如何管理和呈现一个项目repo有一个深入的理解。
除非你想通读Git源代码,你可能永远没有必要使用下面的命令。但是通过手工的操作一个repo将会让你对于GIT如何保存数据的概念细节有个深入理解,你也将对于git是如何工作的有更好的理解。
我们首先来检阅Git的object database,然后我们使用git的低级命令手工创建和commit一个snapshot
commit参数告诉git我们需要查看一个commit对象。正如我们所知,HEAD指向最近的commit.这将输出下面的信息:
这是代表一个commit的完整信息:一个tree,一个parent,用户数据和一个commit message.用户信息和commit消息是非常容易理解的,但我们从来没有见过tree或者parent.
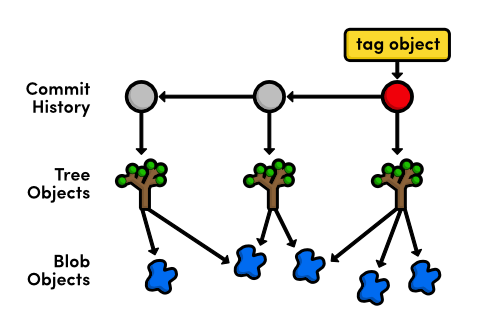
一个tree object是git对于一个"snapshot"的代表。他们保存了一个目录在特定时刻的状态,该object没有任何关于时间或者作者的信息。为了将tree和项目一贯的历史信息关联起来,GIT将每一个tree对象包装在一个commit对象中,并且指定一个parent,而这个parent实际上就是另外一个commit.通过遍历每一个commit的parent,你就可以遍历完项目的整个历史。
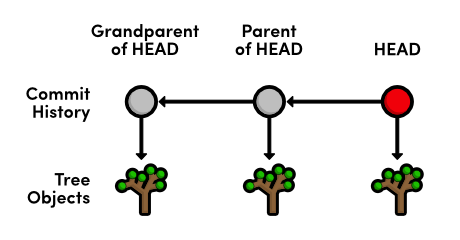
注意每一个commit refers to one and only one tree object,也就是说commit和tree是一一对应的。从git cat-file输出的内容看,我们可以使用SHA checksum来代表那个tree.这个SHA CHECKSUM对于GIT内部每一个变量都是适用的。
不幸的是上述命令输出的是binary数据,无法阅读。你可以通过使用下面的git ls-tree命令来输出可阅读的内容。
该命令将输出目录的列表:
通过检查上面命令的输出内容,我们可以假定"blobs"代表了我们repo里面的文件,而trees代表了repo里面的folders。继续通过git ls-tree检阅about tree,我们就可以看到是不是我们的假定是正确的了。
所以,blob对象实际上就是git保存我们文件内容的对象,可以简单理解为文件,tree对象组合了blob和其他的tree对象形成了目录列表,也就是说tree可以简单理解为目录。这些对象就是git最终形成我们在git中常用命令所操作的唯一对象。commit,tree,blob之间的关系可以用下面的图形象展示:
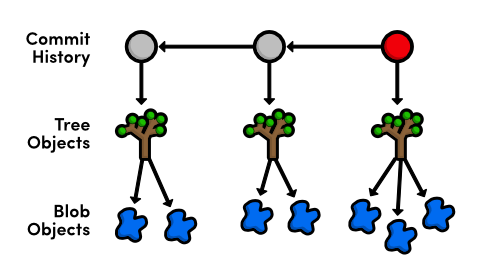
这会展示blue.html文件的整个内容,这也印证了blob本身就是存数据文件,blob本身是纯粹的content,它本身甚至没有任何关于文件名称的信息。也就是说文件名blue.html是保存在包含blob的tree对象中,而不是在blob对象中。
你可能知道SHA-1 checksum确保一个对象的内容永远不会在Git不知情的情况下被篡改。checksum的原理是通过使用对象内容来计算一个唯一的字符序列。这不仅作为一个id,而且它保证一个对象永远不会悄无声息地被修改(而git竟然不知情).当我们来谈到blob对象时,这又有另外一个好处。既然两个具有相同内容的blob永远具有相同的checksum id,那么git可以跨tree来共享一个blob对象。比如我们的blue.html文件自从被创建后就没有被修改,那么我们的repo将只有一个相关联的blob,而所有后续的tree对象都将引用它。通过不去创建重复的blob,Git可以大大降低repo的尺寸。有这个理念作为基础,我们可以修正git的对象图如下:
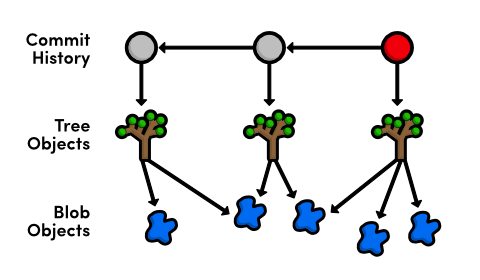
然而,只要你更改文件的任何一行,Git都必需创建一个新的blob对象来反映这个修改,因为内容变更,SHA-1 checksum就将变更。当然,GIT也有一些增量修改的机制来保证这个尺寸增加不是很大的问题。
上面的命令将输出和v2.0这个tag相关的commitID,以及tag的名称,作者,创建时间和附加信息。下面更新最后版本的git对象图:
一个branch就是一个对一个commit对象的引用,这意味着我们可以通过git cat-file commit master来查看master branch的详细信息。master branch和HEAD都是对一个commit对象的简单引用。
我们打开.git/refs/heads/master文件,你可以看到该文件内容实际上就是最近的一个commit的checksumID(你可以通过git log -n 1来检查这个commitid)。这个文件就是git为了维护master分支所需的一切,所有其他的信息都是通过这个commit object根据上面讨论的关系图来外推得出的!(branch本身是否就等于branch tip呢??)
另一方面,HEAD reference本身记录在.git/HEAD文件中,不像branch tips总是指向一个branch的顶端commit,
HEAD并不是任何一个commit的直接链接。反而,HEAD总是引用一个branch,GIT使用这个branch来指出当前checkout出来的是哪一个commit。记住一个detached HEAD state是在当HEAD不再和branch的tip相一致时发生的!从机理上说,这意味着.git/HEAD并没有一个Local branch。试着checkout一个老的commit:
现在,.git/HEAD就包含一个commitID,而不再是一个branch。这告诉git我们进入了一个dtached HEAD state。无论你在什么状态,git checkout命令将总是将checkedout commit的引用记录在.git/HEAD中。我们继续git checkout master,返回master branch,来接着做一些其他的实验:
每一个对象,无论对象的类型是什么,都被保存为一个文件,使用他的SHA-1 checksum作为文件名。但是,和传统将所有objects存放在一个文件夹的做法不同的是:他们通过将他们的ID前两个字符剔出来作为一个目录名,而id剩下的字符作为文件名。具体可以看看下面的objects输出目录格式:
比如,一个具有如下ID的object,
将会被保存在7a 文件架中,而剩下的(52bb8...)作为文件名,也就是说7a目录+52bb8...文件的组合来唯一标识该object
这样做的好处是检索迅速。知道了这一层,那么我们就可以重新组合出来我们的objectID,以便方便地查阅它的内容,
上面这条命令将会压缩各个object files形成更快更小的pack file并且删除一些不再引用的commit(比如frrom a deleted, unmerged branch)。
当然,所有相同objectID的都将可用git cat-file来访问。该git gc命令只是更改git的存储机制--而不是更改repo的内容。
在my-git-repo中创建一个新的文件,命名为news-4.html,并且增加一些html代码;然后修改Index.html文件的news section以便生成一个指向news-4.html的链接。
这时,正常情况下,我们将git add, git commit提交我们的变更。现在我们来试图使用更加低级的命令来手工完成这个操作。index是git的术语,代表了staged snapshot。
后面的命令将会抛出一个错误,因为git在你不明显告诉他news-4.html是一个新文件时,他是不允许加入他不知道的文件到stage area的。相反地,我们少做修改,增加--add参数:
我们通过上面的update-index命令将我们的working directory搬到了Index区,这意味着我们已经有了一个准备好的snapshot了,剩下来要做的事情就是commit了。
这个命令从index创建一个tree object并且保存在.git/objects目录中。它将输出这个命令结果的tree的checksumid:
你可以通过git ls-tree来检查你的新创的snapshot。记住这个commit中唯一新创的blob是index.html和news-4.html,这个tree的剩余内容引用了已经存在的blobs
所以,我们已经有了我们的tree object了,但是我们必需将他放到我们项目的历史中去。
git log --oneline -n 1
这条命令将输出下面的内容,我们将使用这个commitID来指定新的commit对象的parent
git commit-tree命令创建一个commit object根据传入的tree和parentID参数,但是author信息却是从git的一个环境变量来读取的。
这条命令将需要更多的输入: commit message.就像我们在做commit时要求输入commit message一样操作就可以了。
该命令最终输出
现在你就可以在.git/objects目录下查看到这个commit了,但是无论是HEAD或者是branches都没有被自动更新而包含这个commit. 现在这就是一个dangling commit。好消息是,我们知道git在哪里保存branch信息的:

如果这个文件根本不存在,也不用烦恼,这仅仅意味着git gc命令packed up all of our branch references into single file.在这种情况下,我们无法来更新。git/refs/heads/master,但是我们应该打开.git/packed-refs,找到独一refs/heads/master的引用的那行,修改即可。
既然我们的master branch指向了新的ecommit,我们应该可以在项目历史中看到news-4.html文件了。
git log -n 2
上面的章节我们解释了当我们执行git commit -a -m "some message"时所有发送在背后的真实事情。你是否觉得还是不用超低级命令的好呢?

Git directory是Git用于保存其metadata和objects的地方所在。这个目录是git最重要的部分,这个也是当你clone一个repo时copy的部分。working directory是你的项目的一个版本的checkout.这些文件是从git directory的compress database中抽取出来的,并且将这些内容放到磁盘中供你来修改和使用。
staging area就是一个文件,通常就放在.git目录中,这个文件保存了关于下一个commit的所有信息。有时我们又称之为index,但是更多的情况下,人们称之为staging area. 基本的GIT workflow像下面这个样子:
1.你在working directory中修改文件;
2.你stage这些修改,adding snapshots of them to your staging area;
3.你做一个commit,这个动作将把stage区中的snapshot永远存储于git directory的repo数据库中。
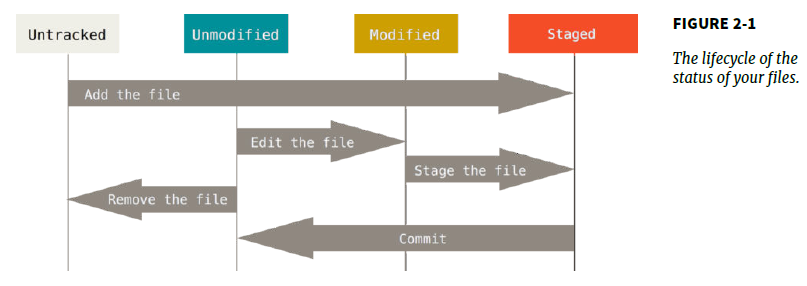
如果一个文件在Git directory中存在了,那么就被认为被commited了。如果文件modified,并且已经放到staging area了,那么成为it is staged.如果自从该文件被checkout出来后做了修改,但是却还没有staged,那么他就是modified状态。
.git/index这个文件实际上就是staging area,它会实时记录你准备放到下一个commit的snapshot,我们可以用ls-files来检查他的内容(他是binary文件)
git ls-files --stage
由于我们已经修改了readme.txt文件并且放到staging area,那么这时我们来检视这个文件的话,
git cat-file -t 41d9b4 一定输出blob
你可以看到最后一行就是最新的更改,但是上述命令却将整个readme.txt文件都作为blob来输出了@
本文详细介绍GIT Plumbing--更加底层的git命令,你将会对git在内部是如何管理和呈现一个项目repo有一个深入的理解。
除非你想通读Git源代码,你可能永远没有必要使用下面的命令。但是通过手工的操作一个repo将会让你对于GIT如何保存数据的概念细节有个深入理解,你也将对于git是如何工作的有更好的理解。
我们首先来检阅Git的object database,然后我们使用git的低级命令手工创建和commit一个snapshot
Examine Commit Details
首先我们通过git cat-file plumbing command来查看最近的一个commit:git cat-file commit HEAD
commit参数告诉git我们需要查看一个commit对象。正如我们所知,HEAD指向最近的commit.这将输出下面的信息:
tree 552acd444696ccb1c3afe68a55ae8b20ece2b0e6 parent 6a1d380780a83ef5f49523777c5e8d801b7b9ba2 author Ryan <ryan.example@rypress.com> 1326496982 -0600 committer Ryan <ryan.example@rypress.com> 1326496982 -0600 Add .gitignore file
这是代表一个commit的完整信息:一个tree,一个parent,用户数据和一个commit message.用户信息和commit消息是非常容易理解的,但我们从来没有见过tree或者parent.
一个tree object是git对于一个"snapshot"的代表。他们保存了一个目录在特定时刻的状态,该object没有任何关于时间或者作者的信息。为了将tree和项目一贯的历史信息关联起来,GIT将每一个tree对象包装在一个commit对象中,并且指定一个parent,而这个parent实际上就是另外一个commit.通过遍历每一个commit的parent,你就可以遍历完项目的整个历史。
注意每一个commit refers to one and only one tree object,也就是说commit和tree是一一对应的。从git cat-file输出的内容看,我们可以使用SHA checksum来代表那个tree.这个SHA CHECKSUM对于GIT内部每一个变量都是适用的。
Examine a Tree
下面我们使用git cat-file命令来检阅一个TREE对象。注意将相关的id更新为你的tree的id:git cat-file tree 552acd4
不幸的是上述命令输出的是binary数据,无法阅读。你可以通过使用下面的git ls-tree命令来输出可阅读的内容。
git ls-tree 552acd4
该命令将输出目录的列表:
100644 blob 99ed0d431c5a19f147da3c4cb8421b5566600449 .gitignore 040000 tree ab4947cb27ef8731f7a54660655afaedaf45444d about 100644 blob cefb5a651557e135666af4c07c7f2ab4b8124bd7 blue.html 100644 blob cb01ae23932fd9704fdc5e077bc3c1184e1af6b9 green.html 100644 blob e993e5fa85a436b2bb05b6a8018e81f8e8864a24 index.html 100644 blob 2a6deedee35cc59a83b1d978b0b8b7963e8298e9 news-1.html 100644 blob 0171687fc1b23aa56c24c54168cdebaefecf7d71 news-2.html ...
通过检查上面命令的输出内容,我们可以假定"blobs"代表了我们repo里面的文件,而trees代表了repo里面的folders。继续通过git ls-tree检阅about tree,我们就可以看到是不是我们的假定是正确的了。
所以,blob对象实际上就是git保存我们文件内容的对象,可以简单理解为文件,tree对象组合了blob和其他的tree对象形成了目录列表,也就是说tree可以简单理解为目录。这些对象就是git最终形成我们在git中常用命令所操作的唯一对象。commit,tree,blob之间的关系可以用下面的图形象展示:
Examine a Blob
我们来看看和blue.html文件相对应的blob:git cat-file blob cefb5a6
这会展示blue.html文件的整个内容,这也印证了blob本身就是存数据文件,blob本身是纯粹的content,它本身甚至没有任何关于文件名称的信息。也就是说文件名blue.html是保存在包含blob的tree对象中,而不是在blob对象中。
你可能知道SHA-1 checksum确保一个对象的内容永远不会在Git不知情的情况下被篡改。checksum的原理是通过使用对象内容来计算一个唯一的字符序列。这不仅作为一个id,而且它保证一个对象永远不会悄无声息地被修改(而git竟然不知情).当我们来谈到blob对象时,这又有另外一个好处。既然两个具有相同内容的blob永远具有相同的checksum id,那么git可以跨tree来共享一个blob对象。比如我们的blue.html文件自从被创建后就没有被修改,那么我们的repo将只有一个相关联的blob,而所有后续的tree对象都将引用它。通过不去创建重复的blob,Git可以大大降低repo的尺寸。有这个理念作为基础,我们可以修正git的对象图如下:
然而,只要你更改文件的任何一行,Git都必需创建一个新的blob对象来反映这个修改,因为内容变更,SHA-1 checksum就将变更。当然,GIT也有一些增量修改的机制来保证这个尺寸增加不是很大的问题。
Examine a Tag
第四个也是最后一个git object是tag对象.我们可以使用git cat-file命令来显示tag的detail存储信息:git cat-file tag v2.0
上面的命令将输出和v2.0这个tag相关的commitID,以及tag的名称,作者,创建时间和附加信息。下面更新最后版本的git对象图:
Inspect Git’s Branch Representation
我们现在有了能够完全浏览git branch representation的所有工具,使用-t选项,我们可以得知git对branch使用哪种对象来表示:git cat-file -t master 将输出commit git cat-file commit master 将输出和git cat-file commit HEAD完全一样的信息
一个branch就是一个对一个commit对象的引用,这意味着我们可以通过git cat-file commit master来查看master branch的详细信息。master branch和HEAD都是对一个commit对象的简单引用。
我们打开.git/refs/heads/master文件,你可以看到该文件内容实际上就是最近的一个commit的checksumID(你可以通过git log -n 1来检查这个commitid)。这个文件就是git为了维护master分支所需的一切,所有其他的信息都是通过这个commit object根据上面讨论的关系图来外推得出的!(branch本身是否就等于branch tip呢??)
另一方面,HEAD reference本身记录在.git/HEAD文件中,不像branch tips总是指向一个branch的顶端commit,
HEAD并不是任何一个commit的直接链接。反而,HEAD总是引用一个branch,GIT使用这个branch来指出当前checkout出来的是哪一个commit。记住一个detached HEAD state是在当HEAD不再和branch的tip相一致时发生的!从机理上说,这意味着.git/HEAD并没有一个Local branch。试着checkout一个老的commit:
git checkout HEAD~1
现在,.git/HEAD就包含一个commitID,而不再是一个branch。这告诉git我们进入了一个dtached HEAD state。无论你在什么状态,git checkout命令将总是将checkedout commit的引用记录在.git/HEAD中。我们继续git checkout master,返回master branch,来接着做一些其他的实验:
Explore the Object Database
当我们有一个git对象操作的基本理解,我们可以看看git将这些对象放在哪里了。在我们的my-git-repo库,打开文件夹.git/objects,那就是git的数据库!每一个对象,无论对象的类型是什么,都被保存为一个文件,使用他的SHA-1 checksum作为文件名。但是,和传统将所有objects存放在一个文件夹的做法不同的是:他们通过将他们的ID前两个字符剔出来作为一个目录名,而id剩下的字符作为文件名。具体可以看看下面的objects输出目录格式:
00 10 28 33 3e 51 5c 6e 77 85 95 f7 01 11 29 34 3f 52 5e 6f 79 86 96 f8 02 16 2a 35 41 53 63 70 7a 87 98 f9 03 1c 2b 36 42 54 64 71 7c 88 99 fa 0c 26 30 3c 4e 5a 6a 75 83 91 a0 info 0e 27 31 3d 50 5b 6b 76 84 93 a2 pack
比如,一个具有如下ID的object,
7a52bb857229f89bffa74134ee3de48e5e146105
将会被保存在7a 文件架中,而剩下的(52bb8...)作为文件名,也就是说7a目录+52bb8...文件的组合来唯一标识该object
这样做的好处是检索迅速。知道了这一层,那么我们就可以重新组合出来我们的objectID,以便方便地查阅它的内容,
git
cat-file
-t
7a52bb8 ,
git
cat-file
blob
7a52bb8
:该命令就是重新组合我们的object,并且如果发现它是blob对象,我们就将得到其内容,如果是tree对象,则用lstree命令
Collect the Garbage
随着repo的增长,GIT可能自动将你的object文件转换成一种被成为"pack"的压缩文件。你可以使用garbage collection的命令来强制运行该压缩过程。但是要清楚:这个命令是不可回退的。如果你希望继续explore .git/objects文件夹的内容,你就应该在执行下面的命令之前进行。git gc
上面这条命令将会压缩各个object files形成更快更小的pack file并且删除一些不再引用的commit(比如frrom a deleted, unmerged branch)。
当然,所有相同objectID的都将可用git cat-file来访问。该git gc命令只是更改git的存储机制--而不是更改repo的内容。
Add Files to the Index
到现在,我们已经讨论过git的low-level representation of commited snapshots.这篇文章中,下面我们将各个零件转动运转起来,使用更多的"plumbing"命令来手工准备和提交一个新的snapshot。这将彻底解密GIT是如何管理working directory和staging area的。在my-git-repo中创建一个新的文件,命名为news-4.html,并且增加一些html代码;然后修改Index.html文件的news section以便生成一个指向news-4.html的链接。
这时,正常情况下,我们将git add, git commit提交我们的变更。现在我们来试图使用更加低级的命令来手工完成这个操作。index是git的术语,代表了staged snapshot。
git status git update-index index.html git update-index news-4.html
后面的命令将会抛出一个错误,因为git在你不明显告诉他news-4.html是一个新文件时,他是不允许加入他不知道的文件到stage area的。相反地,我们少做修改,增加--add参数:
git update-index --add news-4.html git status
我们通过上面的update-index命令将我们的working directory搬到了Index区,这意味着我们已经有了一个准备好的snapshot了,剩下来要做的事情就是commit了。
Store the Index in the Database
记住:所有的commits都引用到一个tree object,而这个tree object就代表了那个commit的snapshot。所以,在创建一个commit对象之前,我们需要将我们的Index(staged tree)放到git的object database中。我们可以通过下面的命令来达到目的:git write-tree
这个命令从index创建一个tree object并且保存在.git/objects目录中。它将输出这个命令结果的tree的checksumid:
5f44809ed995e5b861acf309022ab814ceaaafd6
你可以通过git ls-tree来检查你的新创的snapshot。记住这个commit中唯一新创的blob是index.html和news-4.html,这个tree的剩余内容引用了已经存在的blobs
git
ls-tree
5f44809
所以,我们已经有了我们的tree object了,但是我们必需将他放到我们项目的历史中去。
Create a Commit Object
为了commit the new tree object,我们可以手工地找到parent commit的ID:git log --oneline -n 1
这条命令将输出下面的内容,我们将使用这个commitID来指定新的commit对象的parent
3329762Add .gitignore file[/code]
git commit-tree命令创建一个commit object根据传入的tree和parentID参数,但是author信息却是从git的一个环境变量来读取的。
git commit-tree 5f44809 -p 3329762
这条命令将需要更多的输入: commit message.就像我们在做commit时要求输入commit message一样操作就可以了。
该命令最终输出
c51dc1b3515f9f8e80536aa7acb3d17d0400b0b5
现在你就可以在.git/objects目录下查看到这个commit了,但是无论是HEAD或者是branches都没有被自动更新而包含这个commit. 现在这就是一个dangling commit。好消息是,我们知道git在哪里保存branch信息的:
Update HEAD
既然我们并不是在一个detached HEAD state, HEAD就是一个对一个branch的引用。所以,我们要更新HEAD需要做的就是移动master branch,向前指向到我们的最新的commit object.这个工作可以通过直接在文本编辑器中修改.git/refs/heads/master为我们commit-tree命令的输出(commit objectid)来完成。如果这个文件根本不存在,也不用烦恼,这仅仅意味着git gc命令packed up all of our branch references into single file.在这种情况下,我们无法来更新。git/refs/heads/master,但是我们应该打开.git/packed-refs,找到独一refs/heads/master的引用的那行,修改即可。
既然我们的master branch指向了新的ecommit,我们应该可以在项目历史中看到news-4.html文件了。
git log -n 2
上面的章节我们解释了当我们执行git commit -a -m "some message"时所有发送在背后的真实事情。你是否觉得还是不用超低级命令的好呢?
commited, modified, staged
注意:在Git中,你的文件将有三个可能的状态存在:commited, modified, staged. Commited意味着数据已经安全地存储到了你的local database. Modified意味着你已经修改了这个文件但是还没有放到数据库中。staged意味着你已经标示了modified files,以便作为下一个commit的snapshot。这也导致了一个Git项目具有三个不同的section: Git directory, working directory, staging area.Git directory是Git用于保存其metadata和objects的地方所在。这个目录是git最重要的部分,这个也是当你clone一个repo时copy的部分。working directory是你的项目的一个版本的checkout.这些文件是从git directory的compress database中抽取出来的,并且将这些内容放到磁盘中供你来修改和使用。
staging area就是一个文件,通常就放在.git目录中,这个文件保存了关于下一个commit的所有信息。有时我们又称之为index,但是更多的情况下,人们称之为staging area. 基本的GIT workflow像下面这个样子:
1.你在working directory中修改文件;
2.你stage这些修改,adding snapshots of them to your staging area;
3.你做一个commit,这个动作将把stage区中的snapshot永远存储于git directory的repo数据库中。
如果一个文件在Git directory中存在了,那么就被认为被commited了。如果文件modified,并且已经放到staging area了,那么成为it is staged.如果自从该文件被checkout出来后做了修改,但是却还没有staged,那么他就是modified状态。
.git/index这个文件实际上就是staging area,它会实时记录你准备放到下一个commit的snapshot,我们可以用ls-files来检查他的内容(他是binary文件)
git ls-files --stage
git ls-files -stage //记住:该命令实际上查看的是.git/index文件本身 //输入如下内容: 100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 anotherfile.txt 100644 303bcbd14ef854ea5ac85a4896e5f37a11dd4394 0 hotfixbranch.txt 100644 41d9b439a7c42e9f65c5382d992a0b158ce43956 0 readme.txt 100644 b64aa37a6bd9fc4f66fe86b9c1d07b821fbf3966 0 third
由于我们已经修改了readme.txt文件并且放到staging area,那么这时我们来检视这个文件的话,
git cat-file -t 41d9b4 一定输出blob
D:\gittest>git cat-file blob 41d9 readme.txt first version second version readme to check the index area
你可以看到最后一行就是最新的更改,但是上述命令却将整个readme.txt文件都作为blob来输出了@
tracked and untracked
记住:在你的working directory中任何一个文件都有两种可能的状态:tracked or untracked. tracked文件是那些在最近的snapshot中存在的文件,他们可以被修改,反修改或者staged. Untracked文件是任何你的working directory中没有在你的last snapshot中并且未在staging area中的文件。也就是说只要是曾经执行过git add命令的,都是tracked file。

相关文章推荐
- git plumbing 更加底层命令解析-深入理解GIT
- 使用git微命令深入理解git工作机制
- 深入理解Git (三) - 微命令上篇
- 使用git微命令深入理解git工作机制
- 深入理解Git (四) -微命令下篇
- 9.1 Git 内部原理 - 底层命令 (Plumbing) 和高层命令 (Porcelain)
- 深入理解Git (三) - 微命令上篇
- 使用git微命令深入理解git工作机制
- git diff 命令深入理解
- 深入理解计算机系统(序章)------谈程序员为什么要懂底层计算机结构
- 计算机底层知识拾遗(九)深入理解内存映射mmap
- git 和 phabricator arc 常用 命令解析
- 用户管理命令useradd等的深入理解及手动创建用户
- 深入底层代码理解java中String、StringBuffer、StringBuilder
- STL源码解析---深入理解vector
- 深入理解Linux中的grep命令
- 深入理解JavaScript系列(34):设计模式之命令模式
- CSAPP深入理解计算机系统实验datalab解析
- Git 之 reset 命令解析
- Android EventBus源码解析 带你深入理解EventBus(二)