Hadoop之MapReduce—Wordcount扩展
2015-05-23 18:28
267 查看
一、查看所给的数据文件
Case 1:整个文件可以加载到内存中;
Case 2:文件太大不能加载到内存中,但<word, count>可以存放到内存中;
Case 3:文件太大无法加载到内存中,且<word, count>也不行;
二、问题规范化
将问题范化为:有一批文件(规模为TB级或者 PB级),如何统计这些文件中所有单词出现的次数;
方案:首先,分别统计每个文件中单词出现次数,然后累加不同文件中同一个单词出现次数;
典型的MapReduce过程。
三、MapReduce编程模型—WordCount
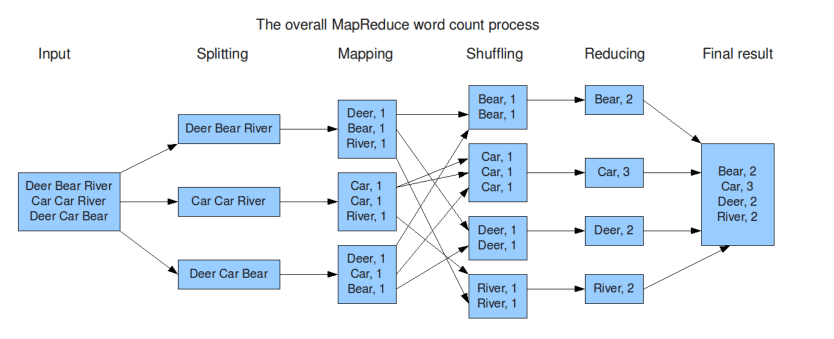
Case 1:整个文件可以加载到内存中;
Case 2:文件太大不能加载到内存中,但<word, count>可以存放到内存中;
Case 3:文件太大无法加载到内存中,且<word, count>也不行;
二、问题规范化
将问题范化为:有一批文件(规模为TB级或者 PB级),如何统计这些文件中所有单词出现的次数;
方案:首先,分别统计每个文件中单词出现次数,然后累加不同文件中同一个单词出现次数;
典型的MapReduce过程。
三、MapReduce编程模型—WordCount

相关文章推荐
- Hadoop实战-MapReduce之WordCount(五)
- Hadoop MapReduce案例word count本地环境运行时遇到的一些问题
- MapReduce中wordcount详细介绍(包括Hadoop1和Hadoop2版本)
- Hadoop2.4.1 简单的wordCount的MapReduce程序
- 初学Hadoop之图解MapReduce与WordCount示例分析
- Hadoop 用Eclipse来MapReduce WordCount实战 (2)
- hadoop mapreduce wordcount编写
- Hadoop MapReduce WordCount v2.0结合个人理解进行注释
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
- Hadoop之图解MapReduce与WordCount示例分析
- hadoop2x WordCount MapReduce
- hadoop集群配置方法---mapreduce应用:xml解析+wordcount详解---yarn配置项解析
- Hadoop学习笔记之初识MapReduce以及WordCount实例分析
- 从wordcount 开始 mapreduce (C++\hadoop streaming模式)
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
- Windows 使用Eclipse配置连接hadoop,编译运行MapReduce --本地调试WordCount
- Hadoop之Mapreduce------>入门级程序WordCount代码编写
- Hadoop下用MapReduce处理WordCount
- 初学Hadoop之图解MapReduce与WordCount示例分析