实现一个 DFA 正则表达式引擎 - 2. NFA 的构建
2015-05-17 09:52
573 查看
(正则引擎已完成,Github)
语法树如何实现对于之后步骤的繁琐程度有着举足轻重的影响。因为我们已经有了一棵简单优雅的语法树,所以我们的 NFA 很容易就可以构建出来。下面来回顾一下我们拥有的节点种类:
分支节点:Concat, Or, Many
叶子节点:Closure, Char
以下是转换的核心代码:
遍历顺序为整个语法树的深搜。
这里用了一个栈来存储搜索中非第一优先级的节点。以我们上节中的语法树为例:
|---------------[O]-------------|
|-------[C]-----| |-------[C]-----|
|---[M] b a |---[M]
a b
我们先把整个 NFA 的第一要素初态 0 和终态 1 压入栈,这时栈中有元素:
[1] [0]
自上而下开始搜索,首先我们遇到了 Or 节点,根据 Or 的规则:
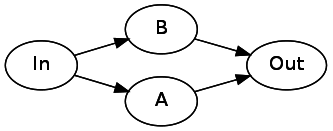
于是我们先 pop 出栈顶的两个状态,再按顺序 push 两遍:
[1] [0] [1] [0]
继续深搜遇到根节点的左儿子 Concat,按照 Concat 的规则:

创建两个新状态 2 和 3,并插入栈顶的两个状态中:
[1] [0] [1] [3] [2] [0]
遇到一个 Many,按照 Many 的规则:
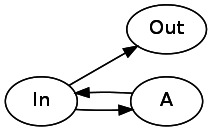
先弹出栈顶的两个状态,创建一个新状态 4, 用栈顶的状态 0 和状态 4 建立双向的 closure 连接 (状态 0 可以直接转换到状态 4,反之亦然),并把状态 4 push 两遍入栈。
[1] [0] [1] [3] [4] [4]
遇到一个字符 a,那么就弹出栈顶的两个状态,然后建立两个状态的字符连接 (就是先弹出的状态接受字符 a 转换为后弹出的状态):
[1] [0] [1] [3]
又遇到一个字符 b:
[1] [0]
至此,根节点的左子树已经遍历完了,而我们也介绍完了构建这个 NFA 所用到的所有规则。
下面直接给出遍历右子树时栈的状态:
Concat:
[1] [6] [5] [0]
a:
[1] [6]
Many:
[7] [7]
b:
Nil
因此,一棵结构正确的语法树经过这种 NFA 的构造后会留下一个空栈。
这样,我们就完成了 DFA 正则引擎的第二步: NFA 的构建。
语法树如何实现对于之后步骤的繁琐程度有着举足轻重的影响。因为我们已经有了一棵简单优雅的语法树,所以我们的 NFA 很容易就可以构建出来。下面来回顾一下我们拥有的节点种类:
分支节点:Concat, Or, Many
叶子节点:Closure, Char
以下是转换的核心代码:
public void visit(LChar lChar) {
NFAState i = stateStack.pop();
NFAState f = stateStack.pop();
i.transitionRule(lChar.c, f);
}
public void visit(LNull lNull) {
// do nothing
}
public void visit(BOr bOr) {
NFAState i = stateStack.pop();
NFAState f = stateStack.pop();
stateStack.push(f);
stateStack.push(i);
stateStack.push(f);
stateStack.push(i);
}
public void visit(BConcat bConcat) {
NFAState i = stateStack.pop();
NFAState f = stateStack.pop();
NFAState n = newState();
stateStack.push(f);
stateStack.push(n);
stateStack.push(n);
stateStack.push(i);
}
public void visit(BMany bMany) {
NFAState i = stateStack.pop();
NFAState f = stateStack.pop();
NFAState n = newState();
i.directRule(n);
n.directRule(f);
stateStack.push(n);
stateStack.push(n);
}
public void visit(LClosure lClosure) {
NFAState i = stateStack.pop();
NFAState f = stateStack.pop();
i.directRule(f);
}遍历顺序为整个语法树的深搜。
这里用了一个栈来存储搜索中非第一优先级的节点。以我们上节中的语法树为例:
|---------------[O]-------------|
|-------[C]-----| |-------[C]-----|
|---[M] b a |---[M]
a b
我们先把整个 NFA 的第一要素初态 0 和终态 1 压入栈,这时栈中有元素:
[1] [0]
自上而下开始搜索,首先我们遇到了 Or 节点,根据 Or 的规则:
于是我们先 pop 出栈顶的两个状态,再按顺序 push 两遍:
[1] [0] [1] [0]
继续深搜遇到根节点的左儿子 Concat,按照 Concat 的规则:
创建两个新状态 2 和 3,并插入栈顶的两个状态中:
[1] [0] [1] [3] [2] [0]
遇到一个 Many,按照 Many 的规则:
先弹出栈顶的两个状态,创建一个新状态 4, 用栈顶的状态 0 和状态 4 建立双向的 closure 连接 (状态 0 可以直接转换到状态 4,反之亦然),并把状态 4 push 两遍入栈。
[1] [0] [1] [3] [4] [4]
遇到一个字符 a,那么就弹出栈顶的两个状态,然后建立两个状态的字符连接 (就是先弹出的状态接受字符 a 转换为后弹出的状态):
[1] [0] [1] [3]
又遇到一个字符 b:
[1] [0]
至此,根节点的左子树已经遍历完了,而我们也介绍完了构建这个 NFA 所用到的所有规则。
下面直接给出遍历右子树时栈的状态:
Concat:
[1] [6] [5] [0]
a:
[1] [6]
Many:
[7] [7]
b:
Nil
因此,一棵结构正确的语法树经过这种 NFA 的构造后会留下一个空栈。
这样,我们就完成了 DFA 正则引擎的第二步: NFA 的构建。

相关文章推荐
- 实现一个 DFA 正则表达式引擎 - 1. 语法树的构建
- 实现一个 DFA 正则表达式引擎 - 0. 要求
- 实现一个 DFA 正则表达式引擎 - 3. NFA 的确定化
- 实现一个 DFA 正则表达式引擎 - 4. DFA 的最小化
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——2 构造抽象语法树
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——3 计算4个函数
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——4 构造DFA
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——2 构造抽象语法树
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——5 DFA最小化
- 一个正则表达式引擎的设计和实施1-如何通过NFA识别字符串
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——1 概述
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——3 计算4个函数
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——2 构造抽象语法树
- 理解DFA和NFA正则表达式引擎
- 正则表达式引擎的构建——基于编译原理DFA(龙书第三章)——1 概述
- 【从0到1】分步实现一个出生日期的正则表达式(JavaScript)
- 正则表达式原理及引擎简化递归实现
- 正则引擎:DFA和NFA
- 不到40行代码构建正则表达式引擎
- 编译原理中的正则表达式、NFA和DFA