Ranking SVM 简介
2015-05-16 11:30
176 查看
Ranking SVM 简介
Learning to Rank
Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见(译)排序学习简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise。Ranking SVM算法是PairWise方法的一种,由R. Herbrich等人在2000提出, T. Joachims介绍了一种基于用户Clickthrough数据使用Ranking SVM来进行排序的方法(SIGKDD, 2002)。Ranking SVM
我们可以学习得到一个分类器,例如SVM,来对对象对的排序进行分类并将分类器运用在排序任务中。这被Herbrich隐藏在Ranking SVM方法后的思想。图1展示了一个排序问题的例子。假设在特征空间中存在两组对象(与两个查询相关联的文献)。进一步假设有三个等级(级别)。 例如,第一个组中的对象 x1, x2 和 x3 分别有三个不同的级别。权重向量 ω 对应的线性函数 f(x)=⟨ω,x⟩ 可以对对象进行评分并排序。使用排序函数对对象进行排序等价于将对象投影到向量,并根据投影向量对对象进行排序。 如果排序函数是‘优秀’,那么等级3的对象应该排在等级2的对象之前,以此类推。要注意属于不同组的对象之间不能进行比较。

Fig. 1 Example of Ranking Problem
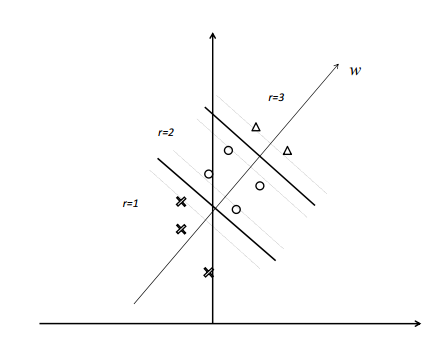
Fig. 2 Transformation to Pairwise Classification
图2显示了图1描述的排序问题可以被转化为线性的SVM分类问题。同一组中的两个特征向量之间的差别被作为新的特征向量对待, e.g.,x1−x2,x1−x3, and x2−x3. 进一步,标签也被赋给了新的特征向量。例如,x1−x2,x1−x3, and x2−x3 为正数。同一级别的特征向量或者不同组的特征向量不会被组成新的特征向量。可以通过训练得到对图5中表示的新特征向量进行分类的线性SVM分类器。 几何学上,SVM模型的边缘表示两个等级对象对之间预测的最小间距。 注意到SVM分类器的分类超平面通过对应对的原点和正样本还有负样本。 例如 x1−x2 and x2−x1 代表正样本和负样本。SVM分类器的权重向量 ω 对应于评价函数。事实上我们可以忽略掉学习过程中的负样本,因为它们是冗余的。
训练数据形如 {((x(1)i,x(2)i),yi)},i=1,⋅⋅⋅,m 其中每个样本包括两个特征向量 (x(1)i,x(2)i) 和一个标签 yi∈{+1,−1} 表示哪一个特征向量应该被排在前边。
Ranking SVM可以被公式化为如下 QP 问题。
minω,ξ12∥ω∥2+C∑mi=1ξi
s.t.yi⟨ω,x(1)i−x(2)i⟩≥1−ξi
ξi≥0i=1,...,m,
其中 x(1)i 和 x(2)i 特征向量对之中的第一个和第二个特征向量。 ||⋅|| L2 范数, m 表示训练样本的数量, C>0 是一个系数。
这等价于下面这个无约束优化问题,i.e.,回归 hinge loss 函数的最小化。
minω∑i=1m[1−yi⟨ω,x(1)i−x(2)i⟩]++λ∥ω∥2(5)
其中 [x]+ 表示函数 max(x,0) , λ=12C。
使用Clickthrough数据作为训练数据
T. Joachims提出了一种非常巧妙的方法, 来使用Clickthrough数据作为Ranking SVM的训练数据。假设给定一个查询”Support Vector Machine”, 搜索引擎的返回结果为

其中1, 3, 7三个结果被用户点击过, 其他的则没有。因为返回的结果本身是有序的, 用户更倾向于点击排在前面的结果, 所以用户的点击行为本身是有偏(Bias)的。为了从有偏的点击数据中获得文档的相关信息, 我们认为: 如果一个用户点击了a而没有点击b, 但是b在排序结果中的位置高于a, 则a>b。
所以上面的用户点击行为意味着: 3>2, 7>2, 7>4, 7>5, 7>6。
Ranking SVM的开源实现
Ranking SVM下载
H. Joachims的主页Support Vector Machine for Ranking上有Ranking SVM的开源实现。可以下载源码自己编译,或者根据自身系统环境下载编译好的可以直接运行的二进制文件。如Windows环境可以下载http://download.joachims.org/svm_rank/current/svm_rank_windows.zip。下载后解压,目录中有三个文件:
svm_rank_learn.exe
svm_rank_classify.exe
LICENSE.txt
svm_rank_learn.exe和svm_rank_classify.exe分别用于学习过程、预测过程。
如果下载源码自己编译的话,源码中有Makefile,在linux中应该可以直接make,但windows上我还没尝试,不太清楚。编译过程中如果有问题可以参考SVMlight & SVMstruct FAQ。
Ranking SVM使用
SVMrank包括一个学习模块(svm_rank_learn),还有一个预测模块(svm_rank_classify)。SVMrank输入输出格式和SVM-light类似,并且功能和使用’-z p’选项的SVMlight一样。可以通过
svm_rank_learn -c 20.0 train.dat model.dat
来对训练数据 train.dat 进行训练,输出的训练结果会保存到 model.dat 中,正则化参数C设置为20.0。SVMrank中的C和SVMlight中的C有所不同,Clight=Crank/n,其中n是训练数据中查询的个数(训练集中不同的qid的个数)。SVMrank中部分选项与SVMstruct和SVMlight中的一样。只有部分SVMrank独有的选项,如:
General Options: -? -> this help -v [0..3] -> verbosity level (default 1) -y [0..3] -> verbosity level for svm_light (default 0) Learning Options: -c float -> C: trade-off between training error and margin (default 0.01) -p [1,2] -> L-norm to use for slack variables. Use 1 for L1-norm, use 2 for squared slacks. (default 1) -o [1,2] -> Rescaling method to use for loss. 1: slack rescaling 2: margin rescaling (default 2) -l [0..] -> Loss function to use. 0: zero/one loss ?: see below in application specific options (default 1) Optimization Options (see [2][5]): -w [0,..,9] -> choice of structural learning algorithm (default 3): 0: n-slack algorithm described in [2] 1: n-slack algorithm with shrinking heuristic 2: 1-slack algorithm (primal) described in [5] 3: 1-slack algorithm (dual) described in [5] 4: 1-slack algorithm (dual) with constraint cache [5] 9: custom algorithm in svm_struct_learn_custom.c -e float -> epsilon: allow that tolerance for termination criterion (default 0.001000) -k [1..] -> number of new constraints to accumulate before recomputing the QP solution (default 100) (-w 0 and 1 only) -f [5..] -> number of constraints to cache for each example (default 5) (used with -w 4) -b [1..100] -> percentage of training set for which to refresh cache when no epsilon violated constraint can be constructed from current cache (default 100%) (used with -w 4) SVM-light Options for Solving QP Subproblems (see [3]): -n [2..q] -> number of new variables entering the working set in each svm-light iteration (default n = q). Set n < q to prevent zig-zagging. -m [5..] -> size of svm-light cache for kernel evaluations in MB (default 40) (used only for -w 1 with kernels) -h [5..] -> number of svm-light iterations a variable needs to be optimal before considered for shrinking (default 100) -# int -> terminate svm-light QP subproblem optimization, if no progress after this number of iterations. (default 100000) Kernel Options: -t int -> type of kernel function: 0: linear (default) 1: polynomial (s a*b+c)^d 2: radial basis function exp(-gamma ||a-b||^2) 3: sigmoid tanh(s a*b + c) 4: user defined kernel from kernel.h -d int -> parameter d in polynomial kernel -g float -> parameter gamma in rbf kernel -s float -> parameter s in sigmoid/poly kernel -r float -> parameter c in sigmoid/poly kernel -u string -> parameter of user defined kernel Output Options: -a string -> write all alphas to this file after learning (in the same order as in the training set) Application-Specific Options: The following loss functions can be selected with the -l option: 1 Total number of swapped pairs summed over all queries. 2 Fraction of swapped pairs averaged over all queries. NOTE: SVM-light in '-z p' mode and SVM-rank with loss 1 are equivalent for c_light = c_rank/n, where n is the number of training rankings (i.e. queries).
SVMrank的训练和测试数据格式都和SVMlight相同(详细的说明参见这里),输入文件每行都是按照 qid 的递增顺序的。第一行如果以#开头会被作为注释忽略。接下来的每一行表示一个训练实例,并且有如下格式:
<line> .=. <target> qid:<qid> <feature>:<value> <feature>:<value> ... <feature>:<value> # <info> <target> .=. <float> <qid> .=. <positive integer> <feature> .=. <positive integer> <value> .=. <float> <info> .=. <string>
Feature/value对必须按照 Feature 增加的顺序排列。Feature 值为0的可以忽略。target值表示每个查询实例的顺序。”qid”可以对pairwise的生成进行约束,只有”qid”值相同的特征才会被用来生成pairwise。例如:
3 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A 2 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B 1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C 1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D 1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A 2 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B 1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C 1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D 2 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A 3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B 4 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C 1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D
会生成一下pairwise
1A>1B, 1A>1C, 1A>1D, 1B>1C, 1B>1D, 2B>2A, 2B>2C, 2B>2D, 3C>3A, 3C>3B, 3C>3D, 3B>3A, 3B>3D, 3A>3D
更多说明请参考Support Vector Machine for Ranking以及相关文献。
svm_rank_learn的结果是从训练数据 train.dat 中通过训练所得的模型。模型保存在model.dat中。
通过svm_rank_classify进行预测的命令为:
svm_rank_classify test.dat model.dat predictions
对测试数据test.dat中的每一行,会在 predictions 文件中保存一个代表ranking score的预测结果。predictions 中的每一行都与test example中的每一行对应。通过预测得到的分数,就能对test example中的数据进行排序。
使用Ranking SVM的实例
可以在这里下载到测试用的例子。解压后包括test.dat和train.dat两个文件,用文本编辑器可以直接打开,打开分别后如下两图:

在命令行中使用如下数据进行训练
svm_rank_learn -c 3 example3/train.dat example3/model
注意:可以把svm_rank_learn .exe的路径加入环境变量Path,或者放到一个Path中有的路径中,或者使用svm_rank_learn.exe的完整路径(如D:\svm_rank_windows\svm_rank_learn.exe)。train.dat的路径和存放model 的路径也需要自行修改。
学习结束后,可以使用文本编辑器打开model ,如下:

前边几行是一些参数的设置,最后一行是每个特征的参数(权值)。
训练完成后可以进行预测,预测命令为
svm_rank_classify example3/test.dat example3/model example3/predictions
同样,路径需要自行调整。预测结束后,可以得到一下返回:

并生成predictions文件,打开predictions文件,如下:

可以看到对应test.dat中每一行的评分,按照评分排序,可以看到对test.dat进行了正确的排序。
注:
test.dat中数据格式与train.dat中数据格式相同,第一列为target。但经我分析还有测试的结果是,这个target只是用于对排序效果进行评价用的,在最后的结果可以看到test set上的平均损失等项,就是根据这个target进行计算的。在实际预测中没有已知target的时候,第一列可以设置为相同值,但不能删除,否则报错。Reference
(译)排序学习简介)Learning to Rank之Ranking SVM 简介
Hang L I. A short introduction to learning to rank[J]. IEICE TRANSACTIONS on Information and Systems, 2011, 94(10): 1854-1862.
Support Vector Machine for Ranking
T. Joachims, Training Linear SVMs in Linear Time, Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (KDD), 2006.

相关文章推荐
- Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介
- Unicode简介
- 如何选择开源项目:开源协议简介
- Hive简介
- (翻译)零 MongoDB入门-MongoDB简介
- [c#网络编程]专题一:网络协议简介
- Linux内存机制简介
- BlazeDS的架构和工作原理简介
- java中的反射简介
- UIView 简介(十四)transfrom属性
- Android 6.0 新增API 简介(1)
- 1. PDO简介
- 转:npm 模块安装机制简介
- Linux 内核 3.3 和 3.4 简介
- Cesium学习(1):简介
- 接口编写、调用及测试简介
- Spring Cloud微服务分布式云架构-集成项目简介
- IBM DB2 Connect简介(1)
- [非原创] .Net框架下的XSLT转换技术简介
- 【简介】如何编写linux下nand flash驱动-2【转载】