[ 大数据系列之Hadoop ][2] Zookeeper学习笔记
2015-05-08 10:36
381 查看
Zookeeper 是Hadoop的高可用高性能的分布式协调服务。
Zookeeper 不能避免这个问题,也不会隐藏部分失败。提供一组工具可以处理部分失败。
丰富的building block实现多种协调数据结构和协议,例如:分布式队列,分布式锁,和领导选举 。

高可用
松耦合:进程可以在Zookeeper留下消息,另一个进程去读取。
高性能:10000操作/s
ACID性:
每个node原子性读写
一旦更新成功,无roll back
顺序一致性:客户端看到的是一个操作序列,有顺序的
node之间互相隔离
用过commit log和replication 来保证durable(持久性)
CAP性:
Consistency:线性化写入,有全局序
可能无法被写:严格的quorum(仲裁)机制(基于replication数)
Partion Tolerance
例子:
领导选举: 保证任何时刻只有一个active 的master
配置管理: 存储bootstrap location
成员管理: 发现服务器并且及时通知服务器挂掉的情况
为何需要Zookeeper?
自己写分布式协议来协调太烦了,容易错。
分布式系统架构很难
races, deadlocks, inconsistency, reliability
而 ZK 可以帮助解决上述问题。
启动 : zkServer.sh start
echo ruok | nc localhost 2181 查看Zookeeper服务是否完好。其他管理功能详见: http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_zkCommands
znode数据访问具有原子性,不会部分读写失败,不支持append操作。
通过路径访问引用。不可使用zookeeper作为路径名,为保留字。
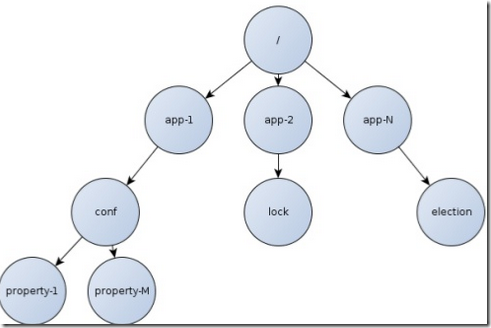
3.1.1 znode特性
1. 短暂znode
znode有两种类型:短暂(断开连接后会被删除)和持久(断开连接后不会被删除)的,创建后无法被修改。因为znode的读写原子性,故而短暂znode适合于某个特定时刻的资源可用性判定。
2. 顺序号znode
znode的名称中包含Zookeeper单调递增的顺序号的znode,由其父znode维护用来保证znode的唯一性。顺序号可以被用来为所有的事件进行全局排序,客户端可以根据顺序号知道事件的先后顺序。例如:实现分布式共享锁。
3. 观察,watch
znode一旦发生某些操作,watch机制可以让客户端感知到。因为是小文件而且整体读写,故而摒弃了一半FS的基本操作“打开、关闭、查找”,也没必要。

3.1.3 集合更新 multiupdate
Zookeeper中有一个multi操作,可以用来把多个基本操作合成一个操作单元,原子性成功或者失败。例子:构建一个无向图。
3.1.4 API
有两种类型的API,同步和异步,后者吞吐量更高,适合事件驱动编程,前者响应性更好。以exist为例:
同步:public Stat exists(String path, Watcher watcher) throws KeeperException, InterruptedException
异步:public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
3.1.5 watch机制
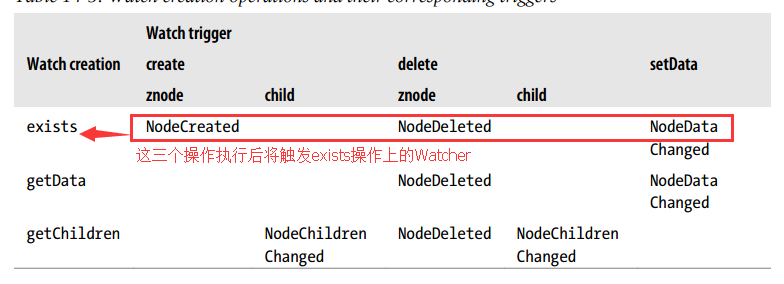
客户端可以在某些操作上设置Watcher,然后这些操作会被另一些操作触发从而引起客户端感知,从而引起相应的行为。例如:客户端在exists操作上设置了Watcher,如果所观察的znode被创建、删除、或者更新数据了,则exists操作上的Watcher将被触发,从而可以执行一些操作。
下面是一个完整Watch机制的列表:

Zab协议:
1. 领导选举:半数以上或者指定数量的follower把自己的状态与leader同步,则完成选举过程。
2. 所有写请求发给leader,然后leader广播给follower,半数以上持久化后,leader则提交这个更新,客户端会收到一个更新成功的response。
连接建立后,在Session超时时间超过后,则断开连接,Session超时,短暂znode被删除,Session过期后则无法被打开
Session空闲超过一定时间后,客户端会自动发ping请求(心跳),心跳间隔应该足够低,从而可以知道服务器down掉(判断是否down的标识是读是否超时)
Zookeeper客户端自动进行Fail Over切换到另一台Zookeeper服务器,切换后,所有的session和短暂znode依然有效。
故障切换过程中,客户端将收到断开连接和连接至服务的通知。fail over的时候断开连接时watcher的通知将无法被发送,恢复连接后,延迟的watcher通知会被继续发送
几个时间参数:
ticker time: Zookeeper中的基本时钟周期,定义互相交互的时间表,其他的时间都根据tick数来设计
session timeout: 一般设置为2个tick到20个tick之间
读超时:该Zookeeper服务器dead
session timeout的设置考虑:
短session timeout,好处:较快检测到机器故障,坏处:太短的话,网络繁忙导致其他数据包传输延迟。
应用的暂时znode创建很复杂的话,因为重建代价较大,故而兼用用长session timeout。
较长session timeout,还可以用来做应用重启和升级。
每个session有一个txid和密码被落盘存储,可以在重启应用时凭借这个来恢复session。
一般的规则是:Zookeeper中的服务器越多,那么session timeout就越大,连接超时、读超时、ping周期都被设置为和服务器数量正相关。如果频繁丢失连接,考虑增大timeout参数设置。
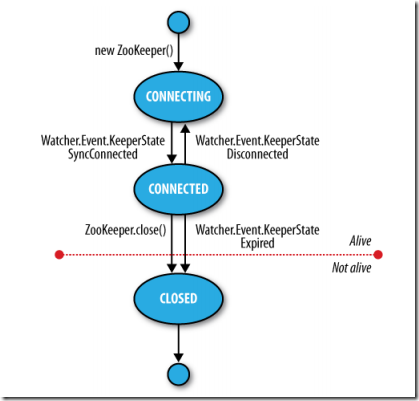
注册Watcher对象,使用了Zookeeper对象的客户端可以收到状态转换通知,进入CONNECTED状态时,Watcher对象收到一个WatchedEvent通知,其中KeeperState为SyncConnnected。
Zookeeper的Watcher对象事实上有两个责任:1. 观察znode变化的通知 2. 观察Zookeeper状态变化的通知。
进入closed,则为not alive,可以用过isAlive()来判断是否alive.
1 Partial Failure 部分失败
即:我们不知道一个操作是否已经失败。分布式应用经常出现这个问题,比如:网络错误导致不知道对方是否收到,或者接受者进程死掉。解决方法:发送者重新连接接受者并且询问。Zookeeper 不能避免这个问题,也不会隐藏部分失败。提供一组工具可以处理部分失败。
zookeeper特点
简单:非常简单的文件系统,一个znode限制1MB丰富的building block实现多种协调数据结构和协议,例如:分布式队列,分布式锁,和领导选举 。

高可用
松耦合:进程可以在Zookeeper留下消息,另一个进程去读取。
高性能:10000操作/s
ACID性:
每个node原子性读写
一旦更新成功,无roll back
顺序一致性:客户端看到的是一个操作序列,有顺序的
node之间互相隔离
用过commit log和replication 来保证durable(持久性)
CAP性:
Consistency:线性化写入,有全局序
可能无法被写:严格的quorum(仲裁)机制(基于replication数)
Partion Tolerance
例子:
领导选举: 保证任何时刻只有一个active 的master
配置管理: 存储bootstrap location
成员管理: 发现服务器并且及时通知服务器挂掉的情况
为何需要Zookeeper?
自己写分布式协议来协调太烦了,容易错。
分布式系统架构很难
races, deadlocks, inconsistency, reliability
而 ZK 可以帮助解决上述问题。
2 安装和运行Zookeeper
解压zookeeper-.x.y.z.tar.gz 后 export PATH,然后设置 zoo.cfgtickTime=2000 // zookeeper的基本时间单元,毫秒单位
dataDir=/Users/tom/zookeeper // zookeeper数据存储目录
clientPort=2181
启动 : zkServer.sh start
echo ruok | nc localhost 2181 查看Zookeeper服务是否完好。其他管理功能详见: http://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_zkCommands
3 Zookeeper服务
3.1 数据模型
树形层次。znode与ACL关联,是一个小数据文件,1MB限制。znode数据访问具有原子性,不会部分读写失败,不支持append操作。
通过路径访问引用。不可使用zookeeper作为路径名,为保留字。
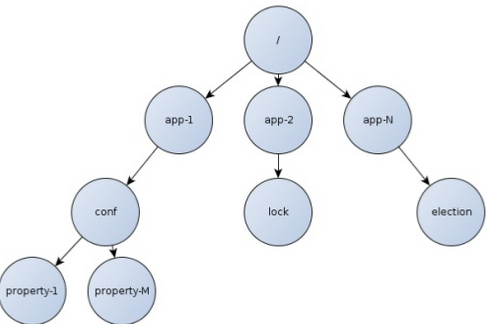
3.1.1 znode特性
1. 短暂znode
znode有两种类型:短暂(断开连接后会被删除)和持久(断开连接后不会被删除)的,创建后无法被修改。因为znode的读写原子性,故而短暂znode适合于某个特定时刻的资源可用性判定。
2. 顺序号znode
znode的名称中包含Zookeeper单调递增的顺序号的znode,由其父znode维护用来保证znode的唯一性。顺序号可以被用来为所有的事件进行全局排序,客户端可以根据顺序号知道事件的先后顺序。例如:实现分布式共享锁。
3. 观察,watch
znode一旦发生某些操作,watch机制可以让客户端感知到。因为是小文件而且整体读写,故而摒弃了一半FS的基本操作“打开、关闭、查找”,也没必要。
3.1.2 操作
9中基本操作如下:其中delete和setData需要提供版本号,可以通过exists操作获取到。
3.1.3 集合更新 multiupdate
Zookeeper中有一个multi操作,可以用来把多个基本操作合成一个操作单元,原子性成功或者失败。例子:构建一个无向图。
3.1.4 API
有两种类型的API,同步和异步,后者吞吐量更高,适合事件驱动编程,前者响应性更好。以exist为例:
同步:public Stat exists(String path, Watcher watcher) throws KeeperException, InterruptedException
异步:public void exists(String path, Watcher watcher, StatCallback cb, Object ctx)
3.1.5 watch机制
客户端可以在某些操作上设置Watcher,然后这些操作会被另一些操作触发从而引起客户端感知,从而引起相应的行为。例如:客户端在exists操作上设置了Watcher,如果所观察的znode被创建、删除、或者更新数据了,则exists操作上的Watcher将被触发,从而可以执行一些操作。
下面是一个完整Watch机制的列表:
3.2 Zookeeper的副本模式
奇数个节点保证,半数以上处于可用状态,则认为其可用。Zab协议:
1. 领导选举:半数以上或者指定数量的follower把自己的状态与leader同步,则完成选举过程。
2. 所有写请求发给leader,然后leader广播给follower,半数以上持久化后,leader则提交这个更新,客户端会收到一个更新成功的response。
3.3 Zookeeper Session
连接会尝试连接Zookeeper集群的多个服务器列表连接建立后,在Session超时时间超过后,则断开连接,Session超时,短暂znode被删除,Session过期后则无法被打开
Session空闲超过一定时间后,客户端会自动发ping请求(心跳),心跳间隔应该足够低,从而可以知道服务器down掉(判断是否down的标识是读是否超时)
Zookeeper客户端自动进行Fail Over切换到另一台Zookeeper服务器,切换后,所有的session和短暂znode依然有效。
故障切换过程中,客户端将收到断开连接和连接至服务的通知。fail over的时候断开连接时watcher的通知将无法被发送,恢复连接后,延迟的watcher通知会被继续发送
几个时间参数:
ticker time: Zookeeper中的基本时钟周期,定义互相交互的时间表,其他的时间都根据tick数来设计
session timeout: 一般设置为2个tick到20个tick之间
读超时:该Zookeeper服务器dead
session timeout的设置考虑:
短session timeout,好处:较快检测到机器故障,坏处:太短的话,网络繁忙导致其他数据包传输延迟。
应用的暂时znode创建很复杂的话,因为重建代价较大,故而兼用用长session timeout。
较长session timeout,还可以用来做应用重启和升级。
每个session有一个txid和密码被落盘存储,可以在重启应用时凭借这个来恢复session。
一般的规则是:Zookeeper中的服务器越多,那么session timeout就越大,连接超时、读超时、ping周期都被设置为和服务器数量正相关。如果频繁丢失连接,考虑增大timeout参数设置。
3.4 Zookeeper状态
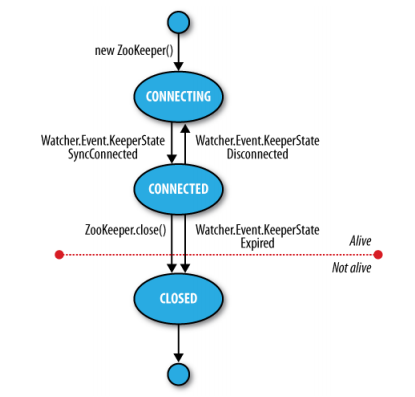
注册Watcher对象,使用了Zookeeper对象的客户端可以收到状态转换通知,进入CONNECTED状态时,Watcher对象收到一个WatchedEvent通知,其中KeeperState为SyncConnnected。
Zookeeper的Watcher对象事实上有两个责任:1. 观察znode变化的通知 2. 观察Zookeeper状态变化的通知。
进入closed,则为not alive,可以用过isAlive()来判断是否alive.
4 使用Zookeeper的例子
4.1 配置管理
原理:使用Watch机制,可以让配置被更改(znode)的时候通知其他Watcher,进行相应的操作。4.2 分布式锁
原理:znode-sessionId-sequenceId单调递增,其中sequenceId最小的服务器获得锁。带上sessionId可以重试恢复。
相关文章推荐
- [置顶] 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
- Hadoop学习笔记(三)——zookeeper的一致性协议:ZAB
- 大数据学习系列(6)-- zookeeper集群搭建
- Hadoop学习笔记系列文章导航
- Hadoop学习笔记系列文章导航
- hadoop学习笔记:zookeeper学习(上)
- hadoop学习笔记(十)——hadoop + hbase + zookeeper
- Hadoop学习笔记系列文章导航
- Hadoop学习笔记系列文章导航【持续更新中...】
- 大数据技术学习笔记之Hadoop框架基础4-MapReduceshuffer过程详解及zookeeper框架学习
- zookeeper3.3学习笔记3:观察hadoop集群中的zookeeper
- hadoop学习笔记之zookeeper服务
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
- 大数据-Hadoop学习笔记07
- hadoop学习笔记之zookeeper 安装配置
- Hadoop学习笔记(二)——zookeeper使用和分析
- Hadoop学习笔记-006-CentOS_6.5_64_HA高可用-安装Zookeeper3.4.5
- hadoop学习笔记:zookeeper学习(上)
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
- Hadoop学习笔记系列文章导航