【机器学习】K-means聚类
2015-04-27 21:49
218 查看
转自:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html
K-means聚类:这篇博客讲的很好,从聚类算法过程,到原理都讲的很清晰。
再增加一些自己的总结:
1、由于k-means是无监督聚类,也就是不知道样本的类别信息,那么如何确定当前分的K类是最优的?
确切的来说,没有特定的方法来确定K的最优值。那么如何让K趋近最优呢,一种方法是靠先验来估计,比如一堆数据,你可以事先估计大概分为几类,可以通过画图来看样本的大概分散程度和类别数目,或者根据样本特点来估计类别数目。然后可以在此类别附近进行K-means聚类,看哪个效果更好。
那么如何确定哪个效果更好的,也就是第二种方法,一个好的聚类就是类内间距最小,类间间距最大,所以说,可以依靠方差或者均值来判断聚类效果的好坏,类内方差越小,类间距离越大,说明类内样本越聚合,则分类效果越好。
2、如何判断K-means是收敛的?
在博客中也提到说当质心的值变化不大的时候,认为它就是收敛的。
还有一种方法是当类内的样本变化不大时,认为他是收敛的;个人觉得就聚类来讲,第二种方法更好一点,因为我们的目的是把样本归类,第一种方法只关心质心而忽略了样本的分布,而第二种方法却考虑了样本同时也就考虑了质心。
当然如果无论怎样迭代都达不到收敛的阈值,那么可以设定迭代次数来保证迭代不会无休止的进行下去。
或者像刚才1中提到的根据方差来判断,方差逐渐减小,当小到一定程度,即可认为已经收敛。
3、k-means初始质心的选择?
由于K-means是对初始质心敏感的,那么初始值得不同对结果影响很大,如何进行初始值的选择呢?
多进行几次K-means,选择其中效果最好的。
去除一些游离在样本边缘的数据。
4、k-means的距离有哪些?
最常用距离有欧式距离:

曼哈顿距离:

闵可夫斯基距离:
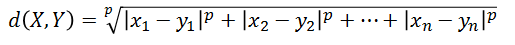
5、k-means中异常值造成的质心偏移问题
在k-means中质心一般为此类中维度的均值,如果在此类中某个点与大多数的质心距离较远,就会造成质心远离大多数点,在进行聚类中就会融入很多不属于此类的数据。比如聚类后有如下几点属于一类:(2,1)(1,1)(2,2)(1,2)(5,5)其中(5,5)为噪声点,此时求的的质心为(2.2,2.2),这个质心值远离大部分点,造成了质心的偏移,为了解决问题,可以选择类中的点作为质心点,比如(1,2)作为质心点,这样质心不会偏离大部分数据,可以使类别更紧凑。
K-means聚类:这篇博客讲的很好,从聚类算法过程,到原理都讲的很清晰。
再增加一些自己的总结:
1、由于k-means是无监督聚类,也就是不知道样本的类别信息,那么如何确定当前分的K类是最优的?
确切的来说,没有特定的方法来确定K的最优值。那么如何让K趋近最优呢,一种方法是靠先验来估计,比如一堆数据,你可以事先估计大概分为几类,可以通过画图来看样本的大概分散程度和类别数目,或者根据样本特点来估计类别数目。然后可以在此类别附近进行K-means聚类,看哪个效果更好。
那么如何确定哪个效果更好的,也就是第二种方法,一个好的聚类就是类内间距最小,类间间距最大,所以说,可以依靠方差或者均值来判断聚类效果的好坏,类内方差越小,类间距离越大,说明类内样本越聚合,则分类效果越好。
2、如何判断K-means是收敛的?
在博客中也提到说当质心的值变化不大的时候,认为它就是收敛的。
还有一种方法是当类内的样本变化不大时,认为他是收敛的;个人觉得就聚类来讲,第二种方法更好一点,因为我们的目的是把样本归类,第一种方法只关心质心而忽略了样本的分布,而第二种方法却考虑了样本同时也就考虑了质心。
当然如果无论怎样迭代都达不到收敛的阈值,那么可以设定迭代次数来保证迭代不会无休止的进行下去。
或者像刚才1中提到的根据方差来判断,方差逐渐减小,当小到一定程度,即可认为已经收敛。
3、k-means初始质心的选择?
由于K-means是对初始质心敏感的,那么初始值得不同对结果影响很大,如何进行初始值的选择呢?
多进行几次K-means,选择其中效果最好的。
去除一些游离在样本边缘的数据。
4、k-means的距离有哪些?
最常用距离有欧式距离:
曼哈顿距离:
闵可夫斯基距离:
5、k-means中异常值造成的质心偏移问题
在k-means中质心一般为此类中维度的均值,如果在此类中某个点与大多数的质心距离较远,就会造成质心远离大多数点,在进行聚类中就会融入很多不属于此类的数据。比如聚类后有如下几点属于一类:(2,1)(1,1)(2,2)(1,2)(5,5)其中(5,5)为噪声点,此时求的的质心为(2.2,2.2),这个质心值远离大部分点,造成了质心的偏移,为了解决问题,可以选择类中的点作为质心点,比如(1,2)作为质心点,这样质心不会偏离大部分数据,可以使类别更紧凑。

相关文章推荐
- 机器学习小组知识点34:K-means聚类
- 【机器学习】聚类算法:层次聚类、K-means聚类
- 机器学习常用算法(1)最小二乘和k-means聚类
- 机器学习(一) K-means聚类
- 【机器学习】人像识别(三)——K-Means聚类
- 机器学习聚类算法——K-means聚类
- 【Python】scikit-learn机器学习(八)——K-means聚类
- 机器学习系列:(六)K-Means聚类
- 机器学习系列:(六)K-Means聚类
- 微软收购以色列机器学习厂商Equivio
- 机器学习中的数据清洗与特征处理综述
- 机器学习中梯度下降法和牛顿法的比较
- Python机器学习(四):logistic回归
- 机器学习实践之利用SVD简化数据
- Python 机器学习工具库
- 科普 | 12个关键词,告诉你到底什么是机器学习
- 机器学习那些事
- 《基于机器学习的企业定价算法研究》阅读笔记
- 机器学习 李宏毅 L31-Support Vector Machine
- 【机器学习】k-近邻算法以及算法实例