通过案例学调优之--Oracle 全文索引
2015-03-31 12:10
453 查看
通过案例学调优之--Oracle 全文索引全文检索(oracle text) Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力,Oracle Text 是 Oracle9i 采用的新名称,在 oracle8/8i 中被称为 oracle intermedia text,oracle8 以前是 oracle context cartridge。Oracle Text 的索引和查找功能并不局限于存储在数据库中的数据。 它可以对存储于文件系统中的文档进行检索和查找,并可检索超过 150 种文档类型,包括 Microsoft Word、PDF和XML。Oracle Text查找功能包括模糊查找、词干查找(搜索mice 和查找 mouse)、通配符、相近性等查找方式,以及结果分级和关键词突出显示等。你甚至 可以增加一个词典,以查找搭配词,并找出包含该搭配词的文档。 Oracle text 需要为可检索的数据项建立索引,用户才能够通过搜索查找内容,索引进 程是根据管道建模的,在这个管道中,数据经过一系列的转换后,将其关键字会添加到索引 中。该索引进程分为多个阶段,如下图
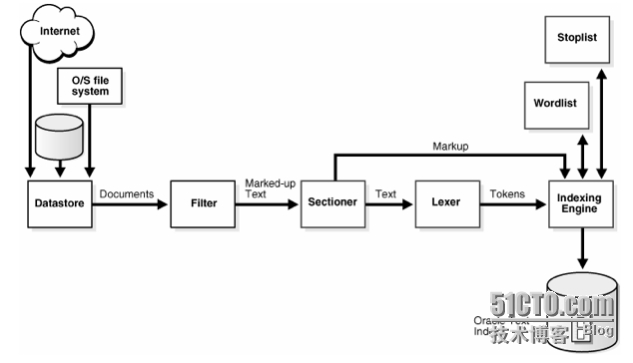
1.数据检索(Datastore):只是将数据从数据存储(例如 web 页面、数据库大型对象或本 地文件系统)中取出,然后作为数据流传送到下一个阶段。 2. 过滤(Filter):过滤器负责将各种文件格式的数据转换为纯文本格式,索引管道中的其 他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。 3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。 4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。 5. 索引(Index):最后一个阶段将关键字添加到实际索引中。 全文检索和普通检索的区别 不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作:1 、SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;2 、SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候。然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能。附:这里顺带记录一下INSTR和LIKE:Oracle中,可以使用 Instr 函数对某个字符串进行判断,判断其是否含有指定的字符。其语法为:Instr(string, substring, position, occurrence)。string:代表源字符串(写入字段则表示此字段的内容)。substring:代表想从源字符串中查找的子串。position:代表查找的开始位置,该参数可选的,默认为1。occurrence:代表想从源字符中查找出第几次出现的substring,该参数也是可选的,默认为1。position 的值为负数,那么代表从右往左进行查找。instr和like的性能比较其实从效率角度来看,谁能用到索引,谁的查询速度就会快。like有时可以用到索引,例如:name like ‘李%’,而当下面的情况时索引会失效:name like ‘%李’。所以一般我们查找中文类似于‘%字符%’时,索引都会失效。与其他数据库不同的是,oracle支持函数索引。例如在name字段上建个instr索引,查询速度就比较快了,这也是为什么instr会比like效率高的原因。注:instr(title,’手册’)>0 相当于like‘%手册%’instr(title,’手册’)=0 相当于not like‘%手册%’Oracle Text 索引原理 Oracle text 索引将文本中所有的字符转化成记号(token),如 www.taobao.com 会转化 成 www,taobao,com 这样的记号。
Oracle10g 里面支持四种类型的索引:context、ctxcat、ctxrule、ctxxpath
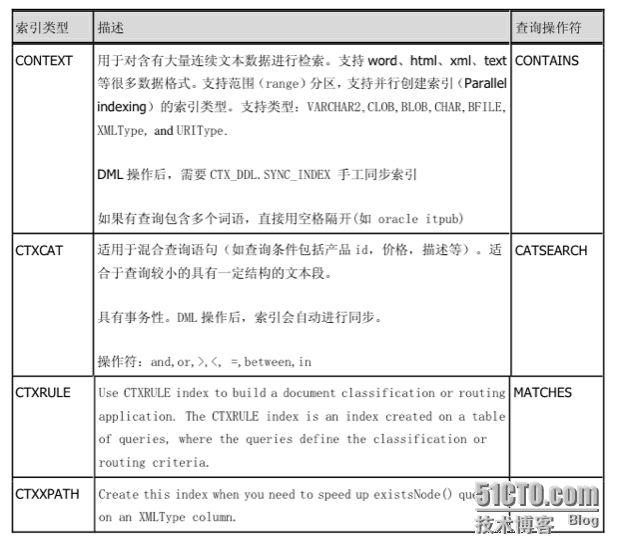
CONTEXT 用于对含有大量连续文本数据进行检索。支持 word、html、xml、text 等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType. DML 操作后,需要 CTX_DDL.SYNC_INDEX 手工同步索引 如果有查询包含多个词语,直接用空格隔开(如 oracle itpub) 案例分析:设置全文检索步骤步骤一:检查和设置数据库角色 首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能(10G默认安装都有此用户和角色)。你必须修改数据库以安装这项功能。默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys的用户。
14:53:20 SCOTT@ prod >insert into textdemo values (10,'luyao',sysdate,'pingfan de world','zhen shi de gushi','/home/1.txt');
1 row created.
14:54:32 SCOTT@ prod >commit;SELECT * FROM ctx_USER_index_errors
附:对于建立索引的类型(例如ctxsys.context),包括四种:context,ctxcat,ctxrule,ctxxpath。
CONTEXT用于对含有大量连续文本数据进行检索。支持word、html、xml、text等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。
支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.DML。操作后,需要CTX_DDL.SYNC_INDEX手工同步索引如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)。
查询标识符CONTAINS
CTXCAT适用于混合查询语句(如查询条件包括产品id,价格,描述等)。适合于查询较小的具有一定结构的文本段。具有事务性。DML 操作后,索引会自动进行同步。
操作符:and,or,>,;<, =,between,in
查询标识符CATSEARCH
CTXRULE查询标识符MATCHES。
CTXXPATH(这两个索引没有去更多搜索相关内容)
一般来说我们建立CONTEXT类型的索引(CONTAINS来查询)。[b]15:19:21 SCOTT@ prod >insert into textdemo values (20,'huoda',sysdate,'musilin de zangli','meili de rensheng','/home/2.txt');
1 row created.
15:20:10 SCOTT@ prod >commit;
15:21:35 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where BOOK_ABSTRACT like '%rensheng%'
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng
15:23:12 SCOTT@ prod >set autotrace on
15:23:38 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 2570915478
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1027 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEXTDEMO | 1 | 1027 | 4 (0)| 00:00:01 |
|* 2 | DOMAIN INDEX | DEMO_ABSTRACT | | | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("BOOK_ABSTRACT",'rensheng')>0)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
23 recursive calls
0 db block gets
33 consistent gets
0 physical reads
0 redo size
349 bytes sent via SQL*Net to client
404 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
15:26:40 SYS@ prod >select * from ctxsys.dr$pending;
PND_CID PND_PID PND_ROWID PND_TIMES P
---------- ---------- ------------------ --------- -
1082 0 AAASrlAAEAAAAI1AAB 21-NOV-14 N
15:26:26 SCOTT@ prod >alter index demo_abstract rebuild parameters('sync');
Index altered.
15:30:10 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng
1.数据检索(Datastore):只是将数据从数据存储(例如 web 页面、数据库大型对象或本 地文件系统)中取出,然后作为数据流传送到下一个阶段。 2. 过滤(Filter):过滤器负责将各种文件格式的数据转换为纯文本格式,索引管道中的其 他组件只能处理纯文本数据,不能识别 Ms word 或 excel 等文件格式。 3. 分段(Sectioner):分段器添加关于原始数据项结构的元数据。 4. 词法分析(Lexer):根据数据项的语言将字符流分为几个字词。 5. 索引(Index):最后一个阶段将关键字添加到实际索引中。 全文检索和普通检索的区别 不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作:1 、SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;2 、SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候。然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能。附:这里顺带记录一下INSTR和LIKE:Oracle中,可以使用 Instr 函数对某个字符串进行判断,判断其是否含有指定的字符。其语法为:Instr(string, substring, position, occurrence)。string:代表源字符串(写入字段则表示此字段的内容)。substring:代表想从源字符串中查找的子串。position:代表查找的开始位置,该参数可选的,默认为1。occurrence:代表想从源字符中查找出第几次出现的substring,该参数也是可选的,默认为1。position 的值为负数,那么代表从右往左进行查找。instr和like的性能比较其实从效率角度来看,谁能用到索引,谁的查询速度就会快。like有时可以用到索引,例如:name like ‘李%’,而当下面的情况时索引会失效:name like ‘%李’。所以一般我们查找中文类似于‘%字符%’时,索引都会失效。与其他数据库不同的是,oracle支持函数索引。例如在name字段上建个instr索引,查询速度就比较快了,这也是为什么instr会比like效率高的原因。注:instr(title,’手册’)>0 相当于like‘%手册%’instr(title,’手册’)=0 相当于not like‘%手册%’Oracle Text 索引原理 Oracle text 索引将文本中所有的字符转化成记号(token),如 www.taobao.com 会转化 成 www,taobao,com 这样的记号。
Oracle10g 里面支持四种类型的索引:context、ctxcat、ctxrule、ctxxpath
CONTEXT 用于对含有大量连续文本数据进行检索。支持 word、html、xml、text 等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType. DML 操作后,需要 CTX_DDL.SYNC_INDEX 手工同步索引 如果有查询包含多个词语,直接用空格隔开(如 oracle itpub) 案例分析:设置全文检索步骤步骤一:检查和设置数据库角色 首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能(10G默认安装都有此用户和角色)。你必须修改数据库以安装这项功能。默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys的用户。
[b;'>basic_lexer:
针对英语。它能根据空格和标点来将英语单词从句子中分离,还能自动将一些出现频率过高已经失去检索意义的单词作为‘垃圾’处理,如if,is等,具有较高的处理效率。但该lexer应用于汉语则有很多问题,由于它只认空格和标点,而汉语的一句话中通常不会有空格,因此,它会把整句话作为一个term,事实上失去检索能力。以‘中国人民站起来了’这句话为例,basic_lexer分析的结果只有一个term,就是‘中国人民站起来了’。此时若检索‘中国’,将检索不到内容。
chinese_vgram_lexer:
专门的汉语分析器,支持所有汉字字符集(ZHS16CGB231280 ZHS16GBK ZHT32EUC ZHT16BIG5 ZHT32TRIS ZHT16MSWIN950 ZHT16HKSCS UTF8 )。该分析器按字为单元来分析汉语句子。‘中国人民站起来了’这句话,会被它分析成如下几个term:‘中’,‘中国’,‘国人’,‘人民’,‘民站’,‘站起’,起来’,‘来了’,‘了’。可以看出,这种分析方法,实现算法很简单,并且能实现‘一网打尽’,但效率则是差强人意。
chinese_lexer:
这是一个新的汉语分析器,只支持utf8字符集。上面已经看到,chinese vgram lexer这个分析器由于不认识常用的汉语词汇,因此分析的单元非常机械,像上面的‘民站’,‘站起’在汉语中根本不会单独出现,因此这种term是没有意义的,反而影响效率。chinese_lexer的最大改进就是该分析器能认识大部分常用汉语词汇,因此能更有效率地分析句子,像以上两个愚蠢的单元将不会再出现,极大提高了效率。但是它只支持utf8,如果你的数据库是zhs16gbk字符集,则只能使用笨笨的那个Chinese vgram lexer。如果不做任何设置,Oracle缺省使用basic_lexer这个分析器。
12:05:01 SYS@ prod >select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
AMERICAN_AMERICA.ZHS16GBK
12:08:05 SCOTT@ prod >desc ctx_ddl
PROCEDURE CREATE_PREFERENCE
Argument Name Type In/Out Default?
------------------------------ ----------------------- ------ --------
PREFERENCE_NAME VARCHAR2 IN
OBJECT_NAME VARCHAR2 IN
12:12:25 SCOTT@ prod >EXEC ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
PL/SQL procedure successfully completed.
创建表
12:13:15 SCOTT@ prod >CREATE TABLE textdemo(
12:15:47 2 id NUMBER NOT NULL PRIMARY KEY,
12:15:47 3 book_author varchar2(100),--作者
12:15:47 4 publish_time DATE,--发布日期
12:15:47 5 title varchar2(400),--标题
12:15:47 6 book_abstract varchar2(2000),--摘要
12:15:47 7 path varchar2(200)--路径
12:15:47 8 );
Table created.[code]插入数据14:53:20 SCOTT@ prod >insert into textdemo values (10,'luyao',sysdate,'pingfan de world','zhen shi de gushi','/home/1.txt');
1 row created.
14:54:32 SCOTT@ prod >commit;SELECT * FROM ctx_USER_index_errors
附:对于建立索引的类型(例如ctxsys.context),包括四种:context,ctxcat,ctxrule,ctxxpath。
CONTEXT用于对含有大量连续文本数据进行检索。支持word、html、xml、text等很多数据格式。支持范围(range)分区,支持并行创建索引(Parallel indexing)的索引类型。
支持类型:VARCHAR2, CLOB, BLOB, CHAR, BFILE, XMLType, and URIType.DML。操作后,需要CTX_DDL.SYNC_INDEX手工同步索引如果有查询包含多个词语,直接用空格隔开(如 oracle itpub)。
查询标识符CONTAINS
CTXCAT适用于混合查询语句(如查询条件包括产品id,价格,描述等)。适合于查询较小的具有一定结构的文本段。具有事务性。DML 操作后,索引会自动进行同步。
操作符:and,or,>,;<, =,between,in
查询标识符CATSEARCH
CTXRULE查询标识符MATCHES。
CTXXPATH(这两个索引没有去更多搜索相关内容)
一般来说我们建立CONTEXT类型的索引(CONTAINS来查询)。[b]15:19:21 SCOTT@ prod >insert into textdemo values (20,'huoda',sysdate,'musilin de zangli','meili de rensheng','/home/2.txt');
1 row created.
15:20:10 SCOTT@ prod >commit;
15:21:35 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where BOOK_ABSTRACT like '%rensheng%'
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng
15:23:12 SCOTT@ prod >set autotrace on
15:23:38 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0
no rows selected
Execution Plan
----------------------------------------------------------
Plan hash value: 2570915478
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1027 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEXTDEMO | 1 | 1027 | 4 (0)| 00:00:01 |
|* 2 | DOMAIN INDEX | DEMO_ABSTRACT | | | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("CTXSYS"."CONTAINS"("BOOK_ABSTRACT",'rensheng')>0)
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
23 recursive calls
0 db block gets
33 consistent gets
0 physical reads
0 redo size
349 bytes sent via SQL*Net to client
404 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
0 rows processed
15:26:40 SYS@ prod >select * from ctxsys.dr$pending;
PND_CID PND_PID PND_ROWID PND_TIMES P
---------- ---------- ------------------ --------- -
1082 0 AAASrlAAEAAAAI1AAB 21-NOV-14 N
15:26:26 SCOTT@ prod >alter index demo_abstract rebuild parameters('sync');
Index altered.
15:30:10 SCOTT@ prod >select id,BOOK_ABSTRACT from textdemo where contains(BOOK_ABSTRACT,'rensheng')>0;
ID BOOK_ABSTRACT
---------- --------------------------------------------------
20 meili de rensheng

相关文章推荐
- 通过案例学调优之--Oracle 全文索引
- 通过案例学调优之--Oracle中null使用索引
- 通过案例学调优之--Oracle中null使用索引
- 通过案例学调优之--Oracle Cluster Table
- 通过案例学调优之--Oracle参数(db_file_multiblock_read_count)
- 通过案例学调优之--分区表索引
- 通过案例学调优之--Oracle Time Model(时间模型)
- 通过案例学调优之--Oracle Latch基础知识
- 通过案例学调优之--Oracle ADDM
- 通过案例学调优之--Oracle数据块(block)
- 通过案例学调优之--Oracle ADDM
- 通过案例学调优之--Oracle Cluster Table
- 通过案例学调优之--Oracle Time Model(时间模型)
- 通过案例学调优之--Oracle参数(db_file_multiblock_read_count)
- 通过案例学调优之--Oracle Time Model(时间模型)
- 通过案例学调优之--Oracle Latch基础知识
- 通过案例学调优之--Oracle数据块(block)
- [Oracle] 一个通过添加本地分区索引提高SQL性能的案例
- 【Oracle】转:通过案例学调优之--Oracle Time Model(时间模型)
- 通过案例学调优之--分区表索引