通过案例学调优之--Oracle参数(db_file_multiblock_read_count)
2014-08-21 17:15
513 查看
通过案例学调优之--Oracle参数(db_file_multiblock_read_count)应用环境:操作系统: RedHat EL55Oracle: Oracle 10gR2 Oracle DB_FILE_MULTIBLOCK_READ_COUNT是Oracle比较重要的一个全局性参数,可以影响系统级别及sessioin级别。主要是用于设置最小化表扫描时Oracle一次按顺序能够读取的数据块数。通常情况下,我们看到top events中的等待事件db file scattered read时会考虑到增加该参数的值。
1、参数DB_FILE_MULTIBLOCK_READ_COUNT(MBRC)
参数DB_FILE_MULTIBLOCK_READ_COUNT简写为(MBRC)。
该参数是最小化表扫描的重要参数,用于指定Oracle一次按顺序能够读取的数据块数。理论上该值越大则能够读取的数据块越多。
实现全表扫描,索引全扫描及索引快速扫描所需的I/O总数取决于该参数,以及表自身的大小,是否使用并行等等。
Oracle 10gR2以后会根据相应的操作系统及buffer cache以最优化的方式来自动设定该参数的值。通常情况下该值为1MB/db_block_size。
在最大I/O为1MB的情况下,block的大小为8KB,则参数的值为128。如果在最大I/O为64KB,block为8KB,则参数的值为8。
对于OLTP和batch环境该参数的值为4到16,DSS环境应设置大于16以上或大的值。
该参数的变化对数据库性能产生整体性的影响,过大的设置会导致大量SQL访问路径发生变化,如原先的索引扫描倾向于使用全表扫描。
按照Oracle的建议在10g R2之后尽可能使用oracle自动设置的值。2、参数DB_FILE_MULTIBLOCK_READ_COUNT与SSTIOMAX
In Release 9.2 and above; follow the explanation below:
Each version of Oracle on each port, is shipped with a preset maximum of how much data can be transferred in a single read (which of course is equivalent to the db_file_multiblock_read_count since the block size is fixed).
For 8i and above (on most platforms) this is 1Mb and is referred to as SSTIOMAX.
To determine it for your port and Oracle version, simply set db_file_multiblock_read_count to a nonsensical value and Oracle will size it down for you.
从上面的描述可知,Oracle 9.2之后,有一个名叫SSTIOMAX的东东,限制了MBRC的设置。
由于SSTIOMAX大多数平台最大单次I/O为1MB,db_block_size为8kb,因此MBRC参数的最大值通常为128。128*8kb=1mb。
对于设置大于1MB的情形,即MBRC*db_block_size>SSTIOMAX的情形,则设置的值并不生效,而是使用符合SSTIOMAX的最大MBRC值。3、如何计算MBRC
The formula as internally used is as below:
db_file_multiblock_read_count = min(1048576/db_block_size , db_cache_size/(sessions * db_block_size))
设置DB_FILE_MULTIBLOCK_READ_COUNT以充分利用操作系统I/O缓冲区的大小。应考虑DB_FILE_MULTIBLOCK_READ_COUNT <= 操作系统I/O缓冲区 / Oracle Block的大小,如果DB_FILE_MULTIBLOCK_READ_COUNT设置的太大,会使优化器认为全表扫描更有效而改变执行计划,然后实际情况并非如此。 如果必须创建小的区间,创建其大小是操作系统I/O缓冲区大小的整数倍 设置区间尺寸大小的考虑思路应该是合理的利用Oracle的能力以便在全表扫描时执行多块存取,同时读操作又是不能跨区间的。举个例子,假设操作系统I/O缓冲区大小是64KB,考察读取一个640KB大小的表,如果设置为每个区间64KB,一共10个区间,如果执行全表扫描,则Oracle需要10次读操作(相当于一次读一个区间);如果设置为一个640KB的区间,则Oracle还是需要10次读操作(因为操作系统I/O缓冲区大小是64KB),可见压缩区间并不能提高性能;如果设置为每个区间80KB,一共8个区间,则每个区间Oracle需要读两次,第一次读64KB,第二次读这个区间剩余的16KB(读操作不能跨区间),所以总共需要16次读操作(相当于一次读一个区间)。区间尺寸的设置对性能的影响是显而易见的。
案例分析:
案例1
15:21:10 SYS@ test1 >show parameter mult
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128
1)查看表中extent分配
14:46:03 SCOTT@ test1 >col segment_name for a2014:46:15 SCOTT@ test1 >select segment_name,extent_id,bytes,blocks from user_extents14:46:36 2 where segment_name='T1';
15:21:10 SYS@ test1 >show parameter multNAME TYPE VALUE------------------------------------ ----------- ------------------------------db_file_multiblock_read_count integer 128
1)创建新的segment
15:08:28 SCOTT@ test1 >create table t2 (id int)15:08:35 2 storage (initial 2048k next 2048k pctincrease 0);Table created.15:08:41 SCOTT@ test1 >col segment_name for a2015:08:53 SCOTT@ test1 >select segment_name,tablespace_name,extent_id,bytes,blocks from user_extents15:09:19 2 where segment_name='T2';
附注:


本文出自 “天涯客的blog” 博客,请务必保留此出处http://tiany.blog.51cto.com/513694/1543199
1、参数DB_FILE_MULTIBLOCK_READ_COUNT(MBRC)
参数DB_FILE_MULTIBLOCK_READ_COUNT简写为(MBRC)。
该参数是最小化表扫描的重要参数,用于指定Oracle一次按顺序能够读取的数据块数。理论上该值越大则能够读取的数据块越多。
实现全表扫描,索引全扫描及索引快速扫描所需的I/O总数取决于该参数,以及表自身的大小,是否使用并行等等。
Oracle 10gR2以后会根据相应的操作系统及buffer cache以最优化的方式来自动设定该参数的值。通常情况下该值为1MB/db_block_size。
在最大I/O为1MB的情况下,block的大小为8KB,则参数的值为128。如果在最大I/O为64KB,block为8KB,则参数的值为8。
对于OLTP和batch环境该参数的值为4到16,DSS环境应设置大于16以上或大的值。
该参数的变化对数据库性能产生整体性的影响,过大的设置会导致大量SQL访问路径发生变化,如原先的索引扫描倾向于使用全表扫描。
按照Oracle的建议在10g R2之后尽可能使用oracle自动设置的值。2、参数DB_FILE_MULTIBLOCK_READ_COUNT与SSTIOMAX
In Release 9.2 and above; follow the explanation below:
Each version of Oracle on each port, is shipped with a preset maximum of how much data can be transferred in a single read (which of course is equivalent to the db_file_multiblock_read_count since the block size is fixed).
For 8i and above (on most platforms) this is 1Mb and is referred to as SSTIOMAX.
To determine it for your port and Oracle version, simply set db_file_multiblock_read_count to a nonsensical value and Oracle will size it down for you.
从上面的描述可知,Oracle 9.2之后,有一个名叫SSTIOMAX的东东,限制了MBRC的设置。
由于SSTIOMAX大多数平台最大单次I/O为1MB,db_block_size为8kb,因此MBRC参数的最大值通常为128。128*8kb=1mb。
对于设置大于1MB的情形,即MBRC*db_block_size>SSTIOMAX的情形,则设置的值并不生效,而是使用符合SSTIOMAX的最大MBRC值。3、如何计算MBRC
The formula as internally used is as below:
db_file_multiblock_read_count = min(1048576/db_block_size , db_cache_size/(sessions * db_block_size))
设置DB_FILE_MULTIBLOCK_READ_COUNT以充分利用操作系统I/O缓冲区的大小。应考虑DB_FILE_MULTIBLOCK_READ_COUNT <= 操作系统I/O缓冲区 / Oracle Block的大小,如果DB_FILE_MULTIBLOCK_READ_COUNT设置的太大,会使优化器认为全表扫描更有效而改变执行计划,然后实际情况并非如此。 如果必须创建小的区间,创建其大小是操作系统I/O缓冲区大小的整数倍 设置区间尺寸大小的考虑思路应该是合理的利用Oracle的能力以便在全表扫描时执行多块存取,同时读操作又是不能跨区间的。举个例子,假设操作系统I/O缓冲区大小是64KB,考察读取一个640KB大小的表,如果设置为每个区间64KB,一共10个区间,如果执行全表扫描,则Oracle需要10次读操作(相当于一次读一个区间);如果设置为一个640KB的区间,则Oracle还是需要10次读操作(因为操作系统I/O缓冲区大小是64KB),可见压缩区间并不能提高性能;如果设置为每个区间80KB,一共8个区间,则每个区间Oracle需要读两次,第一次读64KB,第二次读这个区间剩余的16KB(读操作不能跨区间),所以总共需要16次读操作(相当于一次读一个区间)。区间尺寸的设置对性能的影响是显而易见的。
案例分析:
案例1
15:21:10 SYS@ test1 >show parameter mult
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128
1)查看表中extent分配
14:46:03 SCOTT@ test1 >col segment_name for a2014:46:15 SCOTT@ test1 >select segment_name,extent_id,bytes,blocks from user_extents14:46:36 2 where segment_name='T1';
SEGMENT_NAME EXTENT_ID BYTES BLOCKS -------------------- ---------- ---------- ---------- T1 0 65536 8 T1 1 65536 8 T1 2 65536 8 T1 3 65536 8 T1 4 65536 8 T1 5 65536 8 T1 6 65536 8 T1 7 65536 8 T1 8 65536 8 T1 9 65536 8 T1 10 65536 8 T1 11 65536 8 T1 12 65536 8 T1 13 65536 8 T1 14 65536 8 T1 15 65536 8 T1 16 1048576 128 SEGMENT_NAME EXTENT_ID BYTES BLOCKS -------------------- ---------- ---------- ---------- T1 17 1048576 128 T1 18 1048576 128 T1 19 1048576 128 T1 20 1048576 128 T1 21 1048576 128 22 rows selected.2)配置10046进行分析
14:48:00 SCOTT@ test1 >alter session set events '10046 trace name context forever,level 8'; Session altered. 14:48:57 SCOTT@ test1 >select count(*) from t1; COUNT(*) ---------- 5002 14:49:09 SCOTT@ test1 >alter session set events '10046 trace name context off'; Session altered.3)查看trace文件[oracle@rh6 ~]$ more /u01/app/oracle/diag/rdbms/test1/test1/trace/test1_ora_4160.trc
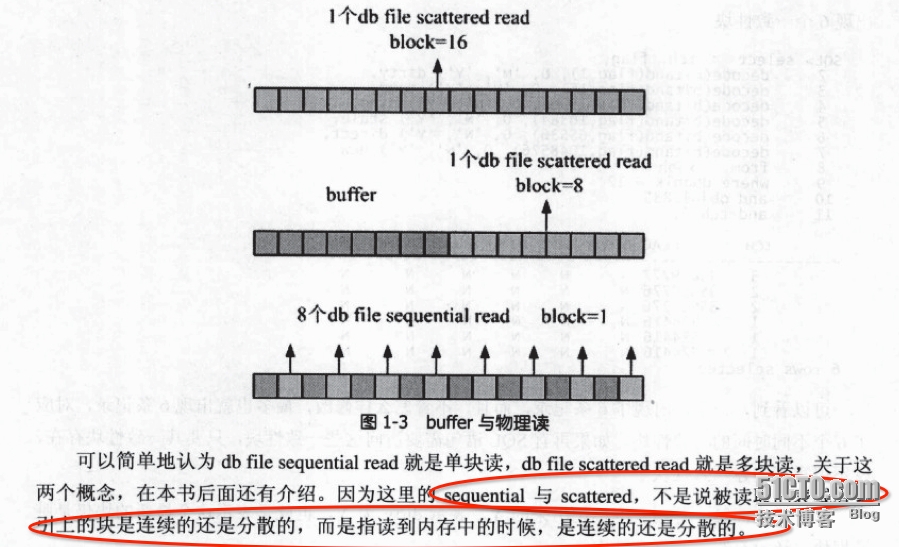
WAIT #2: nam='db file sequential read' ela= 9 file#=11 block#=691 blocks=1 obj#=16394 tim=1408604404294713 WAIT #2: nam='Disk file operations I/O' ela= 26 FileOperation=2 fileno=4 filetype=2 obj#=16394 tim=1408604404294846 WAIT #2: nam='db file sequential read' ela= 9 file#=4 block#=143 blocks=1 obj#=16394 tim=1408604404294872 WAIT #2: nam='db file scattered read' ela= 23 file#=4 block#=157 blocks=3 obj#=16394 tim=1408604404294998 WAIT #2: nam='db file sequential read' ela= 8 file#=4 block#=164 blocks=1 obj#=16394 tim=1408604404295041 WAIT #2: nam='db file sequential read' ela= 8 file#=11 block#=727 blocks=1 obj#=16394 tim=1408604404295069 WAIT #2: nam='db file sequential read' ela= 8 file#=4 block#=183 blocks=1 obj#=16394 tim=1408604404295097 WAIT #2: nam='db file scattered read' ela= 33 file#=4 block#=187 blocks=5 obj#=16394 tim=1408604404295156 WAIT #2: nam='db file sequential read' ela= 8 file#=4 block#=199 blocks=1 obj#=16394 tim=1408604404295191 WAIT #2: nam='db file scattered read' ela= 51 file#=11 block#=153 blocks=8 obj#=16394 tim=1408604404295272 WAIT #2: nam='db file scattered read' ela= 50 file#=11 block#=203 blocks=8 obj#=16394 tim=1408604404295355 WAIT #2: nam='db file scattered read' ela= 52 file#=11 block#=213 blocks=8 obj#=16394 tim=1408604404295442 ......从以上文件可以看出,在“db file scattered read”中每次读取的数据块个数(blocks=8)不超过extent中blocks的大小(8个);在“db file sequential read”中每次读取的数据块个数(blocks)为1个。案例2:
15:21:10 SYS@ test1 >show parameter multNAME TYPE VALUE------------------------------------ ----------- ------------------------------db_file_multiblock_read_count integer 128
1)创建新的segment
15:08:28 SCOTT@ test1 >create table t2 (id int)15:08:35 2 storage (initial 2048k next 2048k pctincrease 0);Table created.15:08:41 SCOTT@ test1 >col segment_name for a2015:08:53 SCOTT@ test1 >select segment_name,tablespace_name,extent_id,bytes,blocks from user_extents15:09:19 2 where segment_name='T2';
SEGMENT_NAME TABLESPACE_NAME EXTENT_ID BYTES BLOCKS -------------------- ------------------------------ ---------- ---------- ---------- T2 USERS 0 1048576 128 T2 USERS 1 1048576 1282)配置10046进行分析
15:11:00 SCOTT@ test1 >alter session set events '10046 trace name context forever,level 8'; Session altered. 15:14:57 SCOTT@ test1 >select count(*) from t2; COUNT(*) ---------- 32002 15:15:09 SCOTT@ test1 >alter session set events '10046 trace name context off'; Session altered.3)查看trace文件[oracle@rh6 ~]$ more /u01/app/oracle/diag/rdbms/test1/test1/trace/test1_ora_4260.trc
PARSE #5:c=0,e=302,p=0,cr=0,cu=0,mis=1,r=0,dep=1,og=1,plh=0,tim=1408605696796384 EXEC #5:c=1000,e=1131,p=0,cr=0,cu=0,mis=1,r=0,dep=1,og=1,plh=3321871023,tim=1408605696797594 WAIT #5: nam='db file sequential read' ela= 75 file#=11 block#=512 blocks=1 obj#=16404 tim=1408605696797838 WAIT #5: nam='db file sequential read' ela= 15 file#=11 block#=514 blocks=1 obj#=16404 tim=1408605696797913 WAIT #5: nam='db file scattered read' ela= 1123 file#=11 block#=528 blocks=48 obj#=16404 tim=1408605696799202从以上文件可以看出,在“db file scattered read”中每次读取的数据块个数(blocks=48)不超过extent中blocks的大小(128个);在“db file sequential read”中每次读取的数据块个数(blocks)为1个。
附注:
本文出自 “天涯客的blog” 博客,请务必保留此出处http://tiany.blog.51cto.com/513694/1543199

相关文章推荐
- 通过案例学调优之--Oracle参数(db_file_multiblock_read_count)
- oracle DB_FILE_MULTIBLOCK_READ_COUNT参数和区间尺寸的设置
- oracle中的db_file_multiblock_read_count参数
- oracle参数-db_file_multiblock_read_count
- db_file_multiblock_read_count and Oracle IO size
- 共享SQL区、私有SQL区与游标 (提到参数DB_FILE_MULTIBLOCK_READ_COUNT)
- oracle DB_FILE_MULTIBLOCK_READ_COUNT
- 讨论一下DB_FILE_MULTIBLOCK_READ_COUNT参数和区间尺寸的设置问题
- 考量参数DB_FILE_MULTIBLOCK_READ_COUNT的脚本
- db_file_multiblock_read_count参数设置取值测试
- Oracle 11g通过提高IO吞吐量(修改_db_file_optimizer_read_count)来优化全表扫描
- 使用 db_file_multiblock_read_count测试Oracle在不同系统中的IO能力
- 关于参数db_file_multiblock_read_count与_db_file_optimizer_read_count
- Oracle 11g通过提高IO吞吐量(修改_db_file_optimizer_read_count)来优化全表扫描
- Why Change the Oracle DB_FILE_MULTIBLOCK_READ_COUNT?
- Oracle db_file_mulitblock_read_count参数
- Oracle db_file_mulitblock_read_count参数
- Oracle 10R2 研究--db_file_multiblock_read_count对成本的影响
- db_file_multiblock_read_count的研究
- stripe /block size/db_file_multiblock_read_count