基于词汇树的图像检索(一):词汇树
2015-03-29 09:48
585 查看
从今天起准备把我的毕设的实现细节写到博客里面,一方面写一遍加深记忆,另一方面如果哪天忘记了查起来也方便
毕设题目是基于词汇树的无序图像集检索和支撑结构生成,其实提出词汇树那篇文章(Scalable Recognition with a Vocabulary Tree[1])已经是2006年的了,算是很老的文章,但是在大规模二三维重建的过程中快速的图像检索还是有意义的。
今天算是把整个程序怎么写彻底想通了,果然不能没有彻底相同就开始写代码。用力过猛容易闪着腰【高三暑假TAT
这个程序大概是这么个流程:(记录一下,无论是实验室寝室还是公司都可以查,不用老是带着那张草稿纸了)
1. 所有图像提特征(已经实现)
2. 建树(输入:所有特征,特征个数) (已经实现)
3. 将训练集图像转换成TF-IDF向量 (最麻烦的部分,正在写)
(1) 计算树中每个节点的IDF值 (输入:所有特征,一个记录每张图有多少特征的一位数组)
(2) 计算每张图的TF-IDF向量 (输入:指向起始特征的指针,特征数目)
(3) 将TF-IDF向量和对应的图像路径写入数据结构 (输入:TF-IDF向量和图像路径)
4. 查询
(1) 计算查询图像的TF-IDF向量 (输入:查询图像路径)
(2) 找到距离最近的数据库图像 (已经实现)
今天先说下什么叫做词汇树。
首先介绍一个概念叫做视觉单词,视觉单词的提出是基于bag of words模型的。首先对于数据集的图像提取sift特征。sift特征在图像描述方面是应用最为广泛的一种特征,由David Lowe在1999年提出,于2004年完善。sift特征得到的结果是,对于图像上的每一个兴趣点都得到一个128维的描述向量(图上有多少兴趣点,兴趣点的分布都由算法本身决定)。然后通过kmeans聚类得到k个聚类中心,这些聚类中心就是我们所说的视觉单词,因为这些聚类中心代表了一类具有共同特点的特征。描述一张图上的视觉单词的分布也是描述这张图的方法之一。如果某只想看更加详细的解释可以参考http://blog.csdn.net/abcjennifer/article/details/7639681(sift)
http://www.cnblogs.com/v-July-v/archive/2011/06/20/2091170.html(bag of words模型)

sift特征示意图,来源:http://blog.csdn.net/abcjennifer/article/details/7639681
之前我也写过基于视觉单词的图像检索,其实就是聚类出来很多视觉单词,然后对于每张图像计算这些视觉单词出现频率的直方图,然后计算直方图之间的距离来比较图像之间的相似度(具体的细节我会在之后的博文中继续更)。实验结果表明随着视觉单词个数的增加检索的结果会变好,词汇树的思路其实就是尽力增加视觉单词的个数。我当时写的是只有1000个单词的图像检索,但是词汇树将节点数增加到了10^6这个数量级。
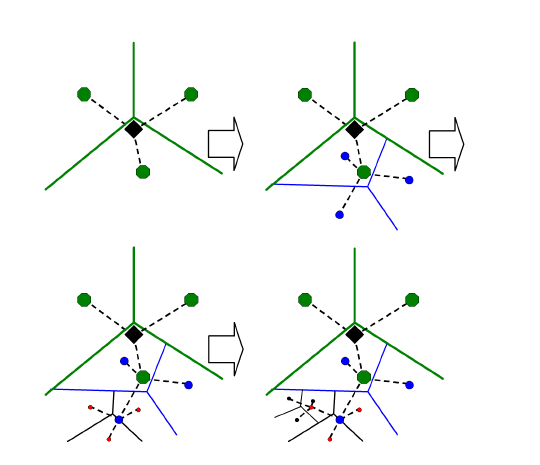
词汇树的基本思想是利用层次kmeans得到尽可能多的特征。层次kmeans的意思是将空间中的点用普通kmeans得到k个聚类中心,每个点都属于一个聚类中心代表的类。对于一类中的所有点,再递归的进行kmeans,直到获得我们想要的聚类中心个数。这样的聚类方法相比普通kmeans聚类可以得到更多的聚类中心,同时花费的时间更加少。原文中和我实现的kmeans聚类中k=10,一共进行6层聚类,这样可以得到10的6次方个聚类中心。这样的聚类实际上得到了一个6层的10叉树,这棵树中保存了视觉单词,所以我们叫他词汇树。
词汇树的示意图(图来自于原文,k = 3,也就是一层聚类仅仅聚类出3个中心点)
引用文献:
[1]Nister, David, and Henrik Stewenius. "Scalable recognition with a vocabulary tree." CVPR,2006
[2]Lowe, David G. "Object recognition
from local scale-invariant features."Computer vision, 1999. The proceedings of the seventh IEEE international conference on.
Vol. 2. Ieee, 1999.
[3]Lowe,
David G. "Distinctive image features from scale-invariant keypoints."IJCV,2004
毕设题目是基于词汇树的无序图像集检索和支撑结构生成,其实提出词汇树那篇文章(Scalable Recognition with a Vocabulary Tree[1])已经是2006年的了,算是很老的文章,但是在大规模二三维重建的过程中快速的图像检索还是有意义的。
今天算是把整个程序怎么写彻底想通了,果然不能没有彻底相同就开始写代码。用力过猛容易闪着腰【高三暑假TAT
这个程序大概是这么个流程:(记录一下,无论是实验室寝室还是公司都可以查,不用老是带着那张草稿纸了)
1. 所有图像提特征(已经实现)
2. 建树(输入:所有特征,特征个数) (已经实现)
3. 将训练集图像转换成TF-IDF向量 (最麻烦的部分,正在写)
(1) 计算树中每个节点的IDF值 (输入:所有特征,一个记录每张图有多少特征的一位数组)
(2) 计算每张图的TF-IDF向量 (输入:指向起始特征的指针,特征数目)
(3) 将TF-IDF向量和对应的图像路径写入数据结构 (输入:TF-IDF向量和图像路径)
4. 查询
(1) 计算查询图像的TF-IDF向量 (输入:查询图像路径)
(2) 找到距离最近的数据库图像 (已经实现)
今天先说下什么叫做词汇树。
首先介绍一个概念叫做视觉单词,视觉单词的提出是基于bag of words模型的。首先对于数据集的图像提取sift特征。sift特征在图像描述方面是应用最为广泛的一种特征,由David Lowe在1999年提出,于2004年完善。sift特征得到的结果是,对于图像上的每一个兴趣点都得到一个128维的描述向量(图上有多少兴趣点,兴趣点的分布都由算法本身决定)。然后通过kmeans聚类得到k个聚类中心,这些聚类中心就是我们所说的视觉单词,因为这些聚类中心代表了一类具有共同特点的特征。描述一张图上的视觉单词的分布也是描述这张图的方法之一。如果某只想看更加详细的解释可以参考http://blog.csdn.net/abcjennifer/article/details/7639681(sift)
http://www.cnblogs.com/v-July-v/archive/2011/06/20/2091170.html(bag of words模型)
sift特征示意图,来源:http://blog.csdn.net/abcjennifer/article/details/7639681
之前我也写过基于视觉单词的图像检索,其实就是聚类出来很多视觉单词,然后对于每张图像计算这些视觉单词出现频率的直方图,然后计算直方图之间的距离来比较图像之间的相似度(具体的细节我会在之后的博文中继续更)。实验结果表明随着视觉单词个数的增加检索的结果会变好,词汇树的思路其实就是尽力增加视觉单词的个数。我当时写的是只有1000个单词的图像检索,但是词汇树将节点数增加到了10^6这个数量级。
词汇树的基本思想是利用层次kmeans得到尽可能多的特征。层次kmeans的意思是将空间中的点用普通kmeans得到k个聚类中心,每个点都属于一个聚类中心代表的类。对于一类中的所有点,再递归的进行kmeans,直到获得我们想要的聚类中心个数。这样的聚类方法相比普通kmeans聚类可以得到更多的聚类中心,同时花费的时间更加少。原文中和我实现的kmeans聚类中k=10,一共进行6层聚类,这样可以得到10的6次方个聚类中心。这样的聚类实际上得到了一个6层的10叉树,这棵树中保存了视觉单词,所以我们叫他词汇树。
词汇树的示意图(图来自于原文,k = 3,也就是一层聚类仅仅聚类出3个中心点)
引用文献:
[1]Nister, David, and Henrik Stewenius. "Scalable recognition with a vocabulary tree." CVPR,2006
[2]Lowe, David G. "Object recognition
from local scale-invariant features."Computer vision, 1999. The proceedings of the seventh IEEE international conference on.
Vol. 2. Ieee, 1999.
[3]Lowe,
David G. "Distinctive image features from scale-invariant keypoints."IJCV,2004

相关文章推荐
- 基于词汇树的图像检索
- CBIR: Indexing and Retrieval--基于内容的图像检索:索引和检索
- 基于图像内容检索学习笔记
- 深度学习与计算机视觉(11)_基于deep learning的快速图像检索系统
- 深度学习用于基于内容的图像检索 Deep Learning for Content-Based Image Retrieval
- 数字图像处理 基于内容的图象与视频检索
- 基于内容的图像检索CBIR部分数据库和源代码资料
- 再收集一下基于内容图像检索系统
- 基于HSV分块颜色直方图的图像检索算法
- 数字图像处理:第二十三章 基于内容的图象与视频检索
- 图像检索:几类基于内容的图像分类技术
- 基于内容的图像检索引擎(以图搜图)
- 基于内容的图像检索 Database for Content-Based Image Retrieval
- 基于一种改进的提取形状特征向量方法,实现图像检索
- 基于神经网络的图像检索 Neural Codes for Image Retrieval
- 基于颜色布局描述符的图像检索
- 图像检索:基于内容的图像检索技术
- 图像检索:几类基于内容的图像分类技术
- 图像检索:基于形状特征的算法
- (转载)几个基于内容图像检索系统