程序怎么跑?(2)——linux课程学习笔记
2015-03-11 20:20
375 查看
在这篇文章我们将会讨论操作系统内的进程调度是如何实现的。这里我们用的系统是一个精简版的linux内核,这个内核如此精简,它只做两件事,1,运行一些进程。2,在这些进程之间切换。
kernel介绍
kernel代码由孟宁老师完成,本人在代码对其代码进行了有限的修改,这些修改主要是删除几句没有必要而且可能影响代码理解的内联汇编,使代码更加容易理解。
kernel只有三个文件,分别是mymain.c,myinterupt.c,mypcb.h。
mymain.c文件中为包含kernel启动的函数,进程函数。

myinterupt.c 内容为时钟中断处理函数与调度函数。
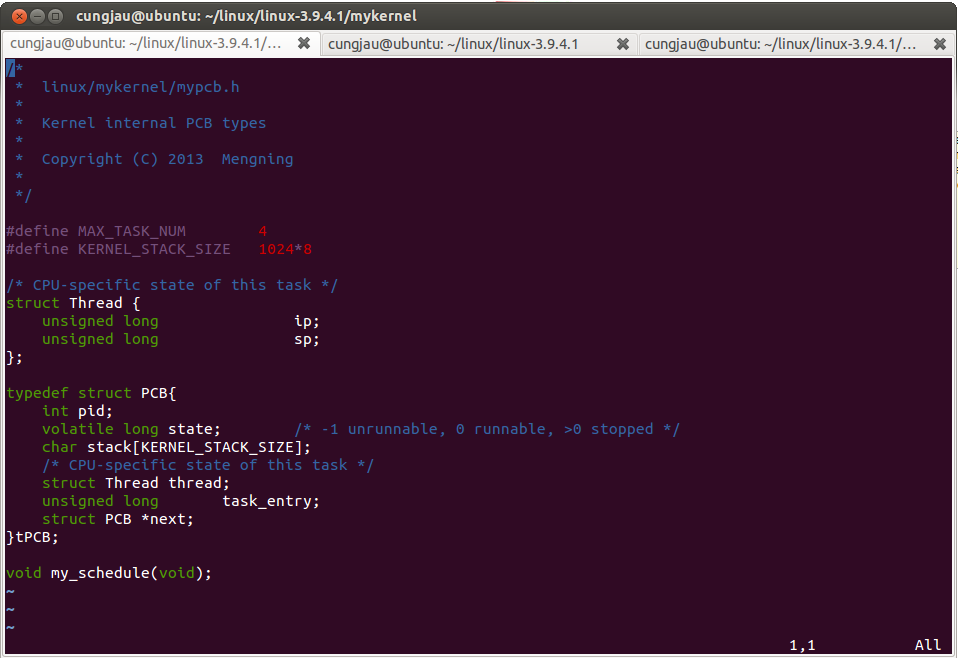
mypch.h内容为记录进程执行的数据结构thread,和用于调度的辅助结构pcb。
运行情况
环境的搭建参考https://github.com/mengning/mykernel
我的系统环境是一个运行在vmware上ubuntu12.04,qemu命令需要更换成qemu-system-x86_64
即运行模拟器时使用的命令是
qemu-system-x86_64 -kernel arch/x86/boot/bzImage
运行效果:

代码分析&运行模拟
两个数据结构
struct Thread {
unsigned longip;
unsigned longsp;
};
typedef struct PCB{
int pid;
volatile long state;/* -1 unrunnable, 0 runnable, >0 stopped */
char stack[KERNEL_STACK_SIZE];
/* CPU-specific state of this task */
struct Thread thread;
unsigned longtask_entry;
struct PCB *next;
}tPCB;
Thread 结构体记录了进程的运行状态,具体内容是运行的eip和esp
PCB 进程控制块,用于辅助内核组织和调度各个进程,
运行模拟
1.my_start_kernel是内核的入口,
系统启动后,首先进行的0号进程的创建,即往进程控制块中填入进程的运行信息,包括设置pid,设置运行状态,my_process为进程真正做的工作,所以进程入口地址被设置为my_process,设置初始的栈顶地址和下一个进程的pcb地址。
具体如下过程:
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];
然后是根据0号进程创建其余三个一样的进程。包括0号进程的四个所做的事情都是一样的,所以可以直接使用memcpy复制进程。然后修改pcb中的next域以将各进程依次链接起来。
for(i=1;i<MAX_TASK_NUM;i++)
{
memcpy(&task[i],&task[0],sizeof(tPCB));
task[i].pid = i;
task[i].state = -1;
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1];
task[i].next = task[i-1].next;
task[i-1].next = &task[i];
}
进程创建完成后系统开始运行0号进程。
pid = 0;
my
4000
_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t"/* set task[pid].thread.sp
to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip
*/
"ret\n\t" /* pop task[pid].thread.ip
to eip */
//"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp)/*
input c or d mean %ecx/%edx*/
);
上面代码主要难懂的部分是其中的内联汇编,
movl %1, %%esp 这句的含义是:将第1号(从0号开始)变量内容放入esp中,在整句asm volatile("": : :);语句中,0号变量是 "c" (task[pid].thread.ip),1号变量是"d" (task[pid].thread.sp), 其中变量前的c或d指明这个变量使用前放在ecx或者edx寄存器中。所以这句汇编的作用是,将0号进程的sp(task[pid].thread.sp)放入esp
"movl %1,%%esp\n\t" // 将0号进程的sp(task[pid].thread.sp)放入esp
"pushl %1\n\t" // 0号进程的sp入栈,由于进程没有运行,栈顶和栈底指向同一个地址。
"pushl %0\n\t" // 0号进程的ip入栈,由上面的代码可以知道,ip指向my_process
"ret\n\t" // 弹出ip,也就是弹出上面压栈的my_process 到ebp
此时eip指向my_process,执行完ret指令后,程序将从myprocess 开始执行。下面我们模拟my_process函数的执行。
my_process
void my_process(void)
{
int i = 0;
while(1)
{
i++;
if(i%10000000 == 0)
{
printk(KERN_NOTICE "this is process %d -\n",my_current_task->pid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid);
}
}
}
这些进程开始执行后做的事情主要是不断地循环计数,然后间断地输出自己的进程号找存在感,并主动查看自己是否需要调度。如果需要调度,则调用my_schedule进行调度。
2.my_schedule
next = my_current_task->next;
prev = my_current_task;
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{
/* switch to next process */
asm volatile(
//"pushl %%ebp\n\t" /* save ebp */ 可删除
"movl %%esp,%0\n\t"/* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t" //context of process
"ret\n\t" /* restore eip */
"1:\t" /* next process start here */
//"popl %%ebp\n\t" //可删除
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
}
else
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
/* switch to new process */
asm volatile(
//"pushl %%ebp\n\t" /* save ebp */ 可删除
"movl %%esp,%0\n\t"/* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
prev是将要被调度出的进程,即当前进程,next记录的是将要被调度进的进程,即当前进程的下一个进程,所以通过当前进程的next域找到。
情况一:next进程从来没运行过
假设当前进程是系统运行时启动的0号进程,next的1号进程从么运行过。这次调度时第一次调度。
0号进程的next是1号进程,1号进程从来没有被执行过,他的state被初始化为1,所以if-else循环走的是else分支。
else首先是将next进程也就是1号进程的state设置为0,使得下次调度1号进程的时候能正确处理。
asm volatile(
"movl %%esp,%0\n\t"//保存prev的栈顶
"movl %2,%%esp\n\t" //将esp设置为1号进程的栈顶
"movl %2,%%ebp\n\t" //因为1号进程第一次执行,所以它的ebp和esp相同
"movl $1f,%1\n\t" //1f是标号,指向if语句块中的 "1:\t", 具体原因在后面解释
"pushl %3\n\t"//将next的ip,压栈
"ret\n\t" //ip出栈到eip
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
ret语句执行完后,eip的值等于的1号进程的初始ip,也就是my_process。在ret执行完的时候,ebp,esp,eip都是1号进程的,而之前0号进程的ebp在0号进程my_schedule调用时被压栈保存,esp在调度的时候被保存到0号进程的thread.sp域中,ip域也保存了一个玄乎的地址,这样我们就实现了保存0号进程和执行1号进程的进程调度过程。
从1号进程调度到2号,2号调度到3号过程都是一样的。第一次被调度的进程会从my_process开始执行,然后不断检查自己是否需要调度,如果需要调度,就调度到下一个进程。
情况二:next进程被调度过
假设当前进程是3号进程,next进程是0号进程,0号进程的state是0,所以做if分支
asm volatile(
"movl %%esp,%0\n\t"//将当前esp保存到3号进程的sp中
"movl %2,%%esp\n\t" //将0号进程的sp恢复到esp
"movl $1f,%1\n\t" //将1标号的位置保存到3号进程的ip中
"pushl %3\n\t" //将0号进程的ip压栈,
"ret\n\t" //被压栈的0号进程的ip送到eip,继续执行0号进程
"1:\t" //1标号
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
怎么理解?
由于my_schedule这个函数是被某个特定的进程调用的,所以这个函数虽然只在文件中出现了一次,但是实际上由四个不同的进程所调用的这个函数是各自不同的,有四个。所以进程的执行示意图如下:

对于进程1 号,如果忽略my_schedule函数的调度,它感觉到的是这样的:

稍微需要注意的是内联汇编里面有三句被注释的。
linux实际的kernel源码里面是有这样对应的操作的,因为在实际的kernel中,进程调度的是实现是通过一段宏,而不像是mykernel中的通过my_schedule函数。通过宏,prev的ebp需要手动保存(需要保存?),而通过函数时,prev进程的ebp保存在调用my_schedule函数时就做好了,next的ebp恢复也在my_schedule的返回中完成,所以这两句代码和else中的push %ebp是可以删除。
关于my_timer_handler
void my_timer_handler(void)
{
#if 1
if(time_count%1000 == 0 && my_need_sched != 1)
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_sched = 1;
}
time_count ++ ;
#endif
return;
}
这是对时钟中断的处理函数。每一千次时钟中断就将my_need_sched的值改成1,进程不断运行时检测到my_need_sched的值是1, 就将它改成0,并发生进程调度。
总结:
操作系统的调度程序对进程的现场保存与恢复实现进程之间的切换,调度对于进程而言是透明的,进程并不会感觉到自己被切换。现代操作系统良好的进程调度机制是多任务同时进行的基础。
邱聪
原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
kernel介绍
kernel代码由孟宁老师完成,本人在代码对其代码进行了有限的修改,这些修改主要是删除几句没有必要而且可能影响代码理解的内联汇编,使代码更加容易理解。
kernel只有三个文件,分别是mymain.c,myinterupt.c,mypcb.h。
mymain.c文件中为包含kernel启动的函数,进程函数。
myinterupt.c 内容为时钟中断处理函数与调度函数。
mypch.h内容为记录进程执行的数据结构thread,和用于调度的辅助结构pcb。
运行情况
环境的搭建参考https://github.com/mengning/mykernel
我的系统环境是一个运行在vmware上ubuntu12.04,qemu命令需要更换成qemu-system-x86_64
即运行模拟器时使用的命令是
qemu-system-x86_64 -kernel arch/x86/boot/bzImage
运行效果:
代码分析&运行模拟
两个数据结构
struct Thread {
unsigned longip;
unsigned longsp;
};
typedef struct PCB{
int pid;
volatile long state;/* -1 unrunnable, 0 runnable, >0 stopped */
char stack[KERNEL_STACK_SIZE];
/* CPU-specific state of this task */
struct Thread thread;
unsigned longtask_entry;
struct PCB *next;
}tPCB;
Thread 结构体记录了进程的运行状态,具体内容是运行的eip和esp
PCB 进程控制块,用于辅助内核组织和调度各个进程,
运行模拟
1.my_start_kernel是内核的入口,
系统启动后,首先进行的0号进程的创建,即往进程控制块中填入进程的运行信息,包括设置pid,设置运行状态,my_process为进程真正做的工作,所以进程入口地址被设置为my_process,设置初始的栈顶地址和下一个进程的pcb地址。
具体如下过程:
task[pid].pid = pid;
task[pid].state = 0;/* -1 unrunnable, 0 runnable, >0 stopped */
task[pid].task_entry = task[pid].thread.ip = (unsigned long)my_process;
task[pid].thread.sp = (unsigned long)&task[pid].stack[KERNEL_STACK_SIZE-1];
task[pid].next = &task[pid];
然后是根据0号进程创建其余三个一样的进程。包括0号进程的四个所做的事情都是一样的,所以可以直接使用memcpy复制进程。然后修改pcb中的next域以将各进程依次链接起来。
for(i=1;i<MAX_TASK_NUM;i++)
{
memcpy(&task[i],&task[0],sizeof(tPCB));
task[i].pid = i;
task[i].state = -1;
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE-1];
task[i].next = task[i-1].next;
task[i-1].next = &task[i];
}
进程创建完成后系统开始运行0号进程。
pid = 0;
my
4000
_current_task = &task[pid];
asm volatile(
"movl %1,%%esp\n\t"/* set task[pid].thread.sp
to esp */
"pushl %1\n\t" /* push ebp */
"pushl %0\n\t" /* push task[pid].thread.ip
*/
"ret\n\t" /* pop task[pid].thread.ip
to eip */
//"popl %%ebp\n\t"
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp)/*
input c or d mean %ecx/%edx*/
);
上面代码主要难懂的部分是其中的内联汇编,
movl %1, %%esp 这句的含义是:将第1号(从0号开始)变量内容放入esp中,在整句asm volatile("": : :);语句中,0号变量是 "c" (task[pid].thread.ip),1号变量是"d" (task[pid].thread.sp), 其中变量前的c或d指明这个变量使用前放在ecx或者edx寄存器中。所以这句汇编的作用是,将0号进程的sp(task[pid].thread.sp)放入esp
"movl %1,%%esp\n\t" // 将0号进程的sp(task[pid].thread.sp)放入esp
"pushl %1\n\t" // 0号进程的sp入栈,由于进程没有运行,栈顶和栈底指向同一个地址。
"pushl %0\n\t" // 0号进程的ip入栈,由上面的代码可以知道,ip指向my_process
"ret\n\t" // 弹出ip,也就是弹出上面压栈的my_process 到ebp
此时eip指向my_process,执行完ret指令后,程序将从myprocess 开始执行。下面我们模拟my_process函数的执行。
my_process
void my_process(void)
{
int i = 0;
while(1)
{
i++;
if(i%10000000 == 0)
{
printk(KERN_NOTICE "this is process %d -\n",my_current_task->pid);
if(my_need_sched == 1)
{
my_need_sched = 0;
my_schedule();
}
printk(KERN_NOTICE "this is process %d +\n",my_current_task->pid);
}
}
}
这些进程开始执行后做的事情主要是不断地循环计数,然后间断地输出自己的进程号找存在感,并主动查看自己是否需要调度。如果需要调度,则调用my_schedule进行调度。
2.my_schedule
next = my_current_task->next;
prev = my_current_task;
if(next->state == 0)/* -1 unrunnable, 0 runnable, >0 stopped */
{
/* switch to next process */
asm volatile(
//"pushl %%ebp\n\t" /* save ebp */ 可删除
"movl %%esp,%0\n\t"/* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t" //context of process
"ret\n\t" /* restore eip */
"1:\t" /* next process start here */
//"popl %%ebp\n\t" //可删除
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
}
else
{
next->state = 0;
my_current_task = next;
printk(KERN_NOTICE ">>>switch %d to %d<<<\n",prev->pid,next->pid);
/* switch to new process */
asm volatile(
//"pushl %%ebp\n\t" /* save ebp */ 可删除
"movl %%esp,%0\n\t"/* save esp */
"movl %2,%%esp\n\t" /* restore esp */
"movl %2,%%ebp\n\t" /* restore ebp */
"movl $1f,%1\n\t" /* save eip */
"pushl %3\n\t"
"ret\n\t" /* restore eip */
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
}
prev是将要被调度出的进程,即当前进程,next记录的是将要被调度进的进程,即当前进程的下一个进程,所以通过当前进程的next域找到。
情况一:next进程从来没运行过
假设当前进程是系统运行时启动的0号进程,next的1号进程从么运行过。这次调度时第一次调度。
0号进程的next是1号进程,1号进程从来没有被执行过,他的state被初始化为1,所以if-else循环走的是else分支。
else首先是将next进程也就是1号进程的state设置为0,使得下次调度1号进程的时候能正确处理。
asm volatile(
"movl %%esp,%0\n\t"//保存prev的栈顶
"movl %2,%%esp\n\t" //将esp设置为1号进程的栈顶
"movl %2,%%ebp\n\t" //因为1号进程第一次执行,所以它的ebp和esp相同
"movl $1f,%1\n\t" //1f是标号,指向if语句块中的 "1:\t", 具体原因在后面解释
"pushl %3\n\t"//将next的ip,压栈
"ret\n\t" //ip出栈到eip
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
ret语句执行完后,eip的值等于的1号进程的初始ip,也就是my_process。在ret执行完的时候,ebp,esp,eip都是1号进程的,而之前0号进程的ebp在0号进程my_schedule调用时被压栈保存,esp在调度的时候被保存到0号进程的thread.sp域中,ip域也保存了一个玄乎的地址,这样我们就实现了保存0号进程和执行1号进程的进程调度过程。
从1号进程调度到2号,2号调度到3号过程都是一样的。第一次被调度的进程会从my_process开始执行,然后不断检查自己是否需要调度,如果需要调度,就调度到下一个进程。
情况二:next进程被调度过
假设当前进程是3号进程,next进程是0号进程,0号进程的state是0,所以做if分支
asm volatile(
"movl %%esp,%0\n\t"//将当前esp保存到3号进程的sp中
"movl %2,%%esp\n\t" //将0号进程的sp恢复到esp
"movl $1f,%1\n\t" //将1标号的位置保存到3号进程的ip中
"pushl %3\n\t" //将0号进程的ip压栈,
"ret\n\t" //被压栈的0号进程的ip送到eip,继续执行0号进程
"1:\t" //1标号
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
怎么理解?
由于my_schedule这个函数是被某个特定的进程调用的,所以这个函数虽然只在文件中出现了一次,但是实际上由四个不同的进程所调用的这个函数是各自不同的,有四个。所以进程的执行示意图如下:
对于进程1 号,如果忽略my_schedule函数的调度,它感觉到的是这样的:
稍微需要注意的是内联汇编里面有三句被注释的。
linux实际的kernel源码里面是有这样对应的操作的,因为在实际的kernel中,进程调度的是实现是通过一段宏,而不像是mykernel中的通过my_schedule函数。通过宏,prev的ebp需要手动保存(需要保存?),而通过函数时,prev进程的ebp保存在调用my_schedule函数时就做好了,next的ebp恢复也在my_schedule的返回中完成,所以这两句代码和else中的push %ebp是可以删除。
关于my_timer_handler
void my_timer_handler(void)
{
#if 1
if(time_count%1000 == 0 && my_need_sched != 1)
{
printk(KERN_NOTICE ">>>my_timer_handler here<<<\n");
my_need_sched = 1;
}
time_count ++ ;
#endif
return;
}
这是对时钟中断的处理函数。每一千次时钟中断就将my_need_sched的值改成1,进程不断运行时检测到my_need_sched的值是1, 就将它改成0,并发生进程调度。
总结:
操作系统的调度程序对进程的现场保存与恢复实现进程之间的切换,调度对于进程而言是透明的,进程并不会感觉到自己被切换。现代操作系统良好的进程调度机制是多任务同时进行的基础。
邱聪
原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000

相关文章推荐
- 程序怎么跑?(1)--linux 课程学习笔记
- Linux学习笔记 - 程序的执行(完结)
- Linux学习笔记 - 程序的执行(一)
- linux学习笔记之--vim 程序编辑器
- linux 学习笔记 后台进程运行程序
- 学习笔记_linux——java程序部署
- [linux学习笔记]第3天:变量分类,重定向,管道命令,程序执行流,文本处理类命令, 正则表达式,短路操作符
- linux0.11学习笔记-技术铺垫-简单AB任务切换程序(3)-调试手段和方法
- linux学习笔记之--vim 程序编辑器
- linux0.11学习笔记-技术铺垫-简单AB任务切换程序(5)-实现三个任务切换
- Linux 程序设计学习笔记----进程管理与程序开发(下)
- Linux0.12引导启动程序学习笔记(i386)
- linux0.11学习笔记-技术铺垫-简单AB任务切换程序(2)-可加载执行其他程序的bootloader
- linux_C一站学习--学习笔记(一)程序的基本概念;常量、变量和表达式;简单函数
- Linux程序设计-学习笔记-第二章shell程序设计
- linux环境arm裸机程序学习笔记1----makefile,中断,下载程序方法
- linux0.11学习笔记-技术铺垫-简单AB任务切换程序(4)-向现存写数据并响应时钟中断
- linux0.11学习笔记-技术铺垫-简单AB任务切换程序(5)-实现三个任务切换
- Linux 学习笔记 -- 第三部分 学习 shell 与 shell script -- 第10章 vim 程序编辑器
- Linux学习笔记20——第一个多线程程序