多线程(一):多线程问题产生原因
2015-03-10 21:25
239 查看
包括:
一. Java 内存模型
二. i++ 操作 细节
三. 内存之间的指令操作
[b]一. Java 内存模型[/b]
线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM(Java内存模型)的一个抽象概念,并不真实存在。它涵盖了缓存,写 缓冲区,寄存器以及其 他的硬件和编译器优化。Java内存模型的抽象示意图如下:
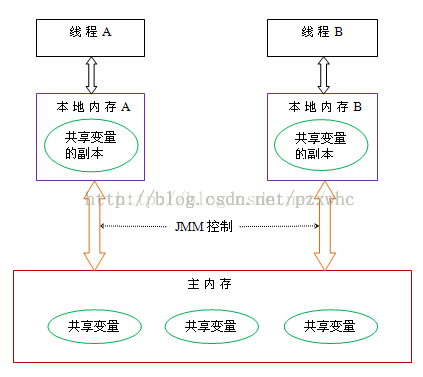
二. i++ 操作 细节
以上代码在JVM中的执行过程:
JVM首先在JVM堆给 i 分配一个内存存储场所,并存储其值为0。线程启动后,会自动分配一个操作数栈。当程序执行到 return i++,JVM并不是简单的一个步骤就可以完成。i++动作在jvm中分为装载i,读取i,进行i+1操作,存储i及写入i等5个步骤。
装载 i:线程将 i 值从JVM堆复制到本地内存。
读取 i:从本地内存中读取i到操作数栈。
进行 i+1 操作:由线程来操作,在方法栈中执行。
存储 i:将 i+1 的值赋值给 i,然后存储到本地内存。
写入 i:将本地内存中i的值写入到java堆内存。
因为main memory中的 i 和 working memory 中的 i 同步是需要时间的,如果在多线程环境下,假设线程A已经执行了 i+1 操作,当尚未完成写入 i 操作,线程b就完成了装载 i 的过程,那么当线程b执行完成,得到的值和a就是一样的。
当多线程执行此段代码的时候,线程a执行到getNextId()方法,JVM知道该方法有关键字,于是在执行其他动作前,首先在对象的实例前面加上一个 lock,然后再继续执行return i++,而此时如果线程b并发访问getNextId()方法,JVM观察这个对象的实例上面有lock,于是将
线程b放入等待执行的队列,只有等线程a的return i++执行完毕,jvm才会释放对象实例上面的锁,重新标记为unlock,这时当线程调度到线 程b,线程b才得以执行getNextId()方法。
在装载i,读取i的过程中,因为涉及到与内存打交道,CPU就处于空闲状态,为了更有效的利用CPU,JAVA就使用多线程的方式执行程序。由此可以看出:Java内存模型决定了使用多线程,则会极大提高程序的运行效率,所以线程无处不在!
三. 内存之间的指令操作
主内存和工作内存之间的同步,通过以下的8种指令:
lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load指定使用。
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入到工作内存的变量副本中。
use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令的时候将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
store(存储):作用于工作内存变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
write(写入):作用于主内存变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
总结:
Java 内存模型:有主内存和工作内存的概念。
i ++ 操作:分为 装载,读取,进行 i + 1 操作, 存储i,写入i 等几步。
多线程产生:当进行变量的读写操作的时候,希望能充分利用CPU。
一. Java 内存模型
二. i++ 操作 细节
三. 内存之间的指令操作
[b]一. Java 内存模型[/b]
线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM(Java内存模型)的一个抽象概念,并不真实存在。它涵盖了缓存,写 缓冲区,寄存器以及其 他的硬件和编译器优化。Java内存模型的抽象示意图如下:
二. i++ 操作 细节
int i = 0; //实例变量,保存在堆内存里面
getNextId(){
return i++;
}以上代码在JVM中的执行过程:
JVM首先在JVM堆给 i 分配一个内存存储场所,并存储其值为0。线程启动后,会自动分配一个操作数栈。当程序执行到 return i++,JVM并不是简单的一个步骤就可以完成。i++动作在jvm中分为装载i,读取i,进行i+1操作,存储i及写入i等5个步骤。
装载 i:线程将 i 值从JVM堆复制到本地内存。
读取 i:从本地内存中读取i到操作数栈。
进行 i+1 操作:由线程来操作,在方法栈中执行。
存储 i:将 i+1 的值赋值给 i,然后存储到本地内存。
写入 i:将本地内存中i的值写入到java堆内存。
因为main memory中的 i 和 working memory 中的 i 同步是需要时间的,如果在多线程环境下,假设线程A已经执行了 i+1 操作,当尚未完成写入 i 操作,线程b就完成了装载 i 的过程,那么当线程b执行完成,得到的值和a就是一样的。
当多线程执行此段代码的时候,线程a执行到getNextId()方法,JVM知道该方法有关键字,于是在执行其他动作前,首先在对象的实例前面加上一个 lock,然后再继续执行return i++,而此时如果线程b并发访问getNextId()方法,JVM观察这个对象的实例上面有lock,于是将
线程b放入等待执行的队列,只有等线程a的return i++执行完毕,jvm才会释放对象实例上面的锁,重新标记为unlock,这时当线程调度到线 程b,线程b才得以执行getNextId()方法。
在装载i,读取i的过程中,因为涉及到与内存打交道,CPU就处于空闲状态,为了更有效的利用CPU,JAVA就使用多线程的方式执行程序。由此可以看出:Java内存模型决定了使用多线程,则会极大提高程序的运行效率,所以线程无处不在!
三. 内存之间的指令操作
主内存和工作内存之间的同步,通过以下的8种指令:
lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态。
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load指定使用。
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入到工作内存的变量副本中。
use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令的时候将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
store(存储):作用于工作内存变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
write(写入):作用于主内存变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
总结:
Java 内存模型:有主内存和工作内存的概念。
i ++ 操作:分为 装载,读取,进行 i + 1 操作, 存储i,写入i 等几步。
多线程产生:当进行变量的读写操作的时候,希望能充分利用CPU。

相关文章推荐
- JAVA多线程(一)线程安全问题产生的原因
- 多线程-线程安全问题的产生原因分析以及同步代码块的方式解决线程安全问题
- 多线程安全问题产生的原因
- 多线程_线程安全问题的产生原因分析
- 多线程问题产生原因
- 12-多线程(卖票示例)1 2 14-多线程(线程安全问题产生的原因)
- Windows2008上运行java产生8小时时差问题原因
- 解决Oracle死锁问题,及产生的原因
- CRM的现状、存在的问题、误区以及这些问题产生的原因
- Java多线程产生死锁的原因和解决方法
- 多线程四,死锁产生的原因和死锁的例子(毕向东老师)
- 关于too many connections问题产生原因的理解
- 孙鑫谈Java中文乱码问题产生原因分析
- 关于std::string的引用计数在多线程中产生的问题
- Random产生重复伪随机数的真正原因 并非时间问题
- "Unable to get image data from canvas because the canvas has been tainted by cross-origin data"问题产生原因及解决办法
- 关于too many connections问题产生原因的理解
- C#Random在多线程情况下产生的随机数总是0的问题
- 网站不播放FLV问题 可能产生的原因
- 回顾生产者/消费者问题下产生的java多线程(二)