Hadoop RPC源码解析——Server类(二)
2015-02-15 21:50
211 查看
Hadoop RPC主要由三大部分组成:Client、Server和RPC,如下表所示。
本文紧接Hadoop RPC源码解析——Server类(一)
当reader线程被唤醒后,就会继续执行run()方法,直到执行到doRead()方法。查看该方法的代码。
从以上代码中我们发现真正处理读事件的是内部类Connection的readAndProces()方法。下面查看该方法的代码。
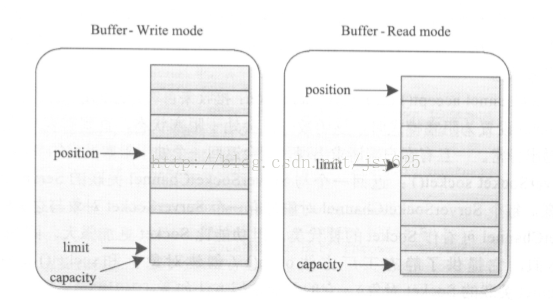
这里涉及到了Java NIO的一些知识。在Java NIO中channel只能和buffer相连,也就是说我们只能通过buffer往channel里写数据,也只能通过读出channel中的数据。且读模式和写模式下的buffer中的结构如下图所示。
因此当上面调用channel的read时会将channel中的数据读入到heap buffer中(或调用write方法将heap buffer中数据写入到某个channel中),Java 底层实现中使用了Direct Buffer暂时对数据进行缓存。首先JVM初始创建一个固定大小的Direct Buffer,并将channel中的数据写入buffer,如果buffer大小不够则再创建一个更大的Direct Buffer并将之前的Direct Buffer中的内容复制到新的Direct Buffer中,直到将channel中的数据全部读入。很明显,该过程涉及了大量内存复制操作,会明显降低性能。才外Direct
Buffer占领的内存不会马上被释放,因此会造成内存使用骤升,为了解决这个问题,可将读入的数据分成固定大小(这里为8K,也就是“NIO_BUFFER_LIMIT”)的chunk,并以chunk为单位写入DirectBuffer。查看channelIO()方法就能看到具体的实现过程。
回到代码二十八,该代码段只是读取了请求,而真正的处理是在Connection类的processOneRPC()方法中,因此来具体查看这个方法。
在上面的代码中我们终于看到了客户端想要调用的方法在服务器端通过java反射机制被调用了,接下来就是将方法的调用结果返回给客户端的问题了。我们返回代码三十三来查看doRespond()方法。
继续来查看其中的processResponse()方法。
该段代码中的channelWrite()方法与ChannelRead方法十分相似:如果数据小于NIO_BUFFER_LIMIT,则直接写到channel中,否则以chunk为单位写入,代码如下所示。
回到代码三十六,如果没有这里没能将数据一次返回给客户端,那么就会把该call加入到responseQueue中并唤醒writeSelector,将该channel注册到writeSelector中,并注册写事件。查看Responder类的run()方法,代码如下。
我们看到刚开始时由于pending为0所以该线程会在run中一直循环。当有请求被加入时该线程会进入waitPending()中等待被唤醒。在代码三十八的processRespond()中唤醒了该线程。当有可写事件时我们会执行doAsyncWrite()方法。而对于在一定时间内都没有被发送出去的call,我们会选择丢弃。查看doAsyncWrite()方法代码如下。
我们发现该方法最后又调用了processResponse方法来发送数据。依次循环,直到将call的数据全部发送出去。
至此,RPC的Server端的代码也分析完毕。
Server类的函数调用情况图下图所示
| 内部类 | 功能 |
| Client | 连接服务器、传递函数名和相应的参数、等待结果 |
| Server | 主要接受Client的请求、执行相应的函数、返回结果 |
| RPC | 外部编程接口,主要是为通信的服务方提供代理 |
当reader线程被唤醒后,就会继续执行run()方法,直到执行到doRead()方法。查看该方法的代码。
//代码二十七
// Server.Listener#doRead
void doRead(SelectionKey key) throws InterruptedException {
int count = 0;
//获得该key上附加的Connection
Connection c = (Connection)key.attachment();
if (c == null) {
return;
}
c.setLastContact(System.currentTimeMillis());
try {
//接受并处理请求
count = c.readAndProcess();
} catch (InterruptedException ieo) {
LOG.info(getName() + ": readAndProcess caught InterruptedException", ieo);
throw ieo;
} catch (Exception e) {
LOG.info(getName() + ": readAndProcess threw exception " + e + ". Count of bytes read: " + count, e);
count = -1; //so that the (count < 0) block is executed
}
if (count < 0) {
if (LOG.isDebugEnabled())
LOG.debug(getName() + ": disconnecting client " +
c + ". Number of active connections: "+
numConnections);
closeConnection(c);
c = null;
}
else {
c.setLastContact(System.currentTimeMillis());
}
}从以上代码中我们发现真正处理读事件的是内部类Connection的readAndProces()方法。下面查看该方法的代码。
//代码二十八
// Server.Connection#readAndProcess
public int readAndProcess() throws IOException, InterruptedException {
while (true) {
// 一次只处理一个RPC
int count = -1;
……
//读取请求头
count = channelRead(channel, rpcHeaderBuffer);
if (count < 0 || rpcHeaderBuffer.remaining() > 0) {
return count;
}
//读取请求版本号
int version = rpcHeaderBuffer.get(0);
byte[] method = new byte[] {rpcHeaderBuffer.get(1)};
authMethod = AuthMethod.read(new DataInputStream(
new ByteArrayInputStream(method)));
dataLengthBuffer.flip();
……
//读取请求
count = channelRead(channel, data);
if (data.remaining() == 0) {
dataLengthBuffer.clear();
data.flip();
if (skipInitialSaslHandshake) {
data = null;
skipInitialSaslHandshake = false;
continue;
}
boolean isHeaderRead = headerRead;
if (useSasl) {
saslReadAndProcess(data.array());
} else {
//处理请求
processOneRpc(data.array());
}
data = null;
if (!isHeaderRead) {
continue;
}
}
return count;
}
}从以上代码中,我们看到读取的时候都是调用了channelRead()方法。我们来具体查看该方法。//代码二十九
// Server#channleRead
/**
* 这是对read(ByteBuffer)的封装。当buffer中的数据量超过NIO_BUFFER)LIMIT的限制时,buffer中的数据将被分成多个chunk读入。这为了避免direct buffer的size无限增加。
*/
private int channelRead(ReadableByteChannel channel,
ByteBuffer buffer) throws IOException {
//如果buffer中剩余可写的部分小于NIO_BUFFER_LIMIT,那么直接将channel中的数据写入到buffer中,
//否则执行channelIO方法。两者都返回的count是写入的字节数
int count = (buffer.remaining() <= NIO_BUFFER_LIMIT) ?
channel.read(buffer) : channelIO(channel, null, buffer);
if (count > 0) {
rpcMetrics.incrReceivedBytes(count);
}
return count;
}这里涉及到了Java NIO的一些知识。在Java NIO中channel只能和buffer相连,也就是说我们只能通过buffer往channel里写数据,也只能通过读出channel中的数据。且读模式和写模式下的buffer中的结构如下图所示。
因此当上面调用channel的read时会将channel中的数据读入到heap buffer中(或调用write方法将heap buffer中数据写入到某个channel中),Java 底层实现中使用了Direct Buffer暂时对数据进行缓存。首先JVM初始创建一个固定大小的Direct Buffer,并将channel中的数据写入buffer,如果buffer大小不够则再创建一个更大的Direct Buffer并将之前的Direct Buffer中的内容复制到新的Direct Buffer中,直到将channel中的数据全部读入。很明显,该过程涉及了大量内存复制操作,会明显降低性能。才外Direct
Buffer占领的内存不会马上被释放,因此会造成内存使用骤升,为了解决这个问题,可将读入的数据分成固定大小(这里为8K,也就是“NIO_BUFFER_LIMIT”)的chunk,并以chunk为单位写入DirectBuffer。查看channelIO()方法就能看到具体的实现过程。
//代码三十
// Server#channleIO
private static int channelIO(ReadableByteChannel readCh,
WritableByteChannel writeCh,
ByteBuffer buf) throws IOException {
int originalLimit = buf.limit();
int initialRemaining = buf.remaining();
int ret = 0;
//remaining函数算的是limit与position之间的值,所以在写模式下代表剩余的容量
//读模式下代表buffer中的数据量
while (buf.remaining() > 0) {
try {
//取两者中的较小值
int ioSize = Math.min(buf.remaining(), NIO_BUFFER_LIMIT);
//修改limit的位置
buf.limit(buf.position() + ioSize);
ret = (readCh == null) ? writeCh.write(buf) : readCh.read(buf);
//非阻塞模式下,write或者read函数对应的网络缓冲区满后,会直接返回
//返回的值为实际写入或者读取的数据
if (ret < ioSize) {
break;
}
} finally {
buf.limit(originalLimit);
}
}
int nBytes = initialRemaining - buf.remaining();
return (nBytes > 0) ? nBytes : ret;
}
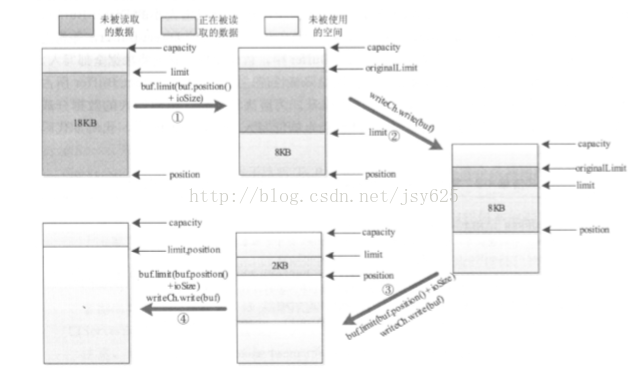
}上面代码的逻辑可以通过下图来解释。上面的代码是读写模式通用的,下面的图展示的是读模式下的情况,也就是说要将buffer中的内容读出到channel中。回到代码二十八,该代码段只是读取了请求,而真正的处理是在Connection类的processOneRPC()方法中,因此来具体查看这个方法。
//代码三十一
// Server.Connection#processOneRPC
private void processOneRpc(byte[] buf) throws IOException,
InterruptedException {
if (headerRead) {//若请求头部已经读取
processData(buf);//数据处理
} else {
processHeader(buf);
headerRead = true;
if (!authorizeConnection()) {
throw new AccessControlException("Connection from " + this
+ " for protocol " + header.getProtocol()
+ " is unauthorized for user " + user);
}
}
}接着查看其中的processData()方法//代码三十二
// Server.Connection#processData
privat
4000
e void processData(byte[] buf) throws IOException, InterruptedException {
DataInputStream dis =
new DataInputStream(new ByteArrayInputStream(buf));
int id = dis.readInt(); // 尝试读取call的id
Writable param = ReflectionUtils.newInstance(paramClass, conf);//read param读取参数
param.readFields(dis);
//将连接封装成call
Call call = new Call(id, param, this);
//将call加入到call队列中,若此刻队列这种没有空余位置,则阻塞
callQueue.put(call);
incRpcCount(); //增加未完成的RPC请求数
}代码十九中我们看到,在Server类的start()方法中,我们创建了一个handler池并启动了其中的每个线程。接下来我们就来看handler是怎样处理callQueue中的call的吧。查看Handler类的run()方法。//代码三十三
// Server.Handler#run
public void run() {
……
while (running) {
try {
//从callQueu中取出一个call来处理,如果此时队列中没有call,那么就阻塞
final Call call = callQueue.take();
……
Writable value = null;
CurCall.set(call);
try {
//这里调用Server类的call()方法,但是该call()方法是个虚方法,具体实现在RPC.Server类中
if (call.connection.user == null) {
value = call(call.connection.protocol, call.param,
call.timestamp);
} else {
value =
call.connection.user.doAs
(new PrivilegedExceptionAction<Writable>() {
@Override
public Writable run() throws Exception {
// make the call
return call(call.connection.protocol,
call.param, call.timestamp);
}})}}
……
//给客户端响应请求
responder.doRespond(call);
}
}……
}上面的注释已说明call()方法实际调用的是RPC类中的内部类Server类的call()方法。查看具体代码。//代码三十四
// RPC.Server#call
public Writable call(Class<?> protocol, Writable param, long receivedTime) throws IOException {
try {
//将传入的参数转换成Invocation类型,该类是对方法和参数的封装
Invocation call = (Invocation)param;
if (verbose) log("Call: " + call);
//根据传入的方法名和参数,运用java的反射机制
//获得服务器端要被调用的方法
Method method =
protocol.getMethod(call.getMethodName(),
call.getParameterClasses());
method.setAccessible(true);
long startTime = System.currentTimeMillis();
//这里真正调用了客户端想要调用的服务器端的方法
Object value = method.invoke(instance, call.getParameters());
……
return new ObjectWritable(method.getReturnType(), value);
……
} }在上面的代码中我们终于看到了客户端想要调用的方法在服务器端通过java反射机制被调用了,接下来就是将方法的调用结果返回给客户端的问题了。我们返回代码三十三来查看doRespond()方法。
//代码三十五
//Server.Responder#doRespond
//将一个Response加入到队列responseQueue中
void doRespond(Call call) throws IOException {
synchronized (call.connection.responseQueue) {
//将一个Response加入到队列responseQueue中
call.connection.responseQueue.addLast(call);
if (call.connection.responseQueue.size() == 1) {
//若该connection对应的队列responseQueue中只有一个Response,
//就立即调用processResponse()来处理该Response
processResponse(call.connection.responseQueue, true);
}
}
}继续来查看其中的processResponse()方法。
//代码三十六
//Server.Responder#processRespond
//处理响应。当队列中没有要处理的数据时返回true
private boolean processResponse(LinkedList<Call> responseQueue,
boolean inHandler) throws IOException {
boolean error = true;
boolean done = false; // there is more data for this channel.
int numElements = 0;
Call call = null;
try {
synchronized (responseQueue) {
//若队列中没有东西则表示我们已经完成
numElements = responseQueue.size();
if (numElements == 0) {
error = false;
return true; // no more data for this channel.
}
//获得第一个call
call = responseQueue.removeFirst();
SocketChannel channel = call.connection.channel;
if (LOG.isDebugEnabled()) {
LOG.debug(getName() + ": responding to #" + call.id + " from " +
call.connection);
}
//在非阻塞模式下尽量多发数据
int numBytes = channelWrite(channel, call.response);
//表明已经处理完成了
if (numBytes < 0) {
return true;
}
//说明buffer中数据已经一次全部发送完毕
if (!call.response.hasRemaining()) {
//减少一个未处理的RPC请求数
call.connection.decRpcCount();
if (numElements == 1) { //最后一个请求被处理完成
done = true; // 用done变量来标志没有数据需要写入管道了
} else {
done = false; //表明还有需要写入到管道中的数据
}
if (LOG.isDebugEnabled()) {
LOG.debug(getName() + ": responding to #" + call.id + " from " +
call.connection + " Wrote " + numBytes + " bytes.");
}
} else {
//如果我们没能直接将结果一次发送给客户,那么就该call交给Responder线程发送剩下的数据
call.connection.responseQueue.addFirst(call);
if (inHandler) {
// set the serve time when the response has to be sent later
call.timestamp = System.currentTimeMillis();
//增加未处理的RPC请求数
incPending();
try {
//将写线程唤醒
writeSelector.wakeup();
//将该channel注册到writeRegister上,注册写事件
channel.register(writeSelector, SelectionKey.OP_WRITE, call);
} ……
return done;
}该段代码中的channelWrite()方法与ChannelRead方法十分相似:如果数据小于NIO_BUFFER_LIMIT,则直接写到channel中,否则以chunk为单位写入,代码如下所示。
//代码三十七
//Server#channelWrite
private int channelWrite(WritableByteChannel channel,
ByteBuffer buffer) throws IOException {
//此时buffer处于读状态,所以remaining()返回的是buffer中的数据大小
//如果数据小于NIO_BUFFER_LIMIT,则直接写到channel中,否则以chunk为单位写入
int count = (buffer.remaining() <= NIO_BUFFER_LIMIT) ?
channel.write(buffer) : channelIO(null, channel, buffer);
if (count > 0) {
rpcMetrics.incrSentBytes(count);
}
return count;
}回到代码三十六,如果没有这里没能将数据一次返回给客户端,那么就会把该call加入到responseQueue中并唤醒writeSelector,将该channel注册到writeSelector中,并注册写事件。查看Responder类的run()方法,代码如下。
//代码三十八
//Server.Responder#run
public void run() {
LOG.info(getName() + ": starting");
SERVER.set(Server.this);
long lastPurgeTime = 0; // last check for old calls.
/**刚开始由于pending为0,所以在waitPending()中不会进行等待。
* 当有call加入后就会是pending值增加,并唤醒writeSelector线程。
*/
while (running) {
try {
//如果一个channel正在被注册,则wait
waitPending(); // If a channel is being registered, wait.
//每隔15min返回一次结果,如果没有则跳过下面的while继续
writeSelector.select(PURGE_INTERVAL);
Iterator<SelectionKey> iter = writeSelector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
try {
if (key.isValid() && key.isWritable()) {
doAsyncWrite(key);
}
} catch (IOException e) {
LOG.info(getName() + ": doAsyncWrite threw exception " + e);
}
}
long now = System.currentTimeMillis();
if (now < lastPurgeTime + PURGE_INTERVAL) {
continue;
}
lastPurgeTime = now;
//如果有些call很长时间都没有被发送出去则丢弃它
LOG.debug("Checking for old call responses.");
ArrayList<Call> calls;
synchronized (writeSelector.keys()) {
calls = new ArrayList<Call>(writeSelector.keys().size());
iter = writeSelector.keys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
Call call = (Call)key.attachment();
if (call != null && key.channel() == call.connection.channel) {
calls.add(call);
}
}
}
for(Call call : calls) {
try {
doPurge(call, now);
} catch (IOException e) {
LOG.warn("Error in purging old calls " + e);
}
}
} catch (OutOfMemoryError e) {
……
}我们看到刚开始时由于pending为0所以该线程会在run中一直循环。当有请求被加入时该线程会进入waitPending()中等待被唤醒。在代码三十八的processRespond()中唤醒了该线程。当有可写事件时我们会执行doAsyncWrite()方法。而对于在一定时间内都没有被发送出去的call,我们会选择丢弃。查看doAsyncWrite()方法代码如下。
//代码三十九
//Server.Responder#doAsyncWrite
private void doAsyncWrite(SelectionKey key) throws IOException {
Call call = (Call)key.attachment();
if (call == null) {
return;
}
if (key.channel() != call.connection.channel) {
throw new IOException("doAsyncWrite: bad channel");
}
synchronized(call.connection.responseQueue) {
if (processResponse(call.connection.responseQueue, false)) {
try {
key.interestOps(0);
} catch (CancelledKeyException e) {
LOG.warn("Exception while changing ops : " + e);
}
}
}
}我们发现该方法最后又调用了processResponse方法来发送数据。依次循环,直到将call的数据全部发送出去。
至此,RPC的Server端的代码也分析完毕。
Server类的函数调用情况图下图所示

相关文章推荐
- Hadoop RPC源码解析——Server类(一)
- Hadoop RPC远程过程调用源码解析及实例
- Hadoop源码解析之 rpc通信 client到server通信
- Hadoop源码分析之一(RPC机制之Server)
- Hadoop RPC源码解析——Client类
- Hadoop RPC源码分析之Server
- hadoop 2.6 源码解读之RPC Server 类高性能设计
- Hadoop最新版 RPC远程过程调用源码解析及实例
- Hadoop源码解析之 rpc通信 client到server通信
- HadoopRPC源码解析
- hadoop源码研读之路(六)----RPC的Client端和Server端
- Hadoop RPC 源码解析
- Hadoop RPC远程过程调用源码解析及实例
- 细水长流Hadoop源码分析(3)RPC Server初始化启动过程
- hadoop源码研读之路(六)----RPC的Client端和Server端
- Hadoop 源码解析-rpc扩展
- Hadoop RPC源码阅读-服务端Server
- Hadoop之RPC Server源码分析
- Hadoop源码分析之一(RPC机制之Server)
- Hadoop RPC源码解析——RPC框架详解