spark学习笔记三:spark原理介绍
2015-02-06 15:46
459 查看
基本介绍
Spark是UC Berkeley AMPlab推出的分布式计算框架,目前有替代mapreduce的趋势。Spark使用scala语言开发,支持的策略开发语言有:scala、python、java。
Spark的整个生态系统称为伯克利数据分析栈(BDAS)。Spark是伯克利数据分析栈(BDAS)的计算核心,相当于电脑中的CPU。
Spark可以完全融入hadoop生态系统(比如支持Hive、HDFS、HBase数据源),它只是替代了其中的mapreduce的计算模式。
基于MapReduce情况下,一人计算作业会被切分成多个MapReduce任务,每个MapReduce使用HDFS作为中间结果的存储介质。而Spark可以支持除map和reduce以外的更多操作,这些操作间形成一个无环图,各个操作之间的数据都在内存中。
计算模型
基本概念
l Application:应用。可以认为是多次批量计算组合起来的过程,在物理上可以表现为你写的程序包+部署配置。应用的概念类似于计算机中的程序,它只是一个蓝本,尚没有运行起来。l RDD:Resilient Distributed Datasets,弹性分布式数据集。RDD即是计算模型里的一个概念,也是你编程时用到的一种类。一个RDD可以认为是spark在执行分布式计算时的一批相同来源、相同结构、相同用途的数据集,这个数据集可能被切割成多个分区,分布在不同的机器上,无论如何,这个数据集被称为一个RDD。在编程时,RDD对象就对应了这个数据集,并且RDD对象被当作一个数据操作的基本单位。比如,对某个RDD对象进行map操作,其实就相当于将数据集中的每个分区的每一条数据进行了map映射。
l Partition:分区。一个RDD在物理上被切割成多个数据子集,分布在不同的机器上。每个数据子集叫一个分区。
l RDD Graph:RDD组成的DAG(有向无环图)。RDD是不可变的,一个RDD经过某种操作后,会生成一个新的RDD。这样说来,一个Application中的程序,其内容基本上都是对各种RDD的操作,从源RDD,经过各种计算,产生中间RDD,最后生成你想要的RDD并输出。这个过程中的各个RDD,会构成一个有向无环图。
l Lineage:血统。RDD这个概念本身包含了这种信息“由哪个父类RDD经过哪种操作得到”。所以某个RDD可以通过不断寻找父类,找到最原始的那个RDD。这条继承路径就认为是RDD的血统。
l Job:从Application和RDD Graph的概念可以知道,一个应用往往对应了一个RDD Graph。这个应用在准备被spark集群运行前,实际上就是会生成一个或多个RDD Graph结构,而一个RDD Graph,又可以生成一个或多个Job。一个Job可以认为就是会最终输出一个结果RDD(后面会介绍,实际上这是action操作)的一条由RDD组织而成的计算,在Application生成的RDD Graph上表现为一个子图。Job在spark里应用里也是一个被调度的单位。
l 宽依赖:RDD生成另一个RDD时,各个两个父子RDD间分区的对应关系,被叫做RDD间依赖。宽依赖就是子RDD的某个分区,依赖父RDD的全部分区。
l 窄依赖:窄依赖就是子RDD的某个分区,只依赖常数个父RDD的分区。宽窄依赖的区别如下图所示。
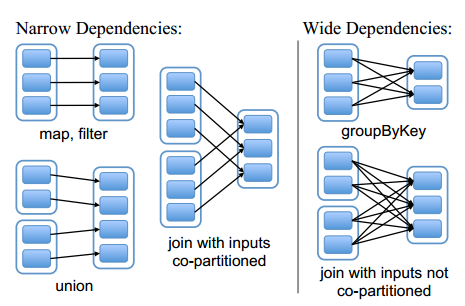
l Stage:Stage可以理解为完成一个Job的不同阶段。一个Job被划分为多个Stage,每个Stage又包含了对多个RDD的多个操作。一个Stage里,一般包含了一个宽依赖操作,或者多个窄依赖操作。
l 算子:父子RDD间的某种操作,被叫某种算子。比如下面会介绍的map,filter,groupByKey等。算子可从多个维度分类,之后再介绍。
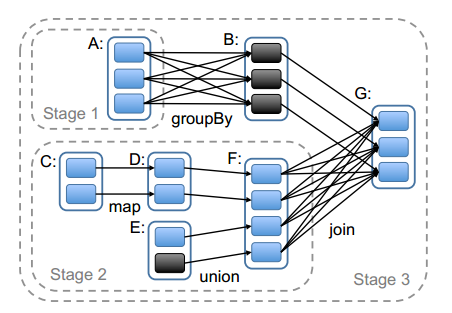
一个典型的RDD Graph如上图所示。其中实线框是RDD,RDD内的实心矩形是各个分区,实线箭头表示父子分区间依赖关系,虚线框表示stage。
RDD
RDD的来源有两种:1. 从外部系统输入,如Hive、Cassandra、HBase、HDFS等;2. 从父RDD转换得到。RDD内部包含的东西:
分区列表
计算每个分区的函数
依赖的父RDD列表
对Key-Value对数据类型RDD的分区器,控制分区策略和分区数
每个数据分区的地址列表
如果从HDFS上读数据而产生RDD,那么一个Block对应一个分区。
算子
从是否产生实际的计算来看,算子分两种:l Transformation:变换。变换往往从一个RDD到另一个RDD的计算。在执行应用的程序时,遇到变换算子,并不会立即触发spark集群的操作,而是延时到遇到Action时再操作。
l Action:动作。一个动作往往代表一种输出到外部系统的操作。在执行应用的程序时,遇到动作算子,立即产生一个Job,并调度,进而触发spark集群的计算操作。
从针对的数据类型来看,Transformation也分为两种:
l 对value数据类型的变换
l 对Key-Value数据类型的变换
从依赖关系来看,Transformation还可分为以下两种:
l 窄依赖变换
l 宽依赖变换
文本只介绍概念,具体的算子及其功能,见API文档。
系统架构
Spark的系统架构是是典型的Master-slave结构,其层次如下表所示| MS模型 | Client | Master | Slave | |
| 网络中的物理节点 | | ClusterManager | Worker | |
| 节点上的服务 | Client | Standalone模式 | Master | Worker |
| YARN模式 | ResourceManger | NodeManger | ||
| Mesos模式 | | | ||
| 服务中对应的应用级别的任务 | Driver | | Driver | Executor |
l Worker:Master-Slave模型中的Slave。运行具体的任务。任务又包括Driver和Executor两类。
l Driver:运行应用的main()函数,维护SparkContext,负责作业的调度。
l Executer:不是常驻服务,每个应用拥有一组独立的Executer。每个应用在每个Worker上只有一个Executer。
需要说明的是,Client服务进程可以运行在任意物理节点上,只要有spark工具即可。Driver任务可以由Client来运行,也可以分配到Worker上来运行,具体的运行方式在应用提交时决定。
代码结构和工作流程
基本结构和概念
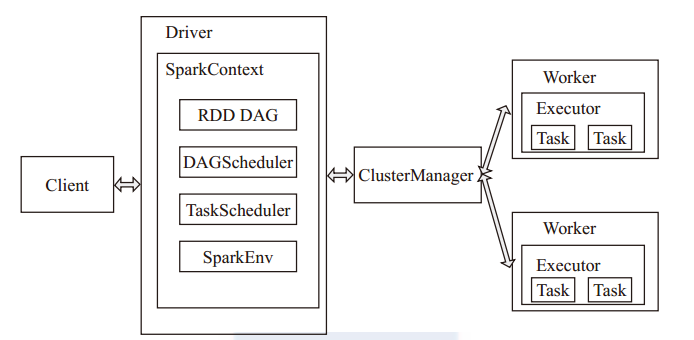
Task:一个分区对应一个Task。实际上一个Task就是在一个Stage范围内,某个Executor所要执行的算子。
TaskSet:一个Stage范围内,所有相同的Task被称为一个TaskSet。
DAGScheduler:DAGScheduler用于根据RDD DAG切分Stage,并维护各个Stage的先后依赖关系,相当于完成了一个Job内的不同Stage间的调度策略。
TasksetManager:管理一个TaskSet,并决定了这个TaskSet中各个Task的分发策略。
TaskScheduler:执行实际的Task分发操作。
工作流程
1. 提交Application如果客户端选择由Worker运行Driver,则客户端首先会向Master提交Application。提交的过程是通过客户端调用org.apache.spark.deploy.Client类来完成的。
2. Master调度应用
成功提交后应用,Master调度应用,针对每个应用分发给指定的一个Worker来启动Driver,并且Master给Worker指令启动Executor,之后Executor向Driver内的SchedulerBackend注册。Master调度应用的方法是FIFO,从第一台worker开始,从等待被运行的Driver的FIFO队列里依次取出符合这个worker资源限制的Driver,分配给这个Worker。直到Driver被分配完或者worker被遍历完。如果Driver是在客户端,启动后,会向Master注册。
3. Driver启动过程
Driver端启动后(可能是client端自已启动,也可能是由Master分配到worker上启动),创建DriverRunner线程,在DriverRunner线程内创建SchedulerBackend进程。这个进程会等待分配了任务的属于该应用的Executor的注册。SchedulerBackend进程维护了DAGScheduler组件,DAGScheduler用于根据RDD的DAG切分Stage,生成TaskSet,TaskSet被存放到TaskScheduler中,并由它执行调度和分发Task到Executor的操作。
在运行用户程序的过程中,当遇到Action算子时,实际上是由spark库代码来调用SparkContext的runJob来提交一个Job。
4. Job的切分
Job的切分由DAGScheduler完成。DAGScheduler根据每个Job的对应RDD DAG切分出Stage DAG。在这个Stage DAG上通过广度优先遍历,找到最上游的Stage。DAGScheduler组件本身维护了三个Stage集合(等待执行的、正在执行的、执行失败的)来帮助决定Stage的被调度顺序。
5. Stage的调度
Stage也是以FIFO的方式调度的。实际在代码中,每个Job会先被DAGScheduler切分成多个Stage,并根据Stage的依赖顺序,将依赖上游的Stage放到调度池中。每个Stage对象中包含两个关于优先级的信息:1.Job Id(先比较这个,越小优先级越高);2.Stage Id(再比较这个,也是越小越高)。越先提交的Job,其Stage中的Job Id越小,所以先提交的Job会先被调度;同一Job中越靠上游的Stage Id越大,但DAGScheduler能保证把上游的Stage先放入调度池中的。所以TaskSetManager只要取出调度池中优先级高的Stage(优先级的是通过以上所说的两两比较Job
Id和Stage Id而得出的)并满足资源限制的Stage进行调度即可。
另外,Job的调度策略和调度细节,也可以配置,这里不作说明,见相关文档。这里说的是Stage的调度,而实际上代码中被调度的应该是Stage中的TaskSetManager对象。Stage、TaskSetManager、TaskSet在代码层面是三个东西,而从概念上理解可以认为是一个东西。
6. Task的调度
Task调度的策略由TaskSetManager决定,而实际的分发操作由TaskScheduler完成。Task被调度的基本策略就是:如果RDD调用过cache,则这个Task被分发到分区缓存所在机器的Executor上执行;直接获取RDD中的执行点,所谓执行点,一个例子就是HDFS读出一个块数据所在的机器;如果Stage是窄依赖,则直接把Task给Stage内最上游RDD的各个分区所在机器。
7. Executor的执行
Master给Worker指令启动Executor。Worker创建Executor的过程是:先创建Executor-Runner线程,这个线程又启动ExecutorBackend进程。Executor向Driver内的SchedulerBackend注册。并Executor之后等待Driver分配Task,获取Task后执行。

相关文章推荐
- 韩顺平_轻松搞定网页设计(html+css+javascript)_第19讲_js运行原理_js开发工具介绍_js程序(hello)_js基本语法_学习笔记_源代码图解_PPT文档整理
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- 云计算学习笔记003---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- Spark 学习: spark 原理简述与 shuffle 过程介绍
- storm学习笔记之一:storm 入门原理介绍
- 【spring学习笔记三】aop思想介绍及实现原理
- 服务、云计算-云计算学习笔记---云计算的理解及介绍,google云计算平台实现原理-by小雨
- LVS学习笔记之LVS简介以及DR原理介绍
- 数据、进程-云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战-by小雨
- Unix原理与应用学习笔记----第三章 通用命令介绍2
- 云计算学习笔记---Hadoop简介,hadoop实现原理,NoSQL介绍...与传统关系型数据库对应关系,云计算面临的挑战
- Linux学习笔记之 DNS原理介绍、DNS搭建、主从复制、子域授权和视图
- Spark学习笔记之<RDD原理>
- Django框架学习笔记(22.CSRF原理简单介绍)
- 大数据学习笔记之三十 Spark介绍之一
- 【OAuth2.0学习笔记一】原理介绍
- Git学习笔记1--Git原理简单介绍
- 韩顺平_php从入门到精通_视频教程_第1讲_html介绍_html运行原理①_学习笔记_源代码图解_PPT文档整理
- C语言学习笔记---001C语言的介绍,编译过程原理,工具等
- Unix原理与应用学习笔记----第三章 通用命令介绍1