机器学习,我们需要注意什么
2015-01-27 10:27
351 查看
以下是我对 A Few Useful Things to Knowabout Machine Learning这篇论文中涉及的几个topic的看法。
1. 我们会把数据随机分成两部分,一部分当训练集,训练处模型,一部分当测试集,评估它的泛化能力。
2. 损失函数一般并不是说就是最小化训练集中的误差函数(如0/1error,hingle error等),它还会衡量模型的复杂度。
但真的就只是这样吗?过拟合只是因为噪声的存在才存在吗?假设真实模型是一个50次的多项式,但是由于训练集太小(没有噪声),你用50次的多项式模型去拟合数据的时候,会发现数据量的不足以支持选择最佳模型(有很多个模型都最好),然后算法就会随机选一个,虽然它能完美的拟合训练集,但在测试集中就say goodbye啦。总结来说就是:具有强假设的简单算法(朴素贝叶斯)会比弱假设的复杂算法(决策树)表现的好(这里所说的简单复杂是指算法的假设的模型空间),因为后者需要更多的数据防止过拟合。
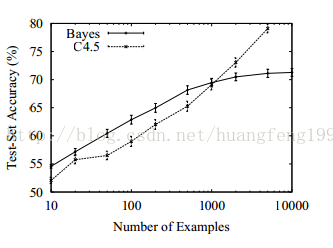
第一,数据本身它得有知识,就好比说拿我七大姑八大姨的数据预测什么时候地球末日,如果你这么干,只能怪你读书少。当然更为专业的说法是,几乎所有的非随机的数据中,都会包含这样或那样的模式,这些模式的存在使机器得以据此进行归纳。
第二,独立同分布,其实以上两点,都可以说你的数据要和你的任务相互匹配,但是这里的独立同分布更强调的是训练和泛化的上下文环境要一样,意思是比如说你去对美国进行名义调查,不能只调查有钱人支持谁谁谁,而应该同等比例的在各个阶级都抽样调查才行,这样你获取的结果才是相对可靠的。
第三,数据实例之间非常相似的话,那么它们很大可能是相同的类标签。就好比说我和你的身体各项指标都差不了多少,但是你能跑5km不喘气,而我最后4km是只能爬,这显然不科学,不带你这么吃药的是吧!
第四,我们要学的模型并不是想怎么样就怎么样,从数学的角度就是,如果我们要从数据集中得到特征到类标签的映射关系,那么这个映射函数不会想怎么复杂就这么复杂,一般而言线性啊,几项式啊也就搞定啦。
当然还有一些前提比如说数据的平滑性等等。以上我们提到的是机器学习对数据的共有的前提假设。但是针对不同的算法而言,它又会有不同的前提蕴含在里面,比如说朴素贝叶斯的条件独立的假设。最后提一下机器学习的一个很有名气的理论,即:Vc bound(有兴趣的同学可以看下cousera上的机器学习基石课程) ,我现在感觉vc它是脱离了具体的算法,从概率的角度,根据训练集的数据量和算法假设的模型空间的大小,给出训练的误差和测试误差(泛化误差)差值的一个上界。主要的意思就是,如果你的模型越复杂(拟合数据的能力),假设的模型空间很大,有很大可能包含着真实分类器,但你就面临着过拟合的危险。但是你的模型简单的话,假设空间包含真实模型的概率下降,但是你的训练误差和泛化误差可以保证不会差多少。虽然这是一个数学上的分析,但就好像我说的,它脱离了具体的算法,所以它所说的上界极其宽松,以至于我感觉在实际应用中,没有什么实际意思,更多是在告诉你要控制好模型的复杂度。在引用下论文中提到的一句话给这段结个高大上的尾巴,“learning
is a complexphenomenon ,and just because a learner has a theoretical justification andworks in practice doesn’t mean the former is the reason for the latter”。
第一, 输入空间大大小会随着维度的增加而指数及的增长,比如说64维的01向量,有多少个,2的64次方喂,简直不可理喻。
第二, 假设我用knn分析人们有钱没钱,然后我把身高体重什么什么的特征全部加进来分析,你认为得到的最邻近的数据点真的可信吗,应该会完全的淹没在噪声维里吧。
第三, 就算所有的数据维度都和任务相关,那可能更糟,想想在一个二维数据里和你距离为1的是个圈,三维是个球,4维不知道,反正空间一步一步增大,导致很多数据点都是临近的。但是这个解释,我不是很认同,毕竟整体空间也是啦啦的往上长。所以我认为,考虑一个现实生活的例子,提取每个人的所有特征,你认为人与人在每个维度是都不同,或者都差不多?我感觉更可能是在一部分维度上相同,一部分不同才更合理,所以这样就导致人与人之间的差距都不会太大。
1. Learning = representation +evaluation + optimization
如果说让我用一句话描述机器学习算法是怎样执行的,我会说: 机器学习算法是在它假设的模型空间(hypothesis space)中,根据损失函数,通过优化方法去寻找最佳模型。这里有三个关键词,就是假设的模型空间,损失函数,优化方法。比如说线性svm,就是在所有的线性分割超平面中,根据最大间隔化这一目标,通过诸如smo等一些优化方法去寻找那个超平面。当然这样把机器学习算法分割成几个部分,是为啦让我们从宏观上去把握算法,而不是说对每个算法都硬要这么肢解。2. It is Generalization That Counts
机器学习的目的是什么?并不是说在训练集中做的多好多好就很好很好,而是说要把我们从有限的数据中学到的知识应用到很有可能无限的数据中去。这才是机器学习的目标。正因为如此1. 我们会把数据随机分成两部分,一部分当训练集,训练处模型,一部分当测试集,评估它的泛化能力。
2. 损失函数一般并不是说就是最小化训练集中的误差函数(如0/1error,hingle error等),它还会衡量模型的复杂度。
3.overfitting has many faces
什么是过拟合,过拟合是由什么造成的?我感觉大部分人都会说过拟合是因为由于训练集中存在噪声,而我们的算法连噪声也拟合啦,导致对测试数据的预测准确性对比在训练集中会差很多。但真的就只是这样吗?过拟合只是因为噪声的存在才存在吗?假设真实模型是一个50次的多项式,但是由于训练集太小(没有噪声),你用50次的多项式模型去拟合数据的时候,会发现数据量的不足以支持选择最佳模型(有很多个模型都最好),然后算法就会随机选一个,虽然它能完美的拟合训练集,但在测试集中就say goodbye啦。总结来说就是:具有强假设的简单算法(朴素贝叶斯)会比弱假设的复杂算法(决策树)表现的好(这里所说的简单复杂是指算法的假设的模型空间),因为后者需要更多的数据防止过拟合。
4.Theretical guarantees are not what they seem
机器学习为什么能够学到东西,曾经看到的一个统计学上的定义感觉一定程度上说明了这个问题,即:what can be inferred fromdata plus a set of modeling assumptions ,with what reliability。我理解为,首先机器学习不是凭空就可以预测明天下雨还是打雷,是靠数据说话的,并且并不是说什么数据都可以,它是得满足条件的:第一,数据本身它得有知识,就好比说拿我七大姑八大姨的数据预测什么时候地球末日,如果你这么干,只能怪你读书少。当然更为专业的说法是,几乎所有的非随机的数据中,都会包含这样或那样的模式,这些模式的存在使机器得以据此进行归纳。
第二,独立同分布,其实以上两点,都可以说你的数据要和你的任务相互匹配,但是这里的独立同分布更强调的是训练和泛化的上下文环境要一样,意思是比如说你去对美国进行名义调查,不能只调查有钱人支持谁谁谁,而应该同等比例的在各个阶级都抽样调查才行,这样你获取的结果才是相对可靠的。
第三,数据实例之间非常相似的话,那么它们很大可能是相同的类标签。就好比说我和你的身体各项指标都差不了多少,但是你能跑5km不喘气,而我最后4km是只能爬,这显然不科学,不带你这么吃药的是吧!
第四,我们要学的模型并不是想怎么样就怎么样,从数学的角度就是,如果我们要从数据集中得到特征到类标签的映射关系,那么这个映射函数不会想怎么复杂就这么复杂,一般而言线性啊,几项式啊也就搞定啦。
当然还有一些前提比如说数据的平滑性等等。以上我们提到的是机器学习对数据的共有的前提假设。但是针对不同的算法而言,它又会有不同的前提蕴含在里面,比如说朴素贝叶斯的条件独立的假设。最后提一下机器学习的一个很有名气的理论,即:Vc bound(有兴趣的同学可以看下cousera上的机器学习基石课程) ,我现在感觉vc它是脱离了具体的算法,从概率的角度,根据训练集的数据量和算法假设的模型空间的大小,给出训练的误差和测试误差(泛化误差)差值的一个上界。主要的意思就是,如果你的模型越复杂(拟合数据的能力),假设的模型空间很大,有很大可能包含着真实分类器,但你就面临着过拟合的危险。但是你的模型简单的话,假设空间包含真实模型的概率下降,但是你的训练误差和泛化误差可以保证不会差多少。虽然这是一个数学上的分析,但就好像我说的,它脱离了具体的算法,所以它所说的上界极其宽松,以至于我感觉在实际应用中,没有什么实际意思,更多是在告诉你要控制好模型的复杂度。在引用下论文中提到的一句话给这段结个高大上的尾巴,“learning
is a complexphenomenon ,and just because a learner has a theoretical justification andworks in practice doesn’t mean the former is the reason for the latter”。
4.Intuitionfails in high dimensions
Curse of dimensionality,高维诅咒,一个多么厉害的名字,其实说白啦,就是说随着数据维度的增加给算法带来的问题,我感觉 主要有三点。第一, 输入空间大大小会随着维度的增加而指数及的增长,比如说64维的01向量,有多少个,2的64次方喂,简直不可理喻。
第二, 假设我用knn分析人们有钱没钱,然后我把身高体重什么什么的特征全部加进来分析,你认为得到的最邻近的数据点真的可信吗,应该会完全的淹没在噪声维里吧。
第三, 就算所有的数据维度都和任务相关,那可能更糟,想想在一个二维数据里和你距离为1的是个圈,三维是个球,4维不知道,反正空间一步一步增大,导致很多数据点都是临近的。但是这个解释,我不是很认同,毕竟整体空间也是啦啦的往上长。所以我认为,考虑一个现实生活的例子,提取每个人的所有特征,你认为人与人在每个维度是都不同,或者都差不多?我感觉更可能是在一部分维度上相同,一部分不同才更合理,所以这样就导致人与人之间的差距都不会太大。

相关文章推荐
- 做论坛签名外链 我们需要注意什么?
- c语言 关于数组 我们需要注意什么
- 我们需要注意什么?
- 画原型图时我们需要注意些什么
- SOA从试点到普及,我们还需要什么?
- 由C++转向C#:我们需要注意哪些方面的变化?
- 菜鸟须知:我们因为什么需要防火墙[转]
- 问题3:在网上发布信息你认为需要注意什么?不少于50字
- 自己写一个BLOG程序需要注意什么
- 我们需要什么呢?
- 哈希查找因何快?我们使用它需要付出什么代价
- 我们需要什么呢?
- 在国内读计算机研究生,需要注意什么
- 由C++转向C#:我们需要注意哪些方面的变化
- [ChneChen的随笔][管理之道]什么才是我们需要的解决问题的方法(从如何限制公司电脑使用U盘解决之道谈起)
- 由C++转向C#:我们需要注意哪些方面的变化?
- 我们这些普通的网民需要知道什么是 WEB2。0吗??【WEB2。0详解 预测模式】