总结:One weird trick for parallelizing convolutional neural networks
2015-01-17 21:36
651 查看
以下是本人对这篇paper的一个理解,但感觉有些地方似乎有所缺漏,望有所感悟的朋友可以加以指点。谢谢
该文中,作者提出了两种并行方法,data parallelism和model parallelism.
data parallelism:不同的worker跑不同的数据样例。
model parallelism:不同的worker跑同一个model中的不同部分(如神经元)——主要解决单个woker内存不足以存放全连接层的所有参数问题,通过将参数分放到不同work,并将其输入 copy到这些worker来实现整个全连接层的计算。
而为了更大程度的进行并行化,针对卷积层和全连接层的不同性质,采用不同的并行方法。即在训练cnn模型的过程中,结合了两种并行方法。
下面是关于卷积层和全连接层的性质:
卷积层:包含90%~95%的计算,却只有大约5%的参数
全连接层:包含5-10%的计算,却有着95%的参数,
如图:
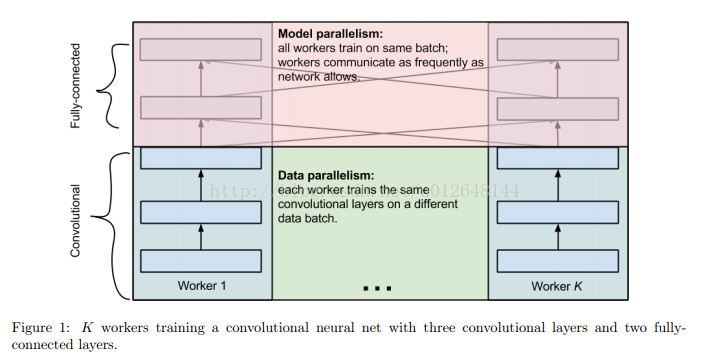
下面的作者的并行方案:
forward pass:
1.给不同的worker输入不同的数据样例,以batch为单位。
2.每个work各自计算卷积层。
3.对于全连接层的构建,作者给出了3中方案。
(1)K个worker,每个worker将其最后一层卷积层的activities发送给其他worker,那么每个worker将有K*batch size个examples,然后计算这些examples的全脸阶层。
(2)一个worker先将其最后一层卷积层的activites发送给其他所有的worker,然后所有的worker同时计算这个worker发送的数据的全连接层。在计算的同时另一个worke对其最后一层卷积层的activites进行广播。其它层同理。由此实现了计算和通信的重叠。
(3)所有的worker先发送1/K的examples给所有其他的workers,然后在像(2)一样处理数据。(这个我还不是很理解其中的优化原理)
backward pass:
1.每个worker计算其全连接层的gradients。
2.针对forward的3中不同方案,有3中不同的backward方案:
(1)对于方案(1),每个worker要将其计算的每个example的梯度发送回这个example进行forward pass的worker。
(2)对于方案(2),梯度的发送也如forward pass类似,实现通信和计算的重叠。
(3)类似于方案(2)。
该文中,作者提出了两种并行方法,data parallelism和model parallelism.
data parallelism:不同的worker跑不同的数据样例。
model parallelism:不同的worker跑同一个model中的不同部分(如神经元)——主要解决单个woker内存不足以存放全连接层的所有参数问题,通过将参数分放到不同work,并将其输入 copy到这些worker来实现整个全连接层的计算。
而为了更大程度的进行并行化,针对卷积层和全连接层的不同性质,采用不同的并行方法。即在训练cnn模型的过程中,结合了两种并行方法。
下面是关于卷积层和全连接层的性质:
卷积层:包含90%~95%的计算,却只有大约5%的参数
全连接层:包含5-10%的计算,却有着95%的参数,
如图:
下面的作者的并行方案:
forward pass:
1.给不同的worker输入不同的数据样例,以batch为单位。
2.每个work各自计算卷积层。
3.对于全连接层的构建,作者给出了3中方案。
(1)K个worker,每个worker将其最后一层卷积层的activities发送给其他worker,那么每个worker将有K*batch size个examples,然后计算这些examples的全脸阶层。
(2)一个worker先将其最后一层卷积层的activites发送给其他所有的worker,然后所有的worker同时计算这个worker发送的数据的全连接层。在计算的同时另一个worke对其最后一层卷积层的activites进行广播。其它层同理。由此实现了计算和通信的重叠。
(3)所有的worker先发送1/K的examples给所有其他的workers,然后在像(2)一样处理数据。(这个我还不是很理解其中的优化原理)
backward pass:
1.每个worker计算其全连接层的gradients。
2.针对forward的3中不同方案,有3中不同的backward方案:
(1)对于方案(1),每个worker要将其计算的每个example的梯度发送回这个example进行forward pass的worker。
(2)对于方案(2),梯度的发送也如forward pass类似,实现通信和计算的重叠。
(3)类似于方案(2)。

相关文章推荐
- 卷积神经网络的并行化模型——One weird trick for parallelizing convolutional neural networks
- One weird trick for parallelizing convolutional neural networks 读笔记
- 论文《Convolutional Neural Networks for Sentence Classification》总结
- 论文《Recurrent Convolutional Neural Networks for Text Classification》总结
- Convolutional Neural Networks for Speech
- Convolutional Neural Networks for Visual Recognition
- ImageNet Classification with Deep Convolutional Neural Networks泛读总结
- UNDERSTANDING CONVOLUTIONAL NEURAL NETWORKS FOR NLP
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
- Convolutional Neural Networks for Visual Recognition——笔记1
- 深度学习论文理解3:Flexible, high performance convolutional neural networks for image classification
- Convolutional Neural Networks for Visual Recognition 4
- Convolutional Neural Networks for Visual Recognition 7
- Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
- Convolutional Neural Networks for No-Reference Image Quality Assessment(泛读)
- Convolutional Neural Networks for Visual Recognition 5
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 文章总结
- Convolutional Neural Networks for Sentence Classification笔记整理
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
- 卷积神经网络在自然语言处理的应用Understanding Convolutional Neural Networks for NLP