Hadoop家族学习路线图
2015-01-06 09:41
288 查看
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop,
Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
前言
使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了。Hadoop在大数据领域的成功,更引发了它本身的加速发展。现在Hadoop家族产品,已经达到20个了之多。
有必要对自己的知识做一个整理了,把产品和技术都串起来。不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备。
本文为“Hadoop家族”开篇,Hadoop家族学习路线图
目录
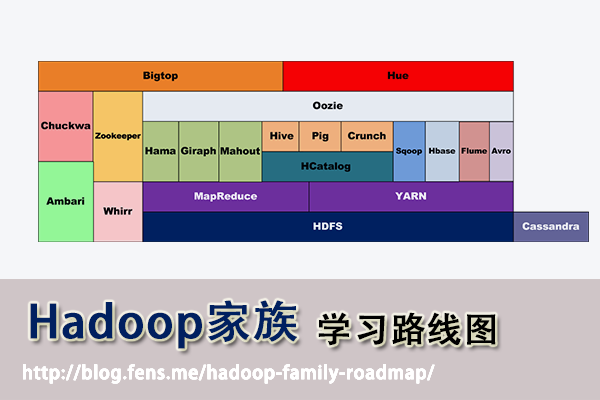
Hadoop家族产品
Hadoop家族学习路线图
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
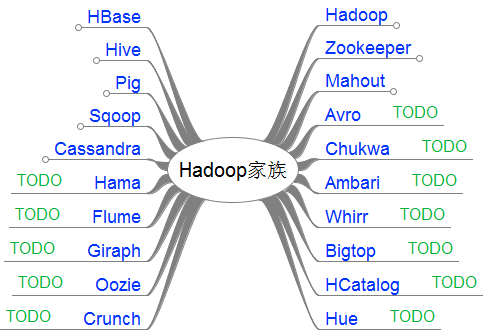
接下来,我把这20个产品,分成了2类。
第一类,是我已经掌握的
第二类,是TODO准备继续学习的
一句话产品介绍:
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig
Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC
Server上搭建起大规模结构化存储集群。
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL
,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google
BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身
Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
Apache Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合
Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架,
Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
Apache Giraph: 是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自
BSP (bulk synchronous parallel) 和 Google 的 Pregel。
Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Apache Crunch: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库
Apache Whirr: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon
EC2和Rackspace的服务。
Apache Bigtop: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。
Apache HCatalog: 是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。
Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN,
HBase, Hive, Pig的web化操作和管理。
Hadoop
Hadoop学习路线图
Yarn学习路线图
用Maven构建Hadoop项目
Hadoop历史版本安装
Hadoop编程调用HDFS
海量Web日志分析 用Hadoop提取KPI统计指标
用Hadoop构建电影推荐系统
创建Hadoop母体虚拟机
克隆虚拟机增加Hadoop节点
R语言为Hadoop注入统计血脉
RHadoop实践系列之一 Hadoop环境搭建
用MapReduce实现矩阵乘法
PageRank算法并行实现
PeopleRank从社交网络中发现个体价值
Hive
Hive学习路线图
Hive安装及使用攻略
Hive导入10G数据的测试
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
Pig
Pig学习路线图
Zookeeper
Zookeeper学习路线图
ZooKeeper伪分步式集群安装及使用
ZooKeeper实现分布式队列Queue
ZooKeeper实现分布式FIFO队列
基于Zookeeper的分步式队列系统集成案例
HBase
HBase学习路线图
在Ubuntu中安装HBase
RHadoop实践系列之四 rhbase安装与使用
Mahout
Mahout学习路线图
用R解析Mahout用户推荐协同过滤算法(UserCF)
RHadoop实践系列之三
R实现MapReduce的协同过滤算法
用Maven构建Mahout项目
Mahout推荐算法API详解
从源代码剖析Mahout推荐引擎
Mahout分步式程序开发
基于物品的协同过滤ItemCF
Mahout分步式程序开发 聚类Kmeans
用Mahout构建职位推荐引擎
Mahout构建图书推荐系统
Sqoop
Sqoop学习路线图
Cassandra
Cassandra学习路线图
Cassandra单集群实验2个节点
R利剑NoSQL系列文章 之 Cassandra
跟上创新的脚步,不断坚持:(TODO列表,不定期更新)
Avro, Ambari, Chukwa, Hama, Flume, Giraph, Oozie, Crunch, Whirr, Bigtop, HCatalog, Hue
欢迎大家留言,提出宝贵建议!
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
Posted:
Sep 3, 2013
Tags:
HadoophiveMahoutRrhadoopRHive
Comments:
8
Comments
算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据1G, 10G, 100G, TB, PB。 由于大数据所带来的单机性能问题,可能会一去不复返了。
RHadoop实践是一套系列文章,主要包括”Hadoop环境搭建”,”RHadoop安装与使用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容
易。此文虽为入门文章,但R,Java,Hadoop基础知识还是需要大家提前掌握。
关于作者
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/

前言
写过几篇关于RHadoop的技术性文章,都是从统计的角度,介绍如何让R语言利用Hadoop处理大数据。今天决定反过来,从计算机开发人员的角度,介绍如何让Hadoop结合R语言,能做统计分析的事情。
目录
R语言介绍
Hadoop介绍
为什么要让Hadoop结合R语言?
如何让Hadoop结合R语言?
R和Hadoop在实际中的案例
R语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R本来是由来自新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发(也因此称为R),现在由“R开发核心团队”负责开发。R是基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现。R的语法是来自Scheme。
跨平台,许可证
R的源代码可自由下载使用,GNU通用公共许可证,可在多种平台下运行,包括UNIX,Linux,Windows和MacOS。R主要是以命令行操作为主,同时支持GUI的图形用户界面。
R的数字基因
R内建多种统计学及数字分析功能。因为S的血缘,R比其他统计学或数学专用的编程语言有更强的物件导向功能。
R的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。
虽然R主要用于统计分析或者开发统计相关的软体,但也有人用作矩阵计算。其分析速度可媲美GNU Octave甚至商业软件MATLAB。
代码库
CRAN为Comprehensive R Archive Network的简称。它除了收藏了R的执行档下载版、源代码和说明文件,也收录了各种用户撰写的软件包。全球有超过一百个CRAN镜像站,上万个第三方的软件包。
R的行业应用
统计分析,应用数学,计量经济,金融分析,财经分析,人文科学,数据挖掘,人工智能,生物信息学,生物制药,全球地理科学,数据可视化。
商业竞争对手
SAS:(Statistical Analysis System),是SAS公司推出的一款用于数据分析和和决策支持的大型集成式模块化软件系统。
SPSS:(Statistical Product and Service Solutions)是IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称。
Matlab:(MATrix LABoratory),是MathWorks公司出品的一款商业数学软件。MATLAB是一种用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境。
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large
data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
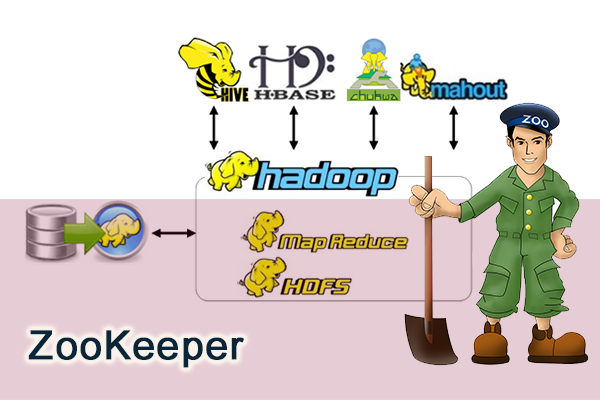
Hadoop的家族成员:Hive, HBase, Zookeeper, Avro, Pig, Ambari, Sqoop, Mahout, Chukwa
Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
自2006年,Hadoop以MapReduce和HDFS独立发展开始,到今年2013年不过7年时间,Hadoop的家族已经孵化出多个Apache的顶级项目。特别是最近1-2年,发展速度越来越快,又融入了很多新技术(YARN, Hcatalog, Oozie, Cassandra),都有点让我们都学不过来了。
问题1: Hadoop的家族如此之强大,为什么还要结合R语言?
问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?
下面我尝试着做一个解答:
问题1: Hadoop的家族如此之强大,为什么还要结合R语言?
a. Hadoop家族的强大之处,在于对大数据的处理,让原来的不可能(TB,PB数据量计算),成为了可能。
b. R语言的强大之处,在于统计分析,在没有Hadoop之前,我们对于大数据的处理,要取样本,假设检验,做回归,长久以来R语言都是统计学家专属的工具。
c. 从a和b两点,我们可以看出,hadoop重点是全量数据分析,而R语言重点是样本数据分析。 两种技术放在一起,刚好是最长补短!
d. 模拟场景:对1PB的新闻网站访问日志做分析,预测未来流量变化
d1:用R语言,通过分析少量数据,对业务目标建回归建模,并定义指标。
d2:用Hadoop从海量日志数据中,提取指标数据
d3:用R语言模型,对指标数据进行测试和调优
d4:用Hadoop分步式算法,重写R语言的模型,部署上线
这个场景中,R和Hadoop分别都起着非常重要的作用。以计算机开发人员的思路,所有有事情都用Hadoop去做,没有数据建模和证明,”预测的结果”一定是有问题的。以统计人员的思路,所有的事情都用R去做,以抽样方式,得到的“预测的结果”也一定是有问题的。
所以让二者结合,是产界业的必然的导向,也是产界业和学术界的交集,同时也为交叉学科的人才提供了无限广阔的想象空间。
问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?
a. Mahout是基于Hadoop的数据挖掘和机器学习的算法框架,Mahout的重点同样是解决大数据的计算的问题。
b. Mahout目前已支持的算法包括,协同过滤,推荐算法,聚类算法,分类算法,LDA, 朴素bayes,随机森林。上面的算法中,大部分都是距离的算法,可以通过矩阵分解后,充分利用MapReduce的并行计算框架,高效地完成计算任务。
c. Mahout的空白点,还有很多的数据挖掘算法,很难实现MapReduce并行化。Mahout的现有模型,都是通用模型,直接用到的项目中,计算结果只会比随机结果好一点点。Mahout二次开发,要求有深厚的JAVA和Hadoop的技术基础,最好兼有 “线性代数”,“概率统计”,“算法导论” 等的基础知识。所以想玩转Mahout真的不是一件容易的事情。
d. R语言同样提供了Mahout支持的约大多数算法(除专有算法),并且还支持大量的Mahout不支持的算法,算法的增长速度比mahout快N倍。并且开发简单,参数配置灵活,对小型数据集运算速度非常快。
虽然,Mahout同样可以做数据挖掘和机器学习,但是和R语言的擅长领域并不重合。集百家之长,在适合的领域选择合适的技术,才能真正地“保质保量”做软件。
一旦市场有需求,自然会有商家填补这个空白。
1). RHadoop
RHadoop是一款Hadoop和R语言的结合的产品,由RevolutionAnalytics公司开发,并将代码开源到github社区上面。RHadoop包含三个R包 (rmr,rhdfs,rhbase),分别是对应Hadoop系统架构中的,MapReduce, HDFS, HBase 三个部分。
参考文章:
RHadoop实践系列之二:RHadoop安装与使用
RHadoop实践系列之四
rhbase安装与使用
2). RHive
RHive是一款通过R语言直接访问Hive的工具包,是由NexR一个韩国公司研发的。
参考文章:
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
3). 重写Mahout
用R语言重写Mahout的实现也是一种结合的思路,我也做过相关的尝试。
参考文章:
用R解析Mahout用户推荐协同过滤算法(UserCF)
4).Hadoop调用R
上面说的都是R如何调用Hadoop,当然我们也可以反相操作,打通JAVA和R的连接通道,让Hadoop调用R的函数。但是,这部分还没有商家做出成形的产品。
我写了2个例子,大家可以自己尝试着结合,做出不一样的应用来。
参考文章:
Rserve与Java的跨平台通信
解惑rJava R与Java的高速通道
在公司部署这套环境,同样需要多个部门,多种人才的的配合。Hadoop运维,Hadoop算法研发,R语言建模,R语言MapReduce化,软件开发,测试等等。。。
所以,这样的案例并不太多。
我做过一些尝试和努力,已经整理成文章的有3个项目,文章中仅仅是实现思路。
参考文章:
RHadoop实践系列之三
R实现MapReduce的协同过滤算法
RHadoop实验 – 统计邮箱出现次数
用RHive从历史数据中提取逆回购信息
展位未来
对于R和Hadoop的结合,在近几年,肯定会生成爆发式的增长的。但由于跨学科会造成技术壁垒,人才会远远跟不上市场的需求。
所以,肯定会有更多的大数据工具,被发明!机会就在我们的手中,也许明天你的创新,就是我们追逐的方向!!
加油!!
######################################################
看文字不过瘾,作者视频讲解,请访问网站:http://onbook.me/video
######################################################
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/
Posted:
Aug 12, 2013
Tags:
Hadoopzkznodezookeeper分布式集群
Comments:
7
Comments
现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-zookeeper-intro/
前言
ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品。在单机中,系统协作大都是进程级的操作。分布式系统中,服务协作都是跨服务器才能完成的。在ZooKeeper之前,我们对于协作服务大都使用消息中间件,随着分布式系统的普及,用消息中间件完成协作,会有大量的程序开发。ZooKeeper直接面向于分布式系统,可以减少我们自己的开发,帮助我们更好完成分布式系统的数据管理问题。
目录
zookeeper介绍
zookeeper单节点安装
zookeeper伪分布式集群安装
zookeeper命令行操作
Java编程现实命令行操作
ZooKeeper是作为分布式协调服务,是不需要依赖于Hadoop的环境,也可以为其他的分布式环境提供服务。
Linux Ubuntu 12.04.2 LTS 64bit server
Java: 1.6.0_29 64-Bit Server VM
下载zookeeper
修改配置文件conf/zoo.cfg
非常简单,我们已经配置好了的zookeeper单节点
启动zookeeper
单节点的时,Mode会显示为standalone
停止ZooKeeper服务
由于我的测试环境PC数量有限,所以在一台PC中,启动3个ZooKeeper的实例。
创建环境目录
分别修改配置文件
修改:dataDir,clientPort
增加:集群的实例,server.X,”X”表示每个目录中的myid的值
3个节点的ZooKeeper集群配置完成,接下来我们的启动服务。
启动集群
我们可以看到zk2是leader,zk1和zk3是follower
查看ZooKeeper物理文件目录结构
集群已连接,下面我们要使用一下,ZooKeeper的命令行操作。
命令行操作
通过help打印命令行帮助
ZooKeeper的结构,很像是目录结构,我们看到了像ls这样熟悉的命令。
运行结果:
pom.xml,maven配置文件
基础讲完,接下来就让我动手管理起,我们自己的分布式系统吧。
转载请注明出处:
http://blog.fens.me/hadoop-zookeeper-intro/
Posted:
Jul 30, 2013
Tags:
HadoophiveITIT技术玩金融RRHive逆回购金融
Comments:
11
Comments
金融是离钱最近的市场,也是变现的好渠道!今天就开始踏上“用IT技术玩金融”之旅!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/finance-rhive-repurchase/

前言
接触金融时间并不太长,对我来说第一个操作的业务,就是逆回购。逆回购对于大部分人来说,都是一个新鲜词,就算是炒股多年的玩家,可能也是在2013年6月份发生银行缺钱的事件之后才了解的。隔夜的银行间拆借利率达到了30%,简单来说银行缺钱了!各种机构 分分出售股票,债券,兑换成现金借给应银行。个人用户也都取出存款,通过逆回购,把钱借给银行。30%的利率,让所有人在那一周都为之兴奋,只有银行在惶恐。
目录
逆回购简介
历史数据模型
通过用RHive提取数据
简单策略实现
债券质押式回购简单地说就是交易双方以债券为质押品的一种短期资金借贷行为。其中债券持有人(正回购方)将债券质押而获得资金使用权,到约定的时间还本并支付一定的利息,从而“赎回”债券。而资金持有人(逆回购方)就是正回购方的交易对手。在实际交易中债券是质押给了第三方即中国结算公司,这样交易双方否更加安全、便捷。
可回购的债券
所有的国债、绝大部分企业债、公司债和分离债的纯债都可用于债券回购交易。沪深交易所每周都会公布可回购债券的折算率,上面没有但可交易的品种就是不可回购的债券。折算率简单说,就是把债券质押时,交易所按债券面值给出的可质押的比率。
现在交易的回购品种
我们仅列出个人投资者经常参与的公司债(包括企业债等)回购品种。
上海证券交易所可交易的质押式回购(括弧中为交易代码)分为1日(204001)、2日(204002)、3日(204003)、4日(204004)、7日(204007)、14日(204014)、28日(204028)、91日(204091)、182日(204182)共9个品种。深圳交易所按回购期限分为分为1日(131810)、2日(131811)、3日(131800)、7日(131801)共4个品种。其中经常交易的只有沪深1日和7日四个品种,并且沪市的日均交易量又远远大于深市的交易量。
以上逆回购定义摘自:http://finance.sina.com.cn/money/bond/20121016/180713385513.shtml
tradedate:交易日期
tradetime:交易时间
securityid:股票ID
bidpx1:买一
bidsize1:买一交易量
offerpx1:卖一
bidsize1:卖一交易量
查看所有股票历史数据分片:测试数据从20130627–20130726。
分为提取”上交所一天逆回购”(204001),和”深交所一天逆回购”(131810),从7月22日至7月26日的一周数据。
查看数据结果集
加载到R的内存中。
用ggplot2做数据可视化
一周数据的走势
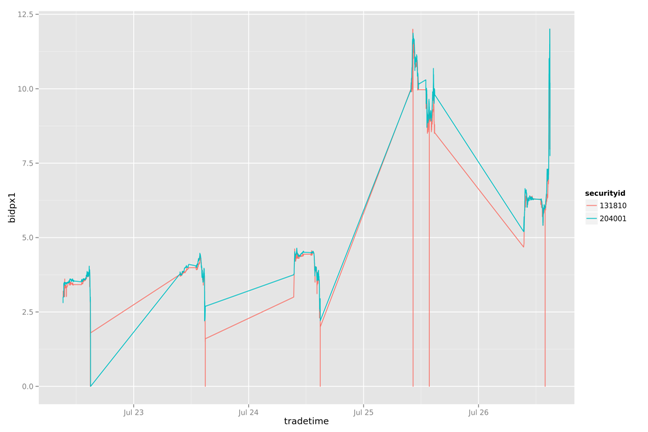
一天数据的走势
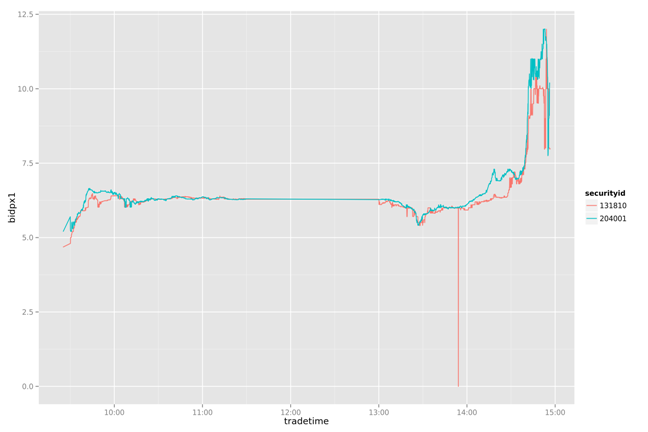
下面做一个简单的策略分析:通过204001变化,判断131810的卖点。
把131810和204001按每分钟标准化
设置当131810和204001有交点的时候,提取卖出信号
当后一个交点的卖一价格大于前一个交点的卖一价格10%以上,做为局部最优的卖出信号点
提取131810,204001的数据,存储在t_reverse_repurchase表中
加载软件包
获得一天的数据并做ETL
20130722
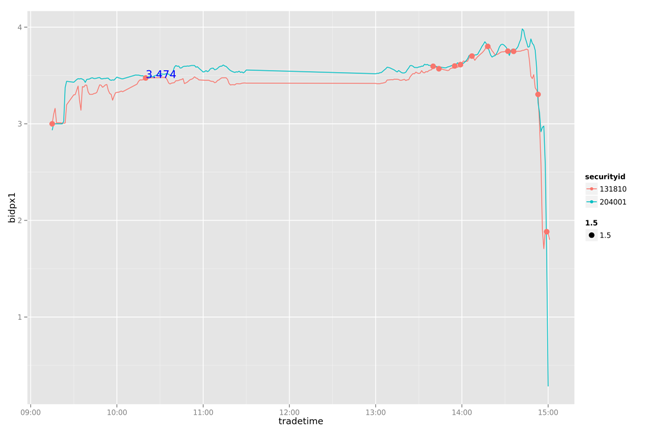
20130723
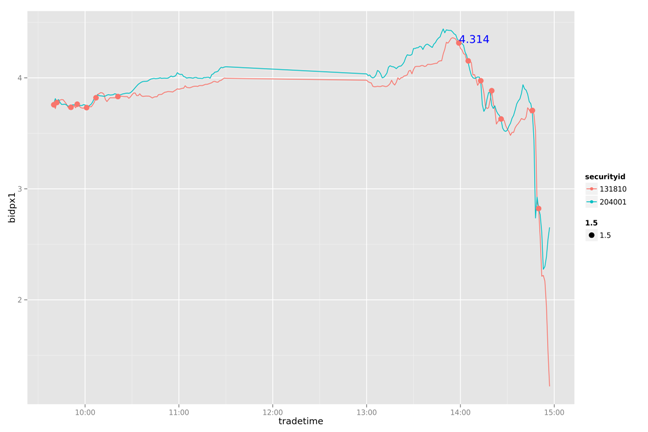
20130724
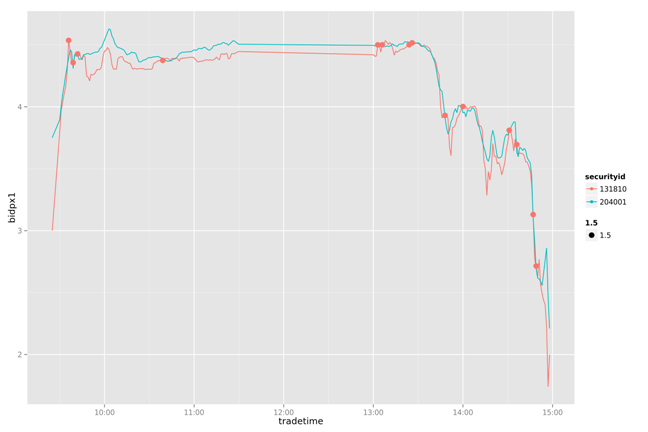
20130725
20130726
通过对一周数据的比较我们发现,这个简单的策略能我们带来一些收益。虽然不是全局最优的,但比人为的判断会更有依据。
用IT技术玩金融系列文章,第一篇就当是一个抛砖引玉的开始,后面的文章会更精彩。
######################################################
看文字不过瘾,作者视频讲解,请访问网站:http://onbook.me/video
######################################################
转载请注明出处:
http://blog.fens.me/finance-rhive-repurchase/
Posted:
Jul 27, 2013
Tags:
HadoophivelinuxRRHivesql
Comments:
4
Comments
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明:
http://blog.fens.me/nosql-r-hive/
第四篇 R利剑Hive,分为5个章节。
Hive介绍
Hive安装
RHive安装
RHive函数库
RHive基本使用操作
无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式
上面内容摘自 百度百科(http://baike.baidu.com/view/699292.htm)
hive与关系数据库的区别:
数据存储不同:hive基于hadoop的HDFS,关系数据库则基于本地文件系统
计算模型不同:hive基于hadoop的mapreduce,关系数据库则基于索引的内存计算模型
应用场景不同:hive是OLAP数据仓库系统提供海量数据查询的,实时性很差;关系数据库是OLTP事务系统,为实时查询业务服务
扩展性不同:hive基于hadoop很容易通过分布式增加存储能力和计算能力,关系数据库水平扩展很难,要不断增加单机的性能
Hadoop安装,请参考:Hadoop环境搭建, 创建Hadoop母体虚拟机
Hive的安装,请参考:Hive安装及使用攻略
Hadoop-1.0.3的下载地址
http://archive.apache.org/dist/hadoop/core/hadoop-1.0.3/ Hive-0.9.0的下载地址
http://archive.apache.org/dist/hive/hive-0.9.0/ Hive安装好后
启动hiveserver的服务
打开hive shell
安装R:Ubuntu 12.04,请更新源再下载R2.15.3版本
安装R依赖库:rjava
安装RHive
Hive和RHive的基本操作对比:
创建临时表
按范围分割字段数据
Hive操作HDFS
转载请注明:
http://blog.fens.me/nosql-r-hive/
Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
前言
使用Hadoop已经有一段时间了,从开始的迷茫,到各种的尝试,到现在组合应用….慢慢地涉及到数据处理的事情,已经离不开hadoop了。Hadoop在大数据领域的成功,更引发了它本身的加速发展。现在Hadoop家族产品,已经达到20个了之多。
有必要对自己的知识做一个整理了,把产品和技术都串起来。不仅能加深印象,更可以对以后的技术方向,技术选型做好基础准备。
本文为“Hadoop家族”开篇,Hadoop家族学习路线图
目录
Hadoop家族产品
Hadoop家族学习路线图
1. Hadoop家族产品
截止到2013年,根据cloudera的统计,Hadoop家族产品已经达到20个!http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
接下来,我把这20个产品,分成了2类。
第一类,是我已经掌握的
第二类,是TODO准备继续学习的
一句话产品介绍:
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig
Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC
Server上搭建起大规模结构化存储集群。
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL
,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google
BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身
Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
Apache Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合
Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架,
Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
Apache Giraph: 是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自
BSP (bulk synchronous parallel) 和 Google 的 Pregel。
Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Apache Crunch: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库
Apache Whirr: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon
EC2和Rackspace的服务。
Apache Bigtop: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。
Apache HCatalog: 是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。
Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN,
HBase, Hive, Pig的web化操作和管理。
2. Hadoop家族学习路线图
下面我将分别介绍各个产品的安装和使用,以我经验总结我的学习路线。Hadoop
Hadoop学习路线图
Yarn学习路线图
用Maven构建Hadoop项目
Hadoop历史版本安装
Hadoop编程调用HDFS
海量Web日志分析 用Hadoop提取KPI统计指标
用Hadoop构建电影推荐系统
创建Hadoop母体虚拟机
克隆虚拟机增加Hadoop节点
R语言为Hadoop注入统计血脉
RHadoop实践系列之一 Hadoop环境搭建
用MapReduce实现矩阵乘法
PageRank算法并行实现
PeopleRank从社交网络中发现个体价值
Hive
Hive学习路线图
Hive安装及使用攻略
Hive导入10G数据的测试
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
Pig
Pig学习路线图
Zookeeper
Zookeeper学习路线图
ZooKeeper伪分步式集群安装及使用
ZooKeeper实现分布式队列Queue
ZooKeeper实现分布式FIFO队列
基于Zookeeper的分步式队列系统集成案例
HBase
HBase学习路线图
在Ubuntu中安装HBase
RHadoop实践系列之四 rhbase安装与使用
Mahout
Mahout学习路线图
用R解析Mahout用户推荐协同过滤算法(UserCF)
RHadoop实践系列之三
R实现MapReduce的协同过滤算法
用Maven构建Mahout项目
Mahout推荐算法API详解
从源代码剖析Mahout推荐引擎
Mahout分步式程序开发
基于物品的协同过滤ItemCF
Mahout分步式程序开发 聚类Kmeans
用Mahout构建职位推荐引擎
Mahout构建图书推荐系统
Sqoop
Sqoop学习路线图
Cassandra
Cassandra学习路线图
Cassandra单集群实验2个节点
R利剑NoSQL系列文章 之 Cassandra
跟上创新的脚步,不断坚持:(TODO列表,不定期更新)
Avro, Ambari, Chukwa, Hama, Flume, Giraph, Oozie, Crunch, Whirr, Bigtop, HCatalog, Hue
欢迎大家留言,提出宝贵建议!
转载请注明出处:
http://blog.fens.me/hadoop-family-roadmap/
Posted:
Sep 3, 2013
Tags:
HadoophiveMahoutRrhadoopRHive
Comments:
8
Comments
R语言为Hadoop注入统计血脉
RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析。Hadoop主要用来存储海量数据,R语言完成MapReduce算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据1G, 10G, 100G, TB, PB。 由于大数据所带来的单机性能问题,可能会一去不复返了。
RHadoop实践是一套系列文章,主要包括”Hadoop环境搭建”,”RHadoop安装与使用”,”R实现MapReduce的协同过滤算法”,”HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容
易。此文虽为入门文章,但R,Java,Hadoop基础知识还是需要大家提前掌握。
关于作者
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/
前言
写过几篇关于RHadoop的技术性文章,都是从统计的角度,介绍如何让R语言利用Hadoop处理大数据。今天决定反过来,从计算机开发人员的角度,介绍如何让Hadoop结合R语言,能做统计分析的事情。
目录
R语言介绍
Hadoop介绍
为什么要让Hadoop结合R语言?
如何让Hadoop结合R语言?
R和Hadoop在实际中的案例
1. R语言介绍
起源R语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R本来是由来自新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发(也因此称为R),现在由“R开发核心团队”负责开发。R是基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现。R的语法是来自Scheme。
跨平台,许可证
R的源代码可自由下载使用,GNU通用公共许可证,可在多种平台下运行,包括UNIX,Linux,Windows和MacOS。R主要是以命令行操作为主,同时支持GUI的图形用户界面。
R的数字基因
R内建多种统计学及数字分析功能。因为S的血缘,R比其他统计学或数学专用的编程语言有更强的物件导向功能。
R的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。
虽然R主要用于统计分析或者开发统计相关的软体,但也有人用作矩阵计算。其分析速度可媲美GNU Octave甚至商业软件MATLAB。
代码库
CRAN为Comprehensive R Archive Network的简称。它除了收藏了R的执行档下载版、源代码和说明文件,也收录了各种用户撰写的软件包。全球有超过一百个CRAN镜像站,上万个第三方的软件包。
R的行业应用
统计分析,应用数学,计量经济,金融分析,财经分析,人文科学,数据挖掘,人工智能,生物信息学,生物制药,全球地理科学,数据可视化。
商业竞争对手
SAS:(Statistical Analysis System),是SAS公司推出的一款用于数据分析和和决策支持的大型集成式模块化软件系统。
SPSS:(Statistical Product and Service Solutions)是IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称。
Matlab:(MATrix LABoratory),是MathWorks公司出品的一款商业数学软件。MATLAB是一种用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境。
2. Hadoop介绍
Hadoop对于计算机的人,都是耳熟能说的技术了。Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large
data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
Hadoop的家族成员:Hive, HBase, Zookeeper, Avro, Pig, Ambari, Sqoop, Mahout, Chukwa
Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
自2006年,Hadoop以MapReduce和HDFS独立发展开始,到今年2013年不过7年时间,Hadoop的家族已经孵化出多个Apache的顶级项目。特别是最近1-2年,发展速度越来越快,又融入了很多新技术(YARN, Hcatalog, Oozie, Cassandra),都有点让我们都学不过来了。
3. 为什么要让Hadoop结合R语言?
前面两章,R语言介绍和Hadoop介绍,让我们体会到了,两种技术在各自领域的强大。很多开发人员在计算机的角度,都会提出下面2个问题。问题1: Hadoop的家族如此之强大,为什么还要结合R语言?
问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?
下面我尝试着做一个解答:
问题1: Hadoop的家族如此之强大,为什么还要结合R语言?
a. Hadoop家族的强大之处,在于对大数据的处理,让原来的不可能(TB,PB数据量计算),成为了可能。
b. R语言的强大之处,在于统计分析,在没有Hadoop之前,我们对于大数据的处理,要取样本,假设检验,做回归,长久以来R语言都是统计学家专属的工具。
c. 从a和b两点,我们可以看出,hadoop重点是全量数据分析,而R语言重点是样本数据分析。 两种技术放在一起,刚好是最长补短!
d. 模拟场景:对1PB的新闻网站访问日志做分析,预测未来流量变化
d1:用R语言,通过分析少量数据,对业务目标建回归建模,并定义指标。
d2:用Hadoop从海量日志数据中,提取指标数据
d3:用R语言模型,对指标数据进行测试和调优
d4:用Hadoop分步式算法,重写R语言的模型,部署上线
这个场景中,R和Hadoop分别都起着非常重要的作用。以计算机开发人员的思路,所有有事情都用Hadoop去做,没有数据建模和证明,”预测的结果”一定是有问题的。以统计人员的思路,所有的事情都用R去做,以抽样方式,得到的“预测的结果”也一定是有问题的。
所以让二者结合,是产界业的必然的导向,也是产界业和学术界的交集,同时也为交叉学科的人才提供了无限广阔的想象空间。
问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?
a. Mahout是基于Hadoop的数据挖掘和机器学习的算法框架,Mahout的重点同样是解决大数据的计算的问题。
b. Mahout目前已支持的算法包括,协同过滤,推荐算法,聚类算法,分类算法,LDA, 朴素bayes,随机森林。上面的算法中,大部分都是距离的算法,可以通过矩阵分解后,充分利用MapReduce的并行计算框架,高效地完成计算任务。
c. Mahout的空白点,还有很多的数据挖掘算法,很难实现MapReduce并行化。Mahout的现有模型,都是通用模型,直接用到的项目中,计算结果只会比随机结果好一点点。Mahout二次开发,要求有深厚的JAVA和Hadoop的技术基础,最好兼有 “线性代数”,“概率统计”,“算法导论” 等的基础知识。所以想玩转Mahout真的不是一件容易的事情。
d. R语言同样提供了Mahout支持的约大多数算法(除专有算法),并且还支持大量的Mahout不支持的算法,算法的增长速度比mahout快N倍。并且开发简单,参数配置灵活,对小型数据集运算速度非常快。
虽然,Mahout同样可以做数据挖掘和机器学习,但是和R语言的擅长领域并不重合。集百家之长,在适合的领域选择合适的技术,才能真正地“保质保量”做软件。
4. 如何让Hadoop结合R语言?
从上一节我们看到,Hadoop和R语言是可以互补的,但所介绍的场景都是Hadoop和R语言的分别处理各自的数据。一旦市场有需求,自然会有商家填补这个空白。
1). RHadoop
RHadoop是一款Hadoop和R语言的结合的产品,由RevolutionAnalytics公司开发,并将代码开源到github社区上面。RHadoop包含三个R包 (rmr,rhdfs,rhbase),分别是对应Hadoop系统架构中的,MapReduce, HDFS, HBase 三个部分。
参考文章:
RHadoop实践系列之二:RHadoop安装与使用
RHadoop实践系列之四
rhbase安装与使用
2). RHive
RHive是一款通过R语言直接访问Hive的工具包,是由NexR一个韩国公司研发的。
参考文章:
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
3). 重写Mahout
用R语言重写Mahout的实现也是一种结合的思路,我也做过相关的尝试。
参考文章:
用R解析Mahout用户推荐协同过滤算法(UserCF)
4).Hadoop调用R
上面说的都是R如何调用Hadoop,当然我们也可以反相操作,打通JAVA和R的连接通道,让Hadoop调用R的函数。但是,这部分还没有商家做出成形的产品。
我写了2个例子,大家可以自己尝试着结合,做出不一样的应用来。
参考文章:
Rserve与Java的跨平台通信
解惑rJava R与Java的高速通道
5. R和Hadoop在实际中的案例
R和Hadoop的结合,技术门槛还是有点高的。对于一个人来说,不仅要掌握Linux, Java, Hadoop, R的技术,还要具备 软件开发,算法,概率统计,线性代数,数据可视化,行业背景 的一些基本素质。在公司部署这套环境,同样需要多个部门,多种人才的的配合。Hadoop运维,Hadoop算法研发,R语言建模,R语言MapReduce化,软件开发,测试等等。。。
所以,这样的案例并不太多。
我做过一些尝试和努力,已经整理成文章的有3个项目,文章中仅仅是实现思路。
参考文章:
RHadoop实践系列之三
R实现MapReduce的协同过滤算法
RHadoop实验 – 统计邮箱出现次数
用RHive从历史数据中提取逆回购信息
展位未来
对于R和Hadoop的结合,在近几年,肯定会生成爆发式的增长的。但由于跨学科会造成技术壁垒,人才会远远跟不上市场的需求。
所以,肯定会有更多的大数据工具,被发明!机会就在我们的手中,也许明天你的创新,就是我们追逐的方向!!
加油!!
######################################################
看文字不过瘾,作者视频讲解,请访问网站:http://onbook.me/video
######################################################
转载请注明出处:
http://blog.fens.me/r-hadoop-intro/
Posted:
Aug 12, 2013
Tags:
Hadoopzkznodezookeeper分布式集群
Comments:
7
Comments
ZooKeeper伪分布式集群安装及使用
让Hadoop跑在云端系列文章,介绍了如何整合虚拟化和Hadoop,让Hadoop集群跑在VPS虚拟主机上,通过云向用户提供存储和计算的服务。现在硬件越来越便宜,一台非品牌服务器,2颗24核CPU,配48G内存,2T的硬盘,已经降到2万块人民币以下了。这种配置如果简单地放几个web应用,显然是奢侈的浪费。就算是用来实现单节点的hadoop,对计算资源浪费也是非常高的。对于这么高性能的计算机,如何有效利用计算资源,就成为成本控制的一项重要议题了。
通过虚拟化技术,我们可以将一台服务器,拆分成12台VPS,每台2核CPU,4G内存,40G硬盘,并且支持资源重新分配。多么伟大的技术啊!现在我们有了12个节点的hadoop集群, 让Hadoop跑在云端,让世界加速。
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-zookeeper-intro/
前言
ZooKeeper是Hadoop家族的一款高性能的分布式协作的产品。在单机中,系统协作大都是进程级的操作。分布式系统中,服务协作都是跨服务器才能完成的。在ZooKeeper之前,我们对于协作服务大都使用消息中间件,随着分布式系统的普及,用消息中间件完成协作,会有大量的程序开发。ZooKeeper直接面向于分布式系统,可以减少我们自己的开发,帮助我们更好完成分布式系统的数据管理问题。
目录
zookeeper介绍
zookeeper单节点安装
zookeeper伪分布式集群安装
zookeeper命令行操作
Java编程现实命令行操作
1. zookeeper介绍
ZooKeeper是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以Standalone模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。ZooKeeper是作为分布式协调服务,是不需要依赖于Hadoop的环境,也可以为其他的分布式环境提供服务。
2. zookeeper单节点安装Standalones模式
系统环境:Linux Ubuntu 12.04.2 LTS 64bit server
Java: 1.6.0_29 64-Bit Server VM
~ uname -a Linux conan 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux ~ cat /etc/issue Ubuntu 12.04.2 LTS \n \l ~ java -version java version "1.6.0_29" Java(TM) SE Runtime Environment (build 1.6.0_29-b11) Java HotSpot(TM) 64-Bit Server VM (build 20.4-b02, mixed mode)
下载zookeeper
~ mkdir /home/conan/toolkit ~ cd /home/conan/toolkit ~ wget http://apache.dataguru.cn/zookeeper/stable/zookeeper-3.4.5.tar.gz ~ tar xvf zookeeper-3.4.5.tar.gz ~ mv zookeeper-3.4.5 zookeeper345 ~ cd zookeeper345 ~ ls -l drwxr-xr-x 2 conan conan 4096 Aug 12 04:34 bin -rw-r--r-- 1 conan conan 75988 Aug 12 04:34 build.xml -rw-r--r-- 1 conan conan 70223 Aug 12 04:34 CHANGES.txt drwxr-xr-x 2 conan conan 4096 Aug 12 04:34 conf drwxr-xr-x 10 conan conan 4096 Aug 12 04:34 contrib drwxr-xr-x 2 conan conan 4096 Aug 12 04:34 dist-maven drwxr-xr-x 6 conan conan 4096 Aug 12 04:34 docs -rw-r--r-- 1 conan conan 1953 Aug 12 04:34 ivysettings.xml -rw-r--r-- 1 conan conan 3120 Aug 12 04:34 ivy.xml drwxr-xr-x 4 conan conan 4096 Aug 12 04:34 lib -rw-r--r-- 1 conan conan 11358 Aug 12 04:34 LICENSE.txt -rw-r--r-- 1 conan conan 170 Aug 12 04:34 NOTICE.txt -rw-r--r-- 1 conan conan 1770 Aug 12 04:34 README_packaging.txt -rw-r--r-- 1 conan conan 1585 Aug 12 04:34 README.txt drwxr-xr-x 5 conan conan 4096 Aug 12 04:34 recipes drwxr-xr-x 8 conan conan 4096 Aug 12 04:34 src -rw-r--r-- 1 conan conan 1315806 Aug 12 04:34 zookeeper-3.4.5.jar -rw-r--r-- 1 conan conan 833 Aug 12 04:34 zookeeper-3.4.5.jar.asc -rw-r--r-- 1 conan conan 33 Aug 12 04:34 zookeeper-3.4.5.jar.md5 -rw-r--r-- 1 conan conan 41 Aug 12 04:34 zookeeper-3.4.5.jar.sha1
修改配置文件conf/zoo.cfg
~ mkdir /home/conan/zoo/zk0 ~ cp conf/zoo_sample.cfg conf/zoo.cfg ~ vi conf/zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/conan/zoo/zk0 clientPort=2181
非常简单,我们已经配置好了的zookeeper单节点
启动zookeeper
~ bin/zkServer.sh
JMX enabled by default
Using config: /home/conan/zoo/zk0/zookeeper345/bin/../conf/zoo.cfg
Usage: bin/zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
conan@conan:~/zoo/zk0/zookeeper345$ bin/zkServer.sh start
JMX enabled by default
Using config: /home/conan/zoo/zk0/zookeeper345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#zk的服务显示为QuorumPeerMain
~ jps
5321 QuorumPeerMain
5338 Jps
#查看运行状态
~ bin/zkServer.sh status
JMX enabled by default
Using config: /home/conan/zoo/zk0/zookeeper345/bin/../conf/zoo.cfg
Mode: standalone单节点的时,Mode会显示为standalone
停止ZooKeeper服务
~ bin/zkServer.sh stop JMX enabled by default Using config: /home/conan/zoo/zk0/zookeeper345/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED
3. zookeeper伪分布式集群安装
所谓 “伪分布式集群” 就是在,在一台PC中,启动多个ZooKeeper的实例。“完全分布式集群” 是每台PC,启动一个ZooKeeper实例。由于我的测试环境PC数量有限,所以在一台PC中,启动3个ZooKeeper的实例。
创建环境目录
~ mkdir /home/conan/zoo/zk1 ~ mkdir /home/conan/zoo/zk2 ~ mkdir /home/conan/zoo/zk3 #新建myid文件 ~ echo "1" > /home/conan/zoo/zk1/myid ~ echo "2" > /home/conan/zoo/zk2/myid ~ echo "3" > /home/conan/zoo/zk3/myid
分别修改配置文件
修改:dataDir,clientPort
增加:集群的实例,server.X,”X”表示每个目录中的myid的值
~ vi /home/conan/toolkit/zookeeper345/conf/zk1.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/conan/zoo/zk1 clientPort=2181 server.1=192.168.1.201:2888:3888 server.2=192.168.1.201:2889:3889 server.3=192.168.1.201:2890:3890 ~ vi /home/conan/toolkit/zookeeper345/conf/zk2.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/conan/zoo/zk2 clientPort=2182 server.1=192.168.1.201:2888:3888 server.2=192.168.1.201:2889:3889 server.3=192.168.1.201:2890:3890 ~ vi /home/conan/toolkit/zookeeper345/conf/zk3.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/conan/zoo/zk3 clientPort=2183 server.1=192.168.1.201:2888:3888 server.2=192.168.1.201:2889:3889 server.3=192.168.1.201:2890:3890
3个节点的ZooKeeper集群配置完成,接下来我们的启动服务。
启动集群
~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh start zk1.cfg ~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh start zk2.cfg ~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh start zk3.cfg ~ jps 5422 QuorumPeerMain 5395 QuorumPeerMain 5463 QuorumPeerMain 5494 Jps #查看节点状态 ~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh status zk1.cfg JMX enabled by default Using config: /home/conan/toolkit/zookeeper345/bin/../conf/zk1.cfg Mode: follower ~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh status zk2.cfg JMX enabled by default Using config: /home/conan/toolkit/zookeeper345/bin/../conf/zk2.cfg Mode: leader ~ /home/conan/toolkit/zookeeper345/bin/zkServer.sh status zk3.cfg JMX enabled by default Using config: /home/conan/toolkit/zookeeper345/bin/../conf/zk3.cfg Mode: follower
我们可以看到zk2是leader,zk1和zk3是follower
查看ZooKeeper物理文件目录结构
~ tree -L 3 /home/conan/zoo /home/conan/zoo ├── zk0 ├── zk1 │ ├── myid │ ├── version-2 │ │ ├── acceptedEpoch │ │ ├── currentEpoch │ │ ├── log.100000001 │ │ └── snapshot.0 │ └── zookeeper_server.pid ├── zk2 │ ├── myid │ ├── version-2 │ │ ├── acceptedEpoch │ │ ├── currentEpoch │ │ ├── log.100000001 │ │ └── snapshot.0 │ └── zookeeper_server.pid └── zk3 ├── myid ├── version-2 │ ├── acceptedEpoch │ ├── currentEpoch │ ├── log.100000001 │ └── snapshot.100000000 └── zookeeper_server.pid 7 directories, 18 files
4. zookeeper命令行操作
我们通过客户端连接ZooKeeper的集群,我们可以任意的zookeeper是进行连接。~ /home/conan/toolkit/zookeeper345/bin/zkCli.sh -server 192.168.1.201:2181 Connecting to 192.168.1.201 2013-08-12 05:25:39,260 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT 2013-08-12 05:25:39,267 [myid:] - INFO [main:Environment@100] - Client environment:host.name=conan 2013-08-12 05:25:39,269 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.6.0_29 2013-08-12 05:25:39,269 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Sun Microsystems Inc. 2013-08-12 05:25:39,270 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/home/conan/toolkit/jdk16/jre 2013-08-12 05:25:39,270 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/conan/toolkit/zookeeper345/bin/../build/classes:/home/conan/toolkit/zookeeper345/bin/../build/lib/*.jar:/home/conan/toolkit/zookeeper345/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/conan/toolkit/zookeeper345/bin/../lib/slf4j-api-1.6.1.jar:/home/conan/toolkit/zookeeper345/bin/../lib/netty-3.2.2.Final.jar:/home/conan/toolkit/zookeeper345/bin/../lib/log4j-1.2.15.jar:/home/conan/toolkit/zookeeper345/bin/../lib/jline-0.9.94.jar:/home/conan/toolkit/zookeeper345/bin/../zookeeper-3.4.5.jar:/home/conan/toolkit/zookeeper345/bin/../src/java/lib/*.jar:/home/conan/toolkit/zookeeper345/bin/../conf: 2013-08-12 05:25:39,271 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/home/conan/toolkit/jdk16/jre/lib/amd64/server:/home/conan/toolkit/jdk16/jre/lib/amd64:/home/conan/toolkit/jdk16/jre/../lib/amd64:/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib 2013-08-12 05:25:39,275 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp 2013-08-12 05:25:39,276 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler= 2013-08-12 05:25:39,276 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux 2013-08-12 05:25:39,277 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64 2013-08-12 05:25:39,281 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.5.0-23-generic 2013-08-12 05:25:39,282 [myid:] - INFO [main:Environment@100] - Client environment:user.name=conan 2013-08-12 05:25:39,282 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/conan 2013-08-12 05:25:39,283 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/conan/zoo 2013-08-12 05:25:39,284 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=192.168.1.201 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@22ba6c83 Welcome to ZooKeeper! JLine support is enabled [zk: 192.168.1.201(CONNECTING) 0] 2013-08-12 05:25:39,336 [myid:] - INFO [main-SendThread(192.168.1.201:2181):ClientCnxn$SendThread@966] - Opening socket connection to server 192.168.1.201/192.168.1.201:2181. Will not attempt to authenticate using SASL (Unable to locate a login configuration) 2013-08-12 05:25:39,345 [myid:] - INFO [main-SendThread(192.168.1.201:2181):ClientCnxn$SendThread@849] - Socket connection established to 192.168.1.201/192.168.1.201:2181, initiating session 2013-08-12 05:25:39,384 [myid:] - INFO [main-SendThread(192.168.1.201:2181):ClientCnxn$SendThread@1207] - Session establishment complete on server 192.168.1.201/192.168.1.201:2181, sessionid = 0x1406f3c1ef90001, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: 192.168.1.201(CONNECTED) 0]
集群已连接,下面我们要使用一下,ZooKeeper的命令行操作。
命令行操作
通过help打印命令行帮助
[zk: 192.168.1.201(CONNECTED) 1] help ZooKeeper -server host:port cmd args connect host:port get path [watch] ls path [watch] set path data [version] rmr path delquota [-n|-b] path quit printwatches on|off create [-s] [-e] path data acl stat path [watch] close ls2 path [watch] history listquota path setAcl path acl getAcl path sync path redo cmdno addauth scheme auth delete path [version] setquota -n|-b val path
ZooKeeper的结构,很像是目录结构,我们看到了像ls这样熟悉的命令。
#ls,查看/目录内容 [zk: 192.168.1.201(CONNECTED) 1] ls / [zookeeper] #create,创建一个znode节点 [zk: 192.168.1.201(CONNECTED) 2] create /node conan Created /node #ls,再查看/目录 [zk: 192.168.1.201(CONNECTED) 3] ls / [node, zookeeper] #get,查看/node的数据信息 [zk: 192.168.1.201(CONNECTED) 4] get /node conan cZxid = 0x100000006 ctime = Mon Aug 12 05:32:49 CST 2013 mZxid = 0x100000006 mtime = Mon Aug 12 05:32:49 CST 2013 pZxid = 0x100000006 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 0 #set,修改数据 [zk: 192.168.1.201(CONNECTED) 5] set /node fens.me cZxid = 0x100000006 ctime = Mon Aug 12 05:32:49 CST 2013 mZxid = 0x100000007 mtime = Mon Aug 12 05:34:32 CST 2013 pZxid = 0x100000006 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0 #get,再查看/node的数据信息,已改为fens.me [zk: 192.168.1.201(CONNECTED) 6] get /node fens.me cZxid = 0x100000006 ctime = Mon Aug 12 05:32:49 CST 2013 mZxid = 0x100000007 mtime = Mon Aug 12 05:34:32 CST 2013 pZxid = 0x100000006 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 0 #delete,删除/node [zk: 192.168.1.201(CONNECTED) 7] delete /node [zk: 192.168.1.201(CONNECTED) 8] ls / [zookeeper] #quit,退出客户端连接 [zk: 192.168.1.201(CONNECTED) 19] quit Quitting... 2013-08-12 05:40:29,304 [myid:] - INFO [main:ZooKeeper@684] - Session: 0x1406f3c1ef90002 closed 2013-08-12 05:40:29,305 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@509] - EventThread shut down
5. Java编程现实命令行操作
package org.conan.zookeeper.demo;
import java.io.IOException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
public class BasicDemo1 {
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
// 创建一个与服务器的连接
ZooKeeper zk = new ZooKeeper("192.168.1.201:2181", 60000, new Watcher() {
// 监控所有被触发的事件
public void process(WatchedEvent event) {
System.out.println("EVENT:" + event.getType());
}
});
// 查看根节点
System.out.println("ls / => " + zk.getChildren("/", true));
// 创建一个目录节点
if (zk.exists("/node", true) == null) {
zk.create("/node", "conan".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node conan");
// 查看/node节点数据
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
// 查看根节点
System.out.println("ls / => " + zk.getChildren("/", true));
}
// 创建一个子目录节点
if (zk.exists("/node/sub1", true) == null) {
zk.create("/node/sub1", "sub1".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("create /node/sub1 sub1");
// 查看node节点
System.out.println("ls /node => " + zk.getChildren("/node", true));
}
// 修改节点数据
if (zk.exists("/node", true) != null) {
zk.setData("/node", "changed".getBytes(), -1);
// 查看/node节点数据
System.out.println("get /node => " + new String(zk.getData("/node", false, null)));
}
// 删除节点
if (zk.exists("/node/sub1", true) != null) {
zk.delete("/node/sub1", -1);
zk.delete("/node", -1);
// 查看根节点
System.out.println("ls / => " + zk.getChildren("/", true));
}
// 关闭连接
zk.close();
}
}运行结果:
2013-08-12 15:33:29,699 [myid:] - INFO [main:Environment@97] - Client environment:zookeeper.version=3.3.1-942149, built on 05/07/2010 17:14 GMT 2013-08-12 15:33:29,702 [myid:] - INFO [main:Environment@97] - Client environment:host.name=PC201304202140 2013-08-12 15:33:29,702 [myid:] - INFO [main:Environment@97] - Client environment:java.version=1.6.0_45 2013-08-12 15:33:29,702 [myid:] - INFO [main:Environment@97] - Client environment:java.vendor=Sun Microsystems Inc. 2013-08-12 15:33:29,702 [myid:] - INFO [main:Environment@97] - Client environment:java.home=D:\toolkit\java\jdk6\jre 2013-08-12 15:33:29,703 [myid:] - INFO [main:Environment@97] - Client environment:java.class.path=D:\workspace\java\zkdemo\target\classes;C:\Users\Administrator\.m2\repository\org\apache\hadoop\zookeeper\3.3.1\zookeeper-3.3.1.jar;C:\Users\Administrator\.m2\repository\log4j\log4j\1.2.15\log4j-1.2.15.jar;C:\Users\Administrator\.m2\repository\javax\mail\mail\1.4\mail-1.4.jar;C:\Users\Administrator\.m2\repository\javax\activation\activation\1.1\activation-1.1.jar;C:\Users\Administrator\.m2\repository\jline\jline\0.9.94\jline-0.9.94.jar;C:\Users\Administrator\.m2\repository\junit\junit\3.8.1\junit-3.8.1.jar 2013-08-12 15:33:29,703 [myid:] - INFO [main:Environment@97] - Client environment:java.library.path=D:\toolkit\java\jdk6\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;D:\toolkit\Rtools\bin;D:\toolkit\Rtools\gcc-4.6.3\bin;C:\Program Files (x86)\Common Files\NetSarang;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;D:\toolkit\Git\cmd;D:\toolkit\Git\bin;C:\Program Files (x86)\Microsoft SQL Server\100\Tools\Binn\;C:\Program Files\Microsoft SQL Server\100\Tools\Binn\;C:\Program Files\Microsoft SQL Server\100\DTS\Binn\;c:\Program Files (x86)\Common Files\Ulead Systems\MPEG;C:\Program Files (x86)\QuickTime\QTSystem\;D:\toolkit\MiKTex\miktex\bin\x64\;D:\toolkit\sshclient;D:\toolkit\ant19\bin;D:\toolkit\eclipse;D:\toolkit\gradle15\bin;D:\toolkit\java\jdk6\bin;D:\toolkit\maven3\bin;D:\toolkit\mysql56\bin;D:\toolkit\python27;D:\toolkit\putty;C:\Program Files\R\R-3.0.1\bin\x64;D:\toolkit\mongodb243\bin;D:\toolkit\php54;D:\toolkit\nginx140;D:\toolkit\nodejs;D:\toolkit\npm12\bin;D:\toolkit\java\jdk6\jre\bin\server;. 2013-08-12 15:33:29,703 [myid:] - INFO [main:Environment@97] - Client environment:java.io.tmpdir=C:\Users\ADMINI~1\AppData\Local\Temp\ 2013-08-12 15:33:29,704 [myid:] - INFO [main:Environment@97] - Client environment:java.compiler= 2013-08-12 15:33:29,704 [myid:] - INFO [main:Environment@97] - Client environment:os.name=Windows 7 2013-08-12 15:33:29,704 [myid:] - INFO [main:Environment@97] - Client environment:os.arch=amd64 2013-08-12 15:33:29,705 [myid:] - INFO [main:Environment@97] - Client environment:os.version=6.1 2013-08-12 15:33:29,705 [myid:] - INFO [main:Environment@97] - Client environment:user.name=Administrator 2013-08-12 15:33:29,705 [myid:] - INFO [main:Environment@97] - Client environment:user.home=C:\Users\Administrator 2013-08-12 15:33:29,706 [myid:] - INFO [main:Environment@97] - Client environment:user.dir=D:\workspace\java\zkdemo 2013-08-12 15:33:29,707 [myid:] - INFO [main:ZooKeeper@373] - Initiating client connection, connectString=192.168.1.201:2181 sessionTimeout=60000 watcher=org.conan.zookeeper.demo.BasicDemo1$1@3dfeca64 2013-08-12 15:33:29,731 [myid:] - INFO [main-SendThread():ClientCnxn$SendThread@1000] - Opening socket connection to server /192.168.1.201:2181 2013-08-12 15:33:38,736 [myid:] - INFO [main-SendThread(192.168.1.201:2181):ClientCnxn$SendThread@908] - Socket connection established to 192.168.1.201/192.168.1.201:2181, initiating session 2013-08-12 15:33:38,804 [myid:] - INFO [main-SendThread(192.168.1.201:2181):ClientCnxn$SendThread@701] - Session establishment complete on server 192.168.1.201/192.168.1.201:2181, sessionid = 0x1406f3c1ef9000d, negotiated timeout = 60000 EVENT:None ls / => [zookeeper] EVENT:NodeCreated EVENT:NodeChildrenChanged create /node conan get /node => conan ls / => [node, zookeeper] EVENT:NodeCreated create /node/sub1 sub1 ls /node => [sub1] EVENT:NodeDataChanged get /node => changed EVENT:NodeDeleted EVENT:NodeChildrenChanged EVENT:NodeChildrenChanged ls / => [zookeeper] 2013-08-12 15:33:38,877 [myid:] - INFO [main:ZooKeeper@538] - Session: 0x1406f3c1ef9000d closed
pom.xml,maven配置文件
<?xml version="1.0" encoding="UTF-8"?> <project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <modelVersion>4.0.0</modelVersion> <groupId>org.conan.zookeeper</groupId> <artifactId>zkdemo</artifactId> <version>0.0.1</version> <name>zkdemo</name> <description>zkdemo</description> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>zookeeper</artifactId> <version>3.3.1</version> <exclusions> <exclusion> <groupId>javax.jms</groupId> <artifactId>jms</artifactId> </exclusion> <exclusion> <groupId>com.sun.jdmk</groupId> <artifactId>jmxtools</artifactId> </exclusion> <exclusion> <groupId>com.sun.jmx</groupId> <artifactId>jmxri</artifactId> </exclusion> </exclusions> </dependency> </dependencies> </project>
基础讲完,接下来就让我动手管理起,我们自己的分布式系统吧。
转载请注明出处:
http://blog.fens.me/hadoop-zookeeper-intro/
Posted:
Jul 30, 2013
Tags:
HadoophiveITIT技术玩金融RRHive逆回购金融
Comments:
11
Comments
用RHive从历史数据中提取逆回购信息
用IT技术玩金融系列文章,将介绍如何使用IT技术,处理金融大数据。在互联网混迹多年,已经熟练掌握一些IT技术。单纯地在互联网做开发,总觉得使劲的方式不对。要想靠技术养活自己,就要把技术变现。通过“跨界”可以寻找新的机会,创造技术的壁垒。金融是离钱最近的市场,也是变现的好渠道!今天就开始踏上“用IT技术玩金融”之旅!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/finance-rhive-repurchase/
前言
接触金融时间并不太长,对我来说第一个操作的业务,就是逆回购。逆回购对于大部分人来说,都是一个新鲜词,就算是炒股多年的玩家,可能也是在2013年6月份发生银行缺钱的事件之后才了解的。隔夜的银行间拆借利率达到了30%,简单来说银行缺钱了!各种机构 分分出售股票,债券,兑换成现金借给应银行。个人用户也都取出存款,通过逆回购,把钱借给银行。30%的利率,让所有人在那一周都为之兴奋,只有银行在惶恐。
目录
逆回购简介
历史数据模型
通过用RHive提取数据
简单策略实现
1. 逆回购简介
债券回购的含义债券质押式回购简单地说就是交易双方以债券为质押品的一种短期资金借贷行为。其中债券持有人(正回购方)将债券质押而获得资金使用权,到约定的时间还本并支付一定的利息,从而“赎回”债券。而资金持有人(逆回购方)就是正回购方的交易对手。在实际交易中债券是质押给了第三方即中国结算公司,这样交易双方否更加安全、便捷。
可回购的债券
所有的国债、绝大部分企业债、公司债和分离债的纯债都可用于债券回购交易。沪深交易所每周都会公布可回购债券的折算率,上面没有但可交易的品种就是不可回购的债券。折算率简单说,就是把债券质押时,交易所按债券面值给出的可质押的比率。
现在交易的回购品种
我们仅列出个人投资者经常参与的公司债(包括企业债等)回购品种。
上海证券交易所可交易的质押式回购(括弧中为交易代码)分为1日(204001)、2日(204002)、3日(204003)、4日(204004)、7日(204007)、14日(204014)、28日(204028)、91日(204091)、182日(204182)共9个品种。深圳交易所按回购期限分为分为1日(131810)、2日(131811)、3日(131800)、7日(131801)共4个品种。其中经常交易的只有沪深1日和7日四个品种,并且沪市的日均交易量又远远大于深市的交易量。
以上逆回购定义摘自:http://finance.sina.com.cn/money/bond/20121016/180713385513.shtml
2. 历史数据模型
Hive中的表结构:rhive.desc.table('t_reverse_repurchase')
col_name data_type
1 tradedate string
2 tradetime string
3 securityid string
4 bidpx1 double
5 bidsize1 double
6 offerpx1 double
7 offersize1 doubletradedate:交易日期
tradetime:交易时间
securityid:股票ID
bidpx1:买一
bidsize1:买一交易量
offerpx1:卖一
bidsize1:卖一交易量
3. 通过用RHive提取数据
登陆c1服务器,打开R的客户端。#装载RHive
library(RHive)
#初始化
rhive.init()
#连接到Hive集群
> rhive.connect("c1.wtmart.com")
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/cos/toolkit/hive-0.9.0/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/cos/toolkit/hadoop-1.0.3/lib/slf4j-log4j12-1.4.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
#查看当前的表
> rhive.list.tables()
tab_name
1 t_hft_day //历史数据表
2 t_hft_tmp //临时表
4 t_reverse_repurchase //逆回购表查看所有股票历史数据分片:测试数据从20130627–20130726。
> rhive.query("SHOW PARTITIONS t_hft_day");
partition
1 tradedate=20130627
2 tradedate=20130628
3 tradedate=20130701
4 tradedate=20130702
5 tradedate=20130703
6 tradedate=20130704
7 tradedate=20130705
8 tradedate=20130708
9 tradedate=20130709
10 tradedate=20130710
11 tradedate=20130712
12 tradedate=20130715
13 tradedate=20130716
14 tradedate=20130719
15 tradedate=20130722
16 tradedate=20130723
17 tradedate=20130724
18 tradedate=20130725
19 tradedate=20130726分为提取”上交所一天逆回购”(204001),和”深交所一天逆回购”(131810),从7月22日至7月26日的一周数据。
> rhive.drop.table("t_reverse_repurchase")
> rhive.query("CREATE TABLE t_reverse_repurchase AS SELECT tradedate,tradetime,securityid,bidpx1,bidsize1,offerpx1,offersize1 FROM t_hft_day where tradedate>=20130722 and tradedate<=20130726 and securityid in (131810,204001)");查看数据结果集
> rhive.query("SELECT securityid,count(1) FROM t_reverse_repurchase group by securityid");
securityid X_c1
1 131810 17061
2 204001 12441加载到R的内存中。
> bidpx1<-rhive.query("SELECT securityid,concat(tradedate,tradetime) as tradetime,bidpx1 FROM t_reverse_repurchase");
#查看记录条数
> nrow(bidpx1)
[1] 29502
#查看数据
> head(bidpx1)
securityid tradetime bidpx1
1 131810 20130724145004 2.620
2 131810 20130724145101 2.860
3 131810 20130724145128 2.850
4 131810 20130724145143 2.603
5 131810 20130724144831 2.890
6 131810 20130724145222 2.600用ggplot2做数据可视化
一周数据的走势
library(ggplot2)
g<-ggplot(data=bidpx1, aes(x=as.POSIXct(tradetime,format="%Y%m%d%H%M%S"), y=bidpx1))
g<-g+geom_line(aes(group=securityid,colour=securityid))
g<-g+xlab('tradetime')+ylab('bidpx1')
ggsave(g,file="01.png",width=12,height=8)一天数据的走势
bidpx1<-rhive.query("SELECT securityid,concat(tradedate,tradetime) as tradetime,bidpx1 FROM t_reverse_repurchase WHERE tradedate=20130726");
g<-ggplot(data=bidpx1, aes(x=as.POSIXct(tradetime,format="%Y%m%d%H%M%S"), y=bidpx1))
g<-g+geom_line(aes(group=securityid,colour=securityid))
g<-g+xlab('tradetime')+ylab('bidpx1')
ggsave(g,file="02.png",width=12,height=8)4. 简单策略实现
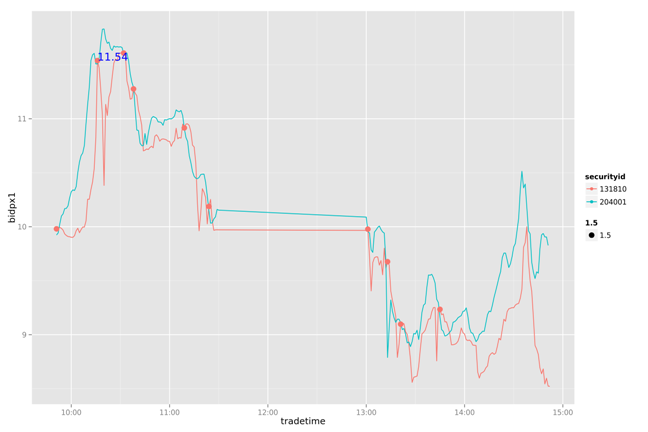
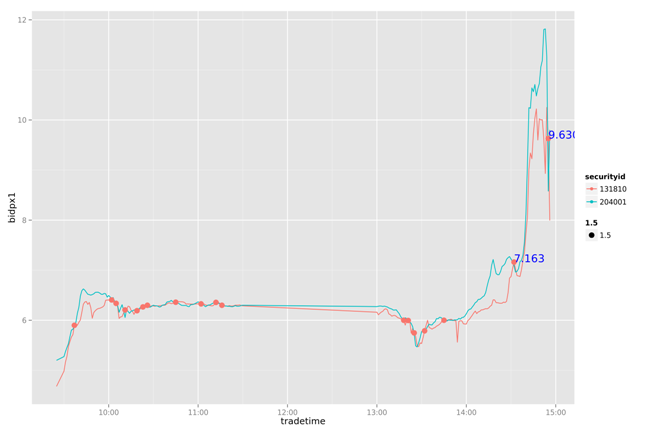
通过简单的打印出两幅图片的两条曲线,我们可以看到131810一直在追随204001变化,并且大部情况都低于204001。下面做一个简单的策略分析:通过204001变化,判断131810的卖点。
把131810和204001按每分钟标准化
设置当131810和204001有交点的时候,提取卖出信号
当后一个交点的卖一价格大于前一个交点的卖一价格10%以上,做为局部最优的卖出信号点
提取131810,204001的数据,存储在t_reverse_repurchase表中
#登陆R
library(RHive)
rhive.init()
rhive.connect("c1.wtmart.com")
#提取131810,204001的数据
rhive.drop.table("t_reverse_repurchase")
rhive.query("CREATE TABLE t_reverse_repurchase AS SELECT tradedate,tradetime,securityid,bidpx1,bidsize1,offerpx1,offersize1 FROM t_hft_day where securityid in (131810,204001)");
#查看数据集
rhive.query("select count(1),tradedate from t_reverse_repurchase group by tradedate")
X_c0 tradedate
1 4840 20130627
2 4792 20130628
3 4677 20130701
4 3124 20130702
5 2328 20130703
6 3787 20130704
7 4294 20130705
8 4977 20130708
9 4568 20130709
10 6619 20130710
11 5633 20130712
12 6159 20130715
13 5918 20130716
14 6200 20130719
15 6074 20130722
16 5991 20130723
17 5899 20130724
18 5346 20130725
19 6192 20130726加载软件包
library(ggplot2) library(scales) library(plyr)
获得一天的数据并做ETL
#把一周的数据加载到内存
bidpx1<-rhive.query(paste("SELECT securityid,tradedate,tradetime,bidpx1 FROM t_reverse_repurchase WHERE tradedate>=20130722"));
#加载一天的数据并做ETL
oneDay<-function(date){
d1<-bidpx1[which(bidpx1$tradedate==date),]
d1$tradetime2<-round( as.numeric(as.character(d1$tradetime))/100)*100
d1$tradetime2[which(d1$tradetime2<100000)]<-paste(0,d1$tradetime2[which(d1$tradetime2<100000)],sep="")
d1$tradetime2[which(d1$tradetime2=='1e+05')]='100000'
d1$tradetime2[which(d1$tradetime2=='096000')]='100000'
d1$tradetime2[which(d1$tradetime2=='106000')]='110000'
d1$tradetime2[which(d1$tradetime2=='126000')]='130000'
d1$tradetime2[which(d1$tradetime2=='136000')]='140000'
d1$tradetime2[which(d1$tradetime2=='146000')]='150000'
d1
}
#通过均值标准化
meanScale<-function(d1){
ddply(d1, .(securityid,tradetime2), summarize, bidpx1=mean(bidpx1))
}
#找到要分析的点
findPoint<-function(a1,a2){
#找到所有a1大于a2的点
bigger_point<-function(a1,a2){
idx<-c()
for(i in intersect(a1$tradetime2,a2$tradetime2)){
i1<-which(a1$tradetime2==i)
i2<-which(a2$tradetime2==i)
if(a1$bidpx1[i1]-a2$bidpx1[i2]>=-0.02){
idx<-c(idx,i1)
}
}
idx
}
#去掉连续的索引值
remove_continuous_point<-function(idx){
idx[-which(idx-c(NA,rev(rev(idx)[-1]))==1)]
}
idx<-bigger_point(a1,a2)
remove_continuous_point(idx)
}
#发现局部最优卖出点
findOptimize<-function(d3){
idx2<-which((d3$bidpx1-c(NA,rev(rev(d3$bidpx1)[-1])))/d3$bidpx1>0.1)
if(length(idx2)<1)
print("No Optimize point")
d3[idx2,]
}
#画图查看结果
draw<-function(d2,d3,d4,date,png=FALSE){
g<-ggplot(data=d2, aes(x=strptime(paste(date,tradetime2,sep=""),format="%Y%m%d%H%M%S"), y=bidpx1))
g<-g+geom_line(aes(group=securityid,colour=securityid))
g<-g+geom_point(data=d3,aes(size=1.5,colour=securityid)) if(nrow(d4)>0){
g<-g+geom_text(data=d4,aes(label= format(d4$bidpx1,digits=4)),colour="blue",hjust=0, vjust=0)
}
g<-g+xlab('tradetime')+ylab('bidpx1')
if(png){
ggsave(g,file=paste(date,".png",sep=""),width=12,height=8)
}else{
g
}
}
#执行策略封装
date<-20130722
d1<-oneDay(date)
d2<-meanScale(d1)
a1<-d2[which(d2$securityid==131810),]
a2<-d2[which(d2$securityid==204001),]
d3<-d2[findPoint(a1,a2),]
d4<-findOptimize(d3)
draw(d2,d3,d4,as.character(date),TRUE)20130722
20130723
20130724
20130725
20130726
通过对一周数据的比较我们发现,这个简单的策略能我们带来一些收益。虽然不是全局最优的,但比人为的判断会更有依据。
用IT技术玩金融系列文章,第一篇就当是一个抛砖引玉的开始,后面的文章会更精彩。
######################################################
看文字不过瘾,作者视频讲解,请访问网站:http://onbook.me/video
######################################################
转载请注明出处:
http://blog.fens.me/finance-rhive-repurchase/
Posted:
Jul 27, 2013
Tags:
HadoophivelinuxRRHivesql
Comments:
4
Comments
R利剑NoSQL系列文章 之 Hive
R利剑NoSQL系列文章,主要介绍通过R语言连接使用nosql数据库。涉及的NoSQL产品,包括Redis,MongoDB, HBase, Hive, Cassandra, Neo4j。希望通过我的介绍让广大的R语言爱好者,有更多的开发选择,做出更多地激动人心的应用。关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明:
http://blog.fens.me/nosql-r-hive/
第四篇 R利剑Hive,分为5个章节。
Hive介绍
Hive安装
RHive安装
RHive函数库
RHive基本使用操作
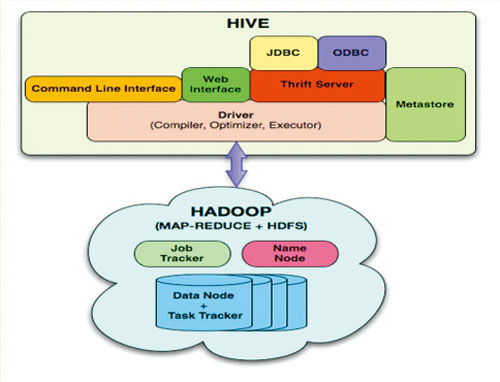
1. Hive介绍
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式
上面内容摘自 百度百科(http://baike.baidu.com/view/699292.htm)
hive与关系数据库的区别:
数据存储不同:hive基于hadoop的HDFS,关系数据库则基于本地文件系统
计算模型不同:hive基于hadoop的mapreduce,关系数据库则基于索引的内存计算模型
应用场景不同:hive是OLAP数据仓库系统提供海量数据查询的,实时性很差;关系数据库是OLTP事务系统,为实时查询业务服务
扩展性不同:hive基于hadoop很容易通过分布式增加存储能力和计算能力,关系数据库水平扩展很难,要不断增加单机的性能
2. Hive安装
Hive是基于Hadoop开发的数据仓库产品,所以首先我们要先有Hadoop的环境。Hadoop安装,请参考:Hadoop环境搭建, 创建Hadoop母体虚拟机
Hive的安装,请参考:Hive安装及使用攻略
Hadoop-1.0.3的下载地址
http://archive.apache.org/dist/hadoop/core/hadoop-1.0.3/ Hive-0.9.0的下载地址
http://archive.apache.org/dist/hive/hive-0.9.0/ Hive安装好后
启动hiveserver的服务
~ nohup hive --service hiveserver & Starting Hive Thrift Server
打开hive shell
~ hive shell Logging initialized using configuration in file:/home/conan/hadoop/hive-0.9.0/conf/hive-log4j.proper ties Hive history file=/tmp/conan/hive_job_log_conan_201306261459_153868095.txt #查看hive的表 hive> show tables; hive_algo_t_account o_account r_t_account Time taken: 2.12 seconds #查看o_account表的数据 hive> select * from o_account; 1 abc@163.com 2013-04-22 12:21:39 2 dedac@163.com 2013-04-22 12:21:39 3 qq8fed@163.com 2013-04-22 12:21:39 4 qw1@163.com 2013-04-22 12:21:39 5 af3d@163.com 2013-04-22 12:21:39 6 ab34@163.com 2013-04-22 12:21:39 7 q8d1@gmail.com 2013-04-23 09:21:24 8 conan@gmail.com 2013-04-23 09:21:24 9 adeg@sohu.com 2013-04-23 09:21:24 10 ade121@sohu.com 2013-04-23 09:21:24 11 addde@sohu.com 2013-04-23 09:21:24 Time taken: 0.469 seconds
3. RHive安装
请提前配置好JAVA的环境:~ java -version java version "1.6.0_29" Java(TM) SE Runtime Environment (build 1.6.0_29-b11) Java HotSpot(TM) 64-Bit Server VM (build 20.4-b02, mixed mode)
安装R:Ubuntu 12.04,请更新源再下载R2.15.3版本
~ sudo sh -c "echo deb http://mirror.bjtu.edu.cn/cran/bin/linux/ubuntu precise/ >>/etc/apt/sources.list" ~ sudo apt-get update ~ sudo apt-get install r-base-core=2.15.3-1precise0precise1
安装R依赖库:rjava
#配置rJava
~ sudo R CMD javareconf
#启动R程序
~ sudo R
install.packages("rJava")安装RHive
install.packages("RHive")
library(RHive)
Loading required package: rJava
Loading required package: Rserve
This is RHive 0.0-7. For overview type ‘?RHive’.
HIVE_HOME=/home/conan/hadoop/hive-0.9.0
call rhive.init() because HIVE_HOME is set.4. RHive函数库
rhive.aggregate rhive.connect rhive.hdfs.exists rhive.mapapply rhive.assign rhive.desc.table rhive.hdfs.get rhive.mrapply rhive.basic.by rhive.drop.table rhive.hdfs.info rhive.napply rhive.basic.cut rhive.env rhive.hdfs.ls rhive.query rhive.basic.cut2 rhive.exist.table rhive.hdfs.mkdirs rhive.reduceapply rhive.basic.merge rhive.export rhive.hdfs.put rhive.rm rhive.basic.mode rhive.exportAll rhive.hdfs.rename rhive.sapply rhive.basic.range rhive.hdfs.cat rhive.hdfs.rm rhive.save rhive.basic.scale rhive.hdfs.chgrp rhive.hdfs.tail rhive.script.export rhive.basic.t.test rhive.hdfs.chmod rhive.init rhive.script.unexport rhive.basic.xtabs rhive.hdfs.chown rhive.list.tables rhive.size.table rhive.big.query rhive.hdfs.close rhive.load rhive.write.table rhive.block.sample rhive.hdfs.connect rhive.load.table rhive.close rhive.hdfs.du rhive.load.table2
Hive和RHive的基本操作对比:
#连接到hive
Hive: hive shell
RHive: rhive.connect("192.168.1.210")
#列出所有hive的表
Hive: show tables;
RHive: rhive.list.tables()
#查看表结构
Hive: desc o_account;
RHive: rhive.desc.table('o_account'), rhive.desc.table('o_account',TRUE)
#执行HQL查询
Hive: select * from o_account;
RHive: rhive.query('select * from o_account')
#查看hdfs目录
Hive: dfs -ls /;
RHive: rhive.hdfs.ls()
#查看hdfs文件内容
Hive: dfs -cat /user/hive/warehouse/o_account/part-m-00000;
RHive: rhive.hdfs.cat('/user/hive/warehouse/o_account/part-m-00000')
#断开连接
Hive: quit;
RHive: rhive.close()5. RHive基本使用操作
#初始化
rhive.init()
#连接hive
rhive.connect("192.168.1.210")
#查看所有表
rhive.list.tables()
tab_name
1 hive_algo_t_account
2 o_account
3 r_t_account
#查看表结构
rhive.desc.table('o_account');
col_name data_type comment
1 id int
2 email string
3 create_date string
#执行HQL查询
rhive.query("select * from o_account");
id email create_date
1 1 abc@163.com 2013-04-22 12:21:39
2 2 dedac@163.com 2013-04-22 12:21:39
3 3 qq8fed@163.com 2013-04-22 12:21:39
4 4 qw1@163.com 2013-04-22 12:21:39
5 5 af3d@163.com 2013-04-22 12:21:39
6 6 ab34@163.com 2013-04-22 12:21:39
7 7 q8d1@gmail.com 2013-04-23 09:21:24
8 8 conan@gmail.com 2013-04-23 09:21:24
9 9 adeg@sohu.com 2013-04-23 09:21:24
10 10 ade121@sohu.com 2013-04-23 09:21:24
11 11 addde@sohu.com 2013-04-23 09:21:24
#关闭连接
rhive.close()
[1] TRUE创建临时表
rhive.block.sample('o_account', subset="id<5")
[1] "rhive_sblk_1372238856"
rhive.query("select * from rhive_sblk_1372238856");
id email create_date
1 1 abc@163.com 2013-04-22 12:21:39
2 2 dedac@163.com 2013-04-22 12:21:39
3 3 qq8fed@163.com 2013-04-22 12:21:39
4 4 qw1@163.com 2013-04-22 12:21:39
#查看hdfs的文件
rhive.hdfs.ls('/user/hive/warehouse/rhive_sblk_1372238856/')
permission owner group length modify-time
1 rw-r--r-- conan supergroup 141 2013-06-26 17:28
file
1 /user/hive/warehouse/rhive_sblk_1372238856/000000_0
rhive.hdfs.cat('/user/hive/warehouse/rhive_sblk_1372238856/000000_0')
1abc@163.com2013-04-22 12:21:39
2dedac@163.com2013-04-22 12:21:39
3qq8fed@163.com2013-04-22 12:21:39
4qw1@163.com2013-04-22 12:21:39按范围分割字段数据
rhive.basic.cut('o_account','id',breaks='0:100:3')
[1] "rhive_result_20130626173626"
attr(,"result:size")
[1] 443
rhive.query("select * from rhive_result_20130626173626");
email create_date id
1 abc@163.com 2013-04-22 12:21:39 (0,3]
2 dedac@163.com 2013-04-22 12:21:39 (0,3]
3 qq8fed@163.com 2013-04-22 12:21:39 (0,3]
4 qw1@163.com 2013-04-22 12:21:39 (3,6]
5 af3d@163.com 2013-04-22 12:21:39 (3,6]
6 ab34@163.com 2013-04-22 12:21:39 (3,6]
7 q8d1@gmail.com 2013-04-23 09:21:24 (6,9]
8 conan@gmail.com 2013-04-23 09:21:24 (6,9]
9 adeg@sohu.com 2013-04-23 09:21:24 (6,9]
10 ade121@sohu.com 2013-04-23 09:21:24 (9,12]
11 addde@sohu.com 2013-04-23 09:21:24 (9,12]Hive操作HDFS
#查看hdfs文件目录
rhive.hdfs.ls()
permission owner group length modify-time file
1 rwxr-xr-x conan supergroup 0 2013-04-24 01:52 /hbase
2 rwxr-xr-x conan supergroup 0 2013-06-23 10:59 /home
3 rwxr-xr-x conan supergroup 0 2013-06-26 11:18 /rhive
4 rwxr-xr-x conan supergroup 0 2013-06-23 13:27 /tmp
5 rwxr-xr-x conan supergroup 0 2013-04-24 19:28 /user
#查看hdfs文件内容
rhive.hdfs.cat('/user/hive/warehouse/o_account/part-m-00000')
1abc@163.com2013-04-22 12:21:39
2dedac@163.com2013-04-22 12:21:39
3qq8fed@163.com2013-04-22 12:21:39转载请注明:
http://blog.fens.me/nosql-r-hive/

相关文章推荐