python 2.x和3.x中的字符串区别
2014-12-23 15:18
483 查看
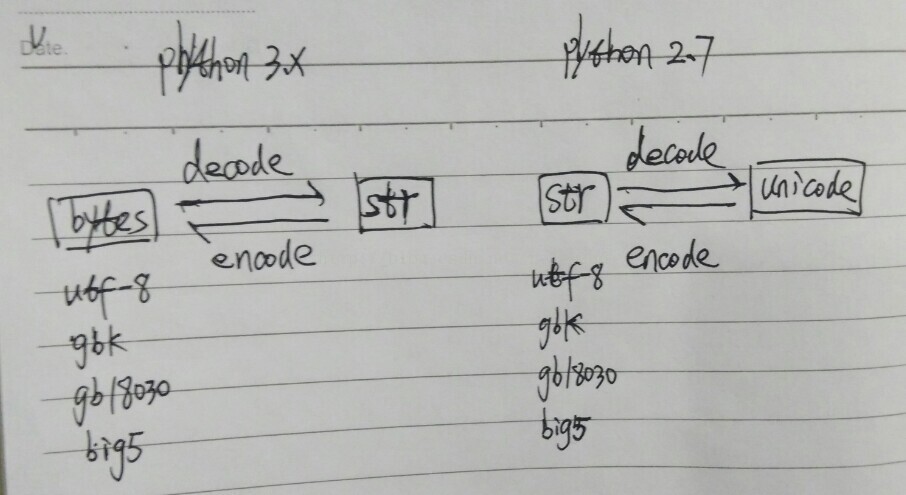
如图2.x和3.x的区别:
2.x中字符串有str和unicode两种类型,str有各种编码区别,unicode是没有编码的标准形式。unicode通过编码转化成str,str通过解码转化成unicode。
3.x中将字符串和字节序列做了区别,字符串str是字符串标准形式与2.x中unicode类似,bytes类似2.x中的str有各种编码区别。bytes通过解码转化成str,str通过编码转化成bytes。。
2.x中可以查看unicode字节序列,3.x中不能。。。
2.x示例:
>>> ss = '北京市'
>>> type(ss)
<type 'str'>
>>> us = ss.decode('gbk')
>>> us
u'\u5317\u4eac\u5e02'
>>> type(us)
<type 'unicode'>
>>> nus = u'北京市'
>>> nus
u'\u5317\u4eac\u5e02'
>>> ss
'\xb1\xb1\xbe\xa9\xca\xd0'
>>> gbks = nus.encode('gbk')
>>> gbks
'\xb1\xb1\xbe\xa9\xca\xd0'
>>> print(gbks)
北京市
>>> utfs = nus.encode('utf-8')
>>> utfs
'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82'
>>> print(utfs)
鍖椾含甯
>>> xx = utfs.decode('utf-8')
>>> type(xx)
<type 'unicode'>
ss = '北京市' 采用终端默认的编码形式,windows命名行窗口默认是gbk编码,所以通过ss.decode('gbk')转化成unicode的序列。最后utf-8编码的utfs输出乱码也是因为cmd终端是gdk编码的。
该示例中可以看到“北京市”的三种编码序列:
unicode序列:u'\u5317\u4eac\u5e02'
gbk序列:'\xb1\xb1\xbe\xa9\xca\xd0'
utf-8序列:'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82'
3.x示例:
Python 3.4.1 (v3.4.1:c0e311e010fc, May 18 2014, 10:38:22) [MSC v.1600 32 bit (In
tel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> ss = '北京市'
>>> type(ss)
<class 'str'>
>>> us = ss.encode('gbk')
>>> type(us)
<class 'bytes'>
>>> us
b'\xb1\xb1\xbe\xa9\xca\xd0'
>>> utfs = ss.encode('utf-8')
>>> print(utfs)
b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82'
>>> type(utfs)
<class 'bytes'>
>>> xx = utfs.decode('utf-8')
>>> type(xx)
<class 'str'>
>>> print(xx)
北京市
>>> import urllib.parse
>>> res = urllib.parse.quote(utfs)
>>> res
'%E5%8C%97%E4%BA%AC%E5%B8%82'3.x 想要查看字符串各种编码序列,只能通过encode转化成bytes类型,然后输出。str是标准形式没办法直接查看其字节序列。。
通过urllib.parse.quote 将字节序列转化成url的中文编码形式,逆过程是unquote函数。

相关文章推荐
- python3.x 与 python2.x的区别
- python 2.x 3.x input函数的区别
- Python2.x与3.x版本区别
- python3.x和python2.x区别
- Python3.x与2.x的区别(记录下,以备自己忘了)
- python中2.x和3.x的区别
- python 3.x和2.x区别
- python2.x和3.x的区别
- Python3.x 和Python2.x 区别
- python异常处理(二)--------python3.x与python2.x异常处理的联系和区别
- 总结Python2(Python 2.x版本)和Python3(Python 3.x版本)之间的区别
- Python 3.X与2.X语法上有哪些区别的东西?
- Python2.x与3.x版本区别
- python3.4学习笔记(四) 3.x和2.x的区别
- python 3.x 与 2.x区别
- Python-3.X和2.X版本的区别
- python2.x和python3.x区别
- python2.x里面的input()和raw_input()函数以及3.x中的input()函数的区别
- python2.x和python3.x中raw_input( )和input( )区别
- python 3.x和2.x的区别