MapReduce-过程介绍(求温度最大值)
2014-12-22 21:16
330 查看
Hadoop的内部工作机制: 分布式系统理论, 实际工程和常识于一体的系统.但是,Hadoop提供的用于构建分布式系统的工具–数据存储, 数据分析,和协调处理–都非常简单.每个阶段都以key/value对作为输入和输出, 类型由程序员选择.程序员需要定义两个函数: map函数和reduce函数.对于map阶段, 输入的是原始的NCDC(国家气候数据中心)数据, 键: 该行起始位置相对于文件起始位置的偏移量(因为数据实际上是一行, 没有分隔符的).设计map函数: 我们只对年份和气温这两个属性感兴趣, 只取出这两个. 在本例中, map函数只是一个数据准备阶段, 使reduce函数能在准备数据上继续处理.map函数还是一个比较适合去除已损记录的地方(筛选掉缺失的, 可疑的).map函数的输出发送到reduce函数, 处理过程是根据键对键/值对进行排序和分组.其逻辑过程可用如下图表示:代码如下: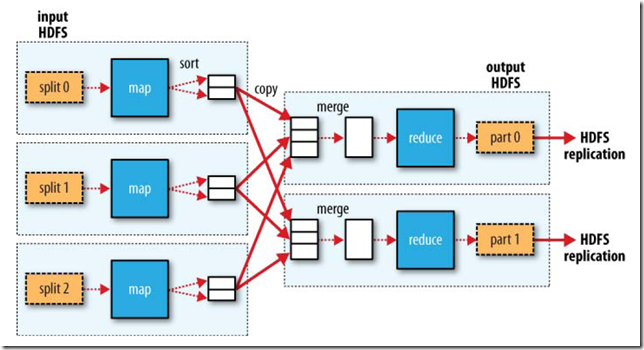 Map-Reduce的处理过程主要涉及以下四个部分:客户端Client:用于提交Map-reduce任务jobJobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTrackerTaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTrackerHDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件
Map-Reduce的处理过程主要涉及以下四个部分:客户端Client:用于提交Map-reduce任务jobJobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTrackerTaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTrackerHDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件 JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。向JobTracker请求一个新的job ID检测此job的output配置计算此job的input splits将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits通知JobTracker此Job已经可以运行了提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。初始化首先创建一个对象来封装job运行的tasks, status以及progress。在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。其为每个input split创建一个map task。每个task被分配一个ID。TaskTracker周期性的向JobTracker发送heartbeat。在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker将分配给其一个task。在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。TaskTracker有固定数量的位置来运行map task或者reduce task。默认的调度器对待map task优先于reduce task当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。TaskTracker被分配了一个task,下面便要运行此task。首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。其三,其创建一个TaskRunner来运行task。TaskRunner创建一个新的JVM来运行task。被创建的child JVM和TaskTracker通信来报告运行进度。
JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。向JobTracker请求一个新的job ID检测此job的output配置计算此job的input splits将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits通知JobTracker此Job已经可以运行了提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。初始化首先创建一个对象来封装job运行的tasks, status以及progress。在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。其为每个input split创建一个map task。每个task被分配一个ID。TaskTracker周期性的向JobTracker发送heartbeat。在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker将分配给其一个task。在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。TaskTracker有固定数量的位置来运行map task或者reduce task。默认的调度器对待map task优先于reduce task当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。TaskTracker被分配了一个task,下面便要运行此task。首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。其三,其创建一个TaskRunner来运行task。TaskRunner创建一个新的JVM来运行task。被创建的child JVM和TaskTracker通信来报告运行进度。
package temperature;
import java.io.IOException;
import java.io.IOException;
//是hadoop针对流处理优化的类型
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
//会继承这个基类
import org.apache.hadoop.mapred.MapReduceBase;
//会实现这个接口
import org.apache.hadoop.mapred.Mapper;
//处理后数据由它来收集
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class MaxTemperatureMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING=999;
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if( line.charAt(87) == '+') {// parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(89,92));
} else {
airTemperature = Integer.parseInt("-"+ line.substring(89,92));
}
// output.collect(new Text(year), new IntWritable(airTemperature));
// String quality = line.substring(92, 93);
if(airTemperature != MISSING) {
output.collect(new Text(year), new IntWritable(airTemperature));
}
}
}Mapper是一个泛型接口:Mapper<LongWritable, Text, Text, IntWritable>它有4个形参类型, 分别是map函数的输入键, 输入值, 输出键和输出值的类型.就目前来说, 输入键是长整数偏移量, 输入值是一行文本, 输出键是年份, 输出值是气温(整数).Hadoop提供了一套可优化网络序列化传输的基本类型, 不直接使用java内嵌的类型. 在这里,
LongWritable相当于
Long,
IntWritable相当于
Int,
Text相当于
String.
map()方法的输入是一个键和一个值.
map()还提供了
OutputCollector实例用于输出内容的写入.
package temperature;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class MaxTemperatureReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
}<p style="line-height: 19px; margin: 10px auto; color: rgb(75, 75, 75); font-family: Verdana, Geneva, Arial, Helvetica, sans-serif; font-size: 13px;">reduce函数的输入键值对必须与map函数的输出键值对匹配.</p><p style="line-height: 19px; margin: 10px auto; color: rgb(75, 75, 75); font-family: Verdana, Geneva, Arial, Helvetica, sans-serif; font-size: 13px;">reduce函数的输出键值对类型为Text/IntWritable, 分别表示年份和最高气温.</p>
package temperature;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.MapReduceBase;public class TemperatureClass { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } JobConf conf = new JobConf(TemperatureClass.class); conf.setJobName("Max temperature"); FileInputFormat.addInputPath(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setMapperClass(MaxTemperatureMapper.class); conf.setReducerClass(MaxTemperatureReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); } }JobConf,其有很多的项可以进行配置:setInputFormat:设置map的输入格式,默认为TextInputFormat,key为LongWritable, value为TextsetNumMapTasks:设置map任务的个数,此设置通常不起作用,map任务的个数取决于输入的数据所能分成的input split的个数setMapperClass:设置Mapper,默认为IdentityMappersetMapRunnerClass:设置MapRunner, map task是由MapRunner运行的,默认为MapRunnable,其功能为读取input split的一个个record,依次调用Mapper的map函数setMapOutputKeyClass和setMapOutputValueClass:设置Mapper的输出的key-value对的格式setOutputKeyClass和setOutputValueClass:设置Reducer的输出的key-value对的格式setPartitionerClass和setNumReduceTasks:设置Partitioner,默认为HashPartitioner,其根据key的hash值来决定进入哪个partition,每个partition被一个reduce task处理,所以partition的个数等于reduce task的个数setReducerClass:设置Reducer,默认为IdentityReducersetOutputFormat:设置任务的输出格式,默认为TextOutputFormatFileInputFormat.addInputPath:设置输入文件的路径,可以使一个文件,一个路径,一个通配符。可以被调用多次添加多个路径FileOutputFormat.setOutputPath:设置输出文件的路径,在job运行前此路径不应该存在JobConf 对象制定了作业的执行规范. 构造函数的参数为作业所在的类, Hadoop会通过该类来查找包含给类的JAR文件.构造 JobConf对象后, 制定输入和输出数据的路径. 这里是通过
FileInputFormat的静态方法
addInputPath()来定义输入数据的路径, 路径可以是单个文件, 也可以是目录(即目录下的所有文件)或符合特定模式的一组文件. 可以多次调用(从名称可以看出,
addInputPath()).同理,
FileOutputFormat.setOutputPath()指定输出路径. 即写入目录. 运行作业前, 写入目录不应该存在, Hadoop会拒绝并报错. 这样设计, 主要是防止数据被覆盖, 数据丢失. 毕竟Hadoop运行的时间是很长的, 丢失了非常恼人.
FileOutputFormat.setOutputPath()和
conf.setMapperClass()指定map和reduce类型.接着,
setOutputKeyClass和
setOutputValueClass指定map和reduce函数的 输出 类型, 这两个函数的输出类型往往相同. 如果不同, map的输出函数类型通过
setMapOutputKeyClass和
setMapOutputValueClass指定.输入的类型用
InputFormat设置, 本例中没有指定, 使用的是默认的
TextInputFormat(文本输入格式);最后,
JobClient.runJob()会提交作业并等待完成, 将结果写到控制台.程序运行时使用的配置信息:运行得到的结果如下(由于个人搭建的云计算平台过于简陋只是使用了两年的数据结果)下图大概描述了Map-Reduce的Job运行的基本原理:
 Map-Reduce的处理过程主要涉及以下四个部分:客户端Client:用于提交Map-reduce任务jobJobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTrackerTaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTrackerHDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件
Map-Reduce的处理过程主要涉及以下四个部分:客户端Client:用于提交Map-reduce任务jobJobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTrackerTaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTrackerHDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件 JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。向JobTracker请求一个新的job ID检测此job的output配置计算此job的input splits将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits通知JobTracker此Job已经可以运行了提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。初始化首先创建一个对象来封装job运行的tasks, status以及progress。在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。其为每个input split创建一个map task。每个task被分配一个ID。TaskTracker周期性的向JobTracker发送heartbeat。在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker将分配给其一个task。在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。TaskTracker有固定数量的位置来运行map task或者reduce task。默认的调度器对待map task优先于reduce task当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。TaskTracker被分配了一个task,下面便要运行此task。首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。其三,其创建一个TaskRunner来运行task。TaskRunner创建一个新的JVM来运行task。被创建的child JVM和TaskTracker通信来报告运行进度。
JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。向JobTracker请求一个新的job ID检测此job的output配置计算此job的input splits将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits通知JobTracker此Job已经可以运行了提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。初始化首先创建一个对象来封装job运行的tasks, status以及progress。在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。其为每个input split创建一个map task。每个task被分配一个ID。TaskTracker周期性的向JobTracker发送heartbeat。在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker将分配给其一个task。在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。TaskTracker有固定数量的位置来运行map task或者reduce task。默认的调度器对待map task优先于reduce task当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。TaskTracker被分配了一个task,下面便要运行此task。首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。其三,其创建一个TaskRunner来运行task。TaskRunner创建一个新的JVM来运行task。被创建的child JVM和TaskTracker通信来报告运行进度。Map的过程
MapRunnable从input split中读取一个个的record,然后依次调用Mapper的map函数,将结果输出。map的输出并不是直接写入硬盘,而是将其写入缓存memory buffer。当buffer中数据的到达一定的大小,一个背景线程将数据开始写入硬盘。在写入硬盘之前,内存中的数据通过partitioner分成多个partition。在同一个partition中,背景线程会将数据按照key在内存中排序。每次从内存向硬盘flush数据,都生成一个新的spill文件。当此task结束之前,所有的spill文件被合并为一个整的被partition的而且排好序的文件。reducer可以通过http协议请求map的输出文件,tracker.http.threads可以设置http服务线程数。Reduce的过程
当map task结束后,其通知TaskTracker,TaskTracker通知JobTracker。对于一个job,JobTracker知道TaskTracer和map输出的对应关系。reducer中一个线程周期性的向JobTracker请求map输出的位置,直到其取得了所有的map输出。reduce task需要其对应的partition的所有的map输出。reduce task中的copy过程即当每个map task结束的时候就开始拷贝输出,因为不同的map task完成时间不同。reduce task中有多个copy线程,可以并行拷贝map输出。当很多map输出拷贝到reduce task后,一个背景线程将其合并为一个大的排好序的文件。当所有的map输出都拷贝到reduce task后,进入sort过程,将所有的map输出合并为大的排好序的文件。最后进入reduce过程,调用reducer的reduce函数,处理排好序的输出的每个key,最后的结果写入HDFS。任务结束
当JobTracker获得最后一个task的运行成功的报告后,将job得状态改为成功。当JobClient从JobTracker轮询的时候,发现此job已经成功结束,则向用户打印消息,从runJob函数中返回。
相关文章推荐
- 面试过程中如何介绍自己?最大优缺点?加班?薪资?
- MapReduce:详细介绍Shuffle的执行过程
- MapReduce的执行过程介绍
- MapReduce:详细介绍Shuffle的执行过程
- MapReduce的Shuffle过程介绍
- MapReduce的Shuffle过程介绍
- MapReduce的Shuffle过程介绍
- MapReduce的Shuffle过程介绍
- MapReduce 过程简单介绍
- 《MapReduce:详细介绍Shuffle的执行过程》
- MapReduce:详细介绍Shuffle的执行过程
- MapReduce的Shuffle过程介绍
- 元过程建模以及一种元过程建模工具MetaEdit+的介绍
- SAP R/3 Workload交互过程介绍
- 存储过程语法介绍
- 介绍一个限制进程最大CPU占用的软件: ThreadMaster
- 储存过程介绍及c#中的应用1
- 介绍 Nutch 第一部分:抓取过程详解(翻译2)
- 简单介绍 ghost封装过程=-=-=-=带软件-=-=-=-=
- 存储过程语法介绍