轻量级日志收集技术方案
2014-11-28 00:00
211 查看
摘要: 为了实现数据分析,需要将生产服务器上的所有日志收集后进行大数据处理分析。日志收集的方案有很多,传统的做法有rsync和flume两种方式。这里我们使用消息队列的方式来收集数据,自行研发了一套日志收集服务,实现了日志收集的可扩展性、高容错性、安全性和灵活性。以下是各个技术方案的介绍和对比。

说明:
在生产环境上部署rsync传输脚本并设置定时,按天或按小时将日志传输到日志收集服务器
1) 优点
对生产服务器和日志收集服务器造成的压力较小
数据较精确,且可以比较方便的重复运行
2) 缺点
不能实时或者方便的得到想要的统计数据
不方便实施分布式
需要对每种日志正价同步脚本和设置定时,维护起来比较麻烦

说明:
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方。
采用了分层架构:分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
Flume使用两个组件:Master和Node,Node根据在Master shell或web中动态配置,决定其是作为Agent还是Collector。
1) 优点
Agent和Collector,Collector和Store之间有容错机制,且提供了三种级别的可靠性保证
方便分布式部署
直接支持HDFS
2) 缺点
日志收集前后处理不够灵活,不方便处理成各周期的汇总日志
部署比较重量级,适合于T级别数据量的处理
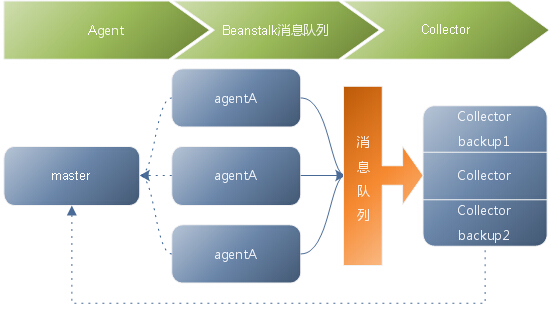
说明:
实线表示日志数据,虚线表示心跳和告警数据。
在生产服务器上增加agent数据监控服务,在日志收集服务器上部署beanstalkd队列服务,agent负责把生产服务器产生的日志实时写入到队列中去。
在日志收集服务器上部署Collector数据代理服务,负责将队列中的数据取出进行处理汇总。
Master和Collector可以部署在同一台服务器。
1) 优点
能够实时得到数据
使用php开发,日志收集前后处理灵活,可以根据需要编写php脚本进行个性化处理
统一使用master进行配置管理,非常方便进行部署,监控和维护
核心的agent,collector服务可以对其中的处理汇总进行分拆,易于分布式部署
2) 缺点
对系统的稳定性要求较高,如果agent异常退出,可能会丢失日志
对collector的性能要求较高,直接影响到日志收集服务器的负载
2) 直接传输至HDFS,进行离线大数据计算,主要对一些日期久远的日志及不需要实时计算的日志进行统计分析。
1. 传统架构
1.1. Rsync方式
说明:
在生产环境上部署rsync传输脚本并设置定时,按天或按小时将日志传输到日志收集服务器
1) 优点
对生产服务器和日志收集服务器造成的压力较小
数据较精确,且可以比较方便的重复运行
2) 缺点
不能实时或者方便的得到想要的统计数据
不方便实施分布式
需要对每种日志正价同步脚本和设置定时,维护起来比较麻烦
Flume方式
说明:
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方。
采用了分层架构:分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
Flume使用两个组件:Master和Node,Node根据在Master shell或web中动态配置,决定其是作为Agent还是Collector。
1) 优点
Agent和Collector,Collector和Store之间有容错机制,且提供了三种级别的可靠性保证
方便分布式部署
直接支持HDFS
2) 缺点
日志收集前后处理不够灵活,不方便处理成各周期的汇总日志
部署比较重量级,适合于T级别数据量的处理
2. 新轻量级架构
2.1. 消息队列方式
说明:
实线表示日志数据,虚线表示心跳和告警数据。
在生产服务器上增加agent数据监控服务,在日志收集服务器上部署beanstalkd队列服务,agent负责把生产服务器产生的日志实时写入到队列中去。
在日志收集服务器上部署Collector数据代理服务,负责将队列中的数据取出进行处理汇总。
Master和Collector可以部署在同一台服务器。
1) 优点
能够实时得到数据
使用php开发,日志收集前后处理灵活,可以根据需要编写php脚本进行个性化处理
统一使用master进行配置管理,非常方便进行部署,监控和维护
核心的agent,collector服务可以对其中的处理汇总进行分拆,易于分布式部署
2) 缺点
对系统的稳定性要求较高,如果agent异常退出,可能会丢失日志
对collector的性能要求较高,直接影响到日志收集服务器的负载
2.2. 未来方案
1) 引入实时流计算框架storm,更好地对大数据进行实时分析处理;2) 直接传输至HDFS,进行离线大数据计算,主要对一些日期久远的日志及不需要实时计算的日志进行统计分析。

相关文章推荐
- 一起谈.NET技术,Xml日志记录文件最优方案(附源代码)
- 分布式日志收集系统: Facebook Scribe之日志收集方案
- 记录一下互联网日志实时收集和实时计算的简单方案
- 容器内应用日志收集方案
- 万亿级日志与行为数据存储查询技术剖析——Hbase系预聚合方案、Dremel系parquet列存储、预聚合系、Lucene系
- [工会网站建设方案-日志]第一阶段 策划:收集、整理、分析
- Tomcat容器日志收集方案fluentd+elasticsearch+kilbana
- IT技术方案最佳实践方案的收集
- 技术团队工作外娱乐放松活动方案收集
- 日志存储系统常用技术方案介绍
- 基于淘宝Tengine和Scribe的WEB日志收集方案
- 大规模日志收集处理项目的技术总结
- flume对nginx群集日志收集方案
- Docker容器内应用的日志收集方案
- (转)大规模日志收集处理项目的技术总结
- 分布式日志收集系统: Facebook Scribe之日志收集方案
- 技术团队工作外娱乐放松活动方案收集
- Flume对Nginx群集日志收集方案
- 容器内应用日志收集方案
- Nginx容器日志收集方案fluentd+elasticsearch+kilbana