Linux入门基础之grep命令详解及正则表达式
2014-11-15 20:48
1586 查看
grep命令是linux下经常使用的命令之一,能根据用户指定的模式(pattern)对文本进行过滤,显示出匹配到的行。其命令格式为:
grep [OPTIONS] PATTERN [FILE]
例如:我们要查找网卡0中配置的IP地址(该文件路径: /etc/sysconfig/network-scripts/ifcfg-eth0)---grep 'IPADDR' /etc/sysconfig/network-scripts/ifcfg-eth0

(注:alias grep='grep --color=auto' 让匹配结果高亮显示)
grep常用的几个选项(option)有: -v:反向选取,即显示 模式过滤之后的剩余的行
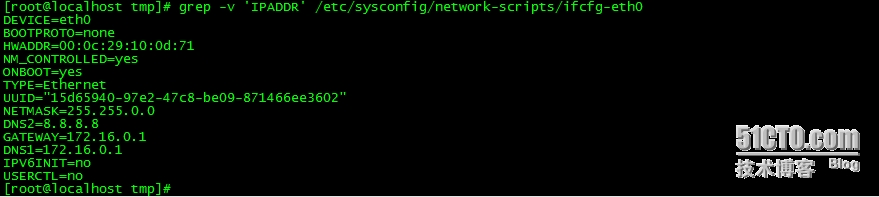
除IPADDR这一行没有显示之外,其他内容都显示给用户。
-i:忽略字符大小写

第一条命令没有过滤到任何内容,因此没有显示出结果,忽略大小写之后,显示出匹配到的行。
-o:仅显示过滤的内容

仅显示根据指定模式过滤的内容。
那么什么是Pattern呢?
PATTERN表示用户给定的模式,为什么这个地方我们把他叫做模式而不是说成字符,是因为通常要使用正则表达式[b](regexp)[/b]。而正则表达式就是一类特殊的字符,这类字符当中有些字符通常并不代表其字面意思,而是作为一种控制或通配(globbing)的功用。这类字符也被称为元字符。那么,读者朋友们可能就总结出来了,我们所称的模式Pattern其实由字符加元字符组成的。正则表达式正是由这些元字符所构成,与grep一起过滤文本,并用在以后的shell编程中。
正则表达式分为基本正则表达式和扩展正则表达式两大类。
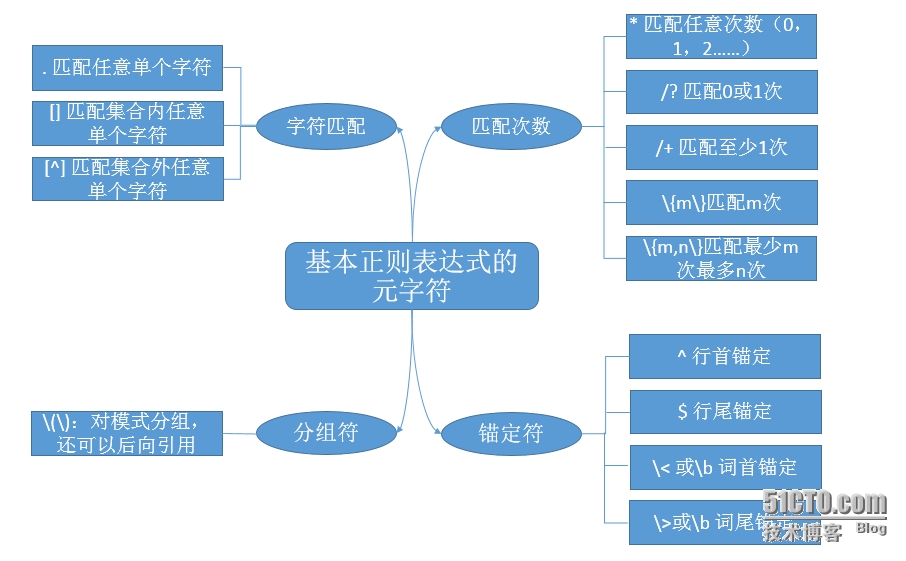
基本正则表达式的元字符有以下字符:
过滤字符的 . 表示匹配任意单个字符。则a..b表示a和b之间有两个字符。
[]表示匹配集合内任意单个字符。则a[bc]表示ab或者ac,注:abc也是符合模式的
[^]表示匹配集合外任意[b]单个字符。[/b]
特殊表达写法:[0-9]可以用[[:digit:]]表示
[a-z]可以用[[:lower:]]表示
[A-Z]可以用[[:upper:]]表示
[a-zA-Z]即所有字母可以用[[:alpha:]]]表示
[0-9a-zA-Z]即所有字母和数字可以用[[:alnum:]]表示
空白(空格字符、Tab制表符等)用[[:space:]]表示
所有标点符号用[[:punct:]]表示
匹配次数的(对其紧邻前面字符出现的次数做出限定)
* 表示匹配*前面字符出现任意次0,1,2……,则a*b表示a出现任意次。
\? 表示匹配?前面字符出现0或1次(\仅代表转义的作用),则a\?b表示a出现0或1次
\{m\} 表示匹配{m}前面字符出现m次,则a\{2\}表示a出现2次
\{m,n\} 表示[b]匹配{m}前面字符最少出现m次最多出现n次,引申出\{m,\}最少m次, \{0,n\} 最多n次。[/b]则a\{1,2\}表示a出现最少1次最多2次。
\+也可以表示为最少出现1次
锚定位置的(对字符进行定位,书写格式简单记为:首左,尾右)
^ 表示行首锚定,则^a表示a必须出现在某行的开头
$ 表示行尾锚定,则a$表示某行以a结尾
\< 表示词首锚定,则\<a表示某词以a开头
\> 表示词尾锚定,则\>a表示某词以a结尾
分组符将指定字符分成组,以组的的形式进行匹配。
\(\),则\(ab\)表示ab为一组
[b]支持后向引用,\1,\2,\3……表示自左向右引用其第#个(开始,第#)结束直接的内容。[/b]
扩展:正则表达式引擎在对某文本内容进行检索时,若使用了分组符()的模式成功实现了匹配,此次括号内部的Pattern匹配到的文本会被正则表达式引擎予以自动记录,按照左括号“(”出现的次序,依次记录在\1,\2,\3……中;匹配到的内容可在同一模式的后面进行引用。
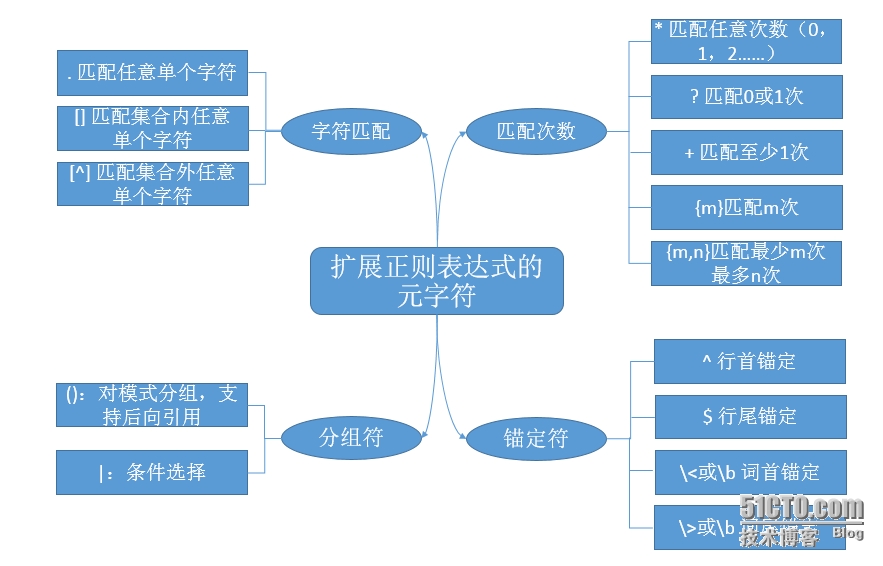
扩展正则表达式用法与基本正则表达式相同,只是书写格式上不必写转义符而已,比基本正则表示多了一条条件选择符:| 即ab|cd 表示ab或cd
i.匹配字符的有 . [] [^]
ii.匹配次数的有 * ? + {m} {m,n} {m,} {0,n}
iii.锚定符有 ^ $ \<或\b \>或\b
iv.分组符有 () |
正则表达式练习
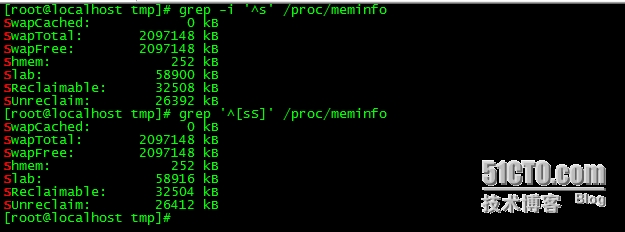
1、显示/proc/meminfo文件中以大写或小写S开头的行;
grep -i '^s' /proc/meminfo
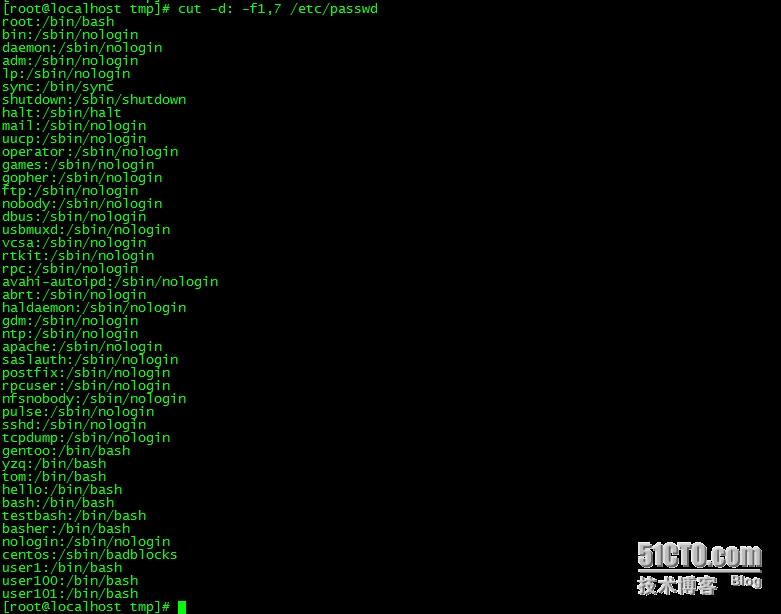
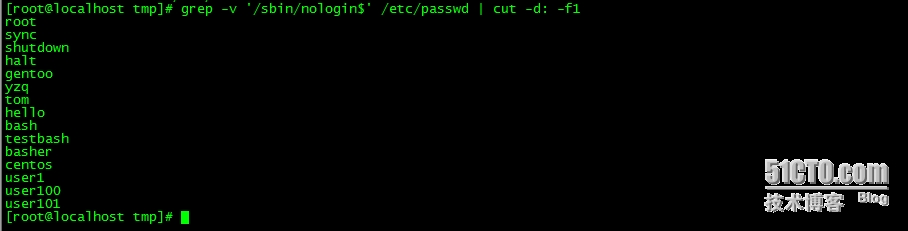
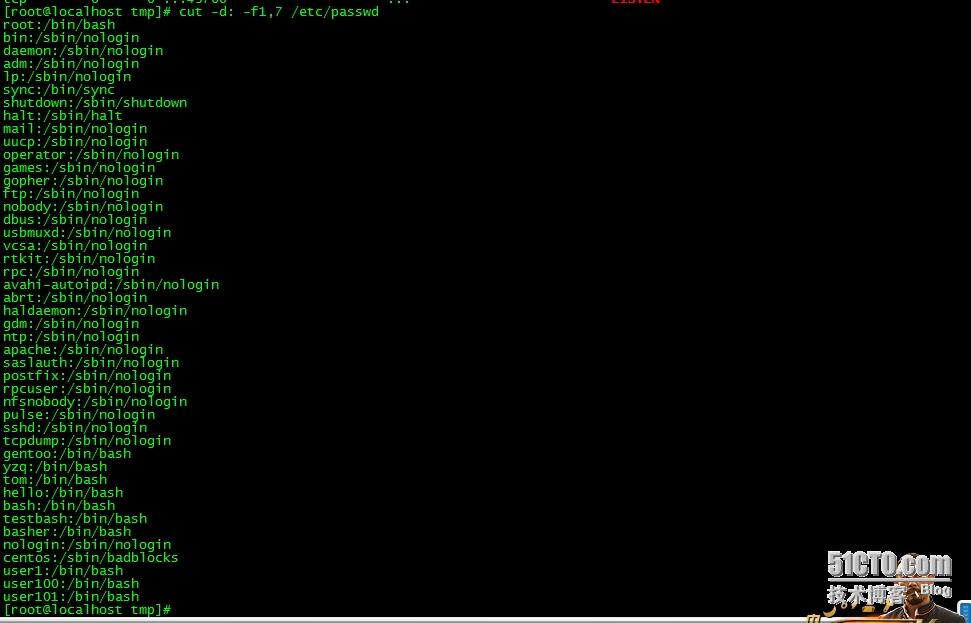
2、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
grep -v '/sbin/nologin$' /etc/passwd | cut -d: -f1
3、显示/etc/passwd文件中其默认shell为/bin/bash的用户;进一步:仅显示上述结果中其ID号最大的用户;
grep '/bin/bash$' /etc/passwd | cut -d: -f1
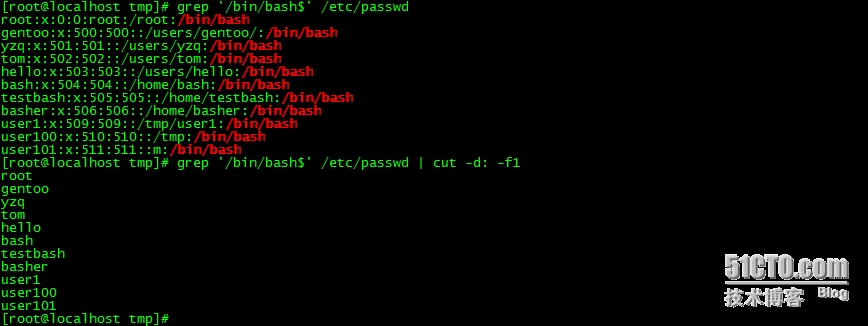
grep '/bin/bash$' /etc/passwd | sort -t: -k3 -n | tail -1 | grep -o '^[[:alnum:]]\+'

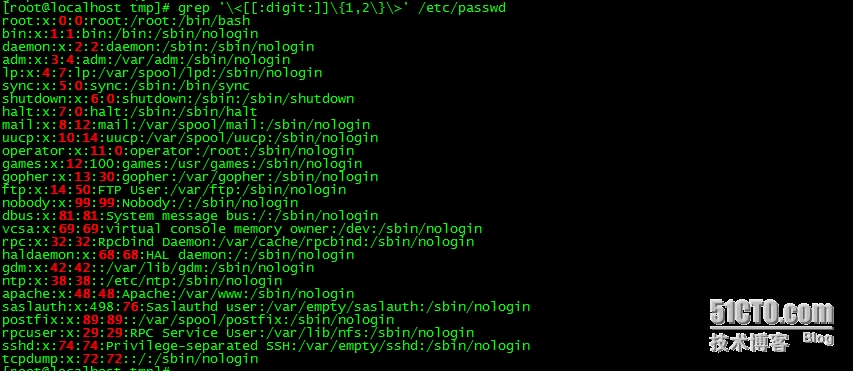
4、找出/etc/passwd文件中的一位数或两位数;
grep '\<[[:digit:]]\{1,2\}\>' /etc/passwd
5、显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
grep '^[[:space:]]\+' /boot/grub/grub.conf

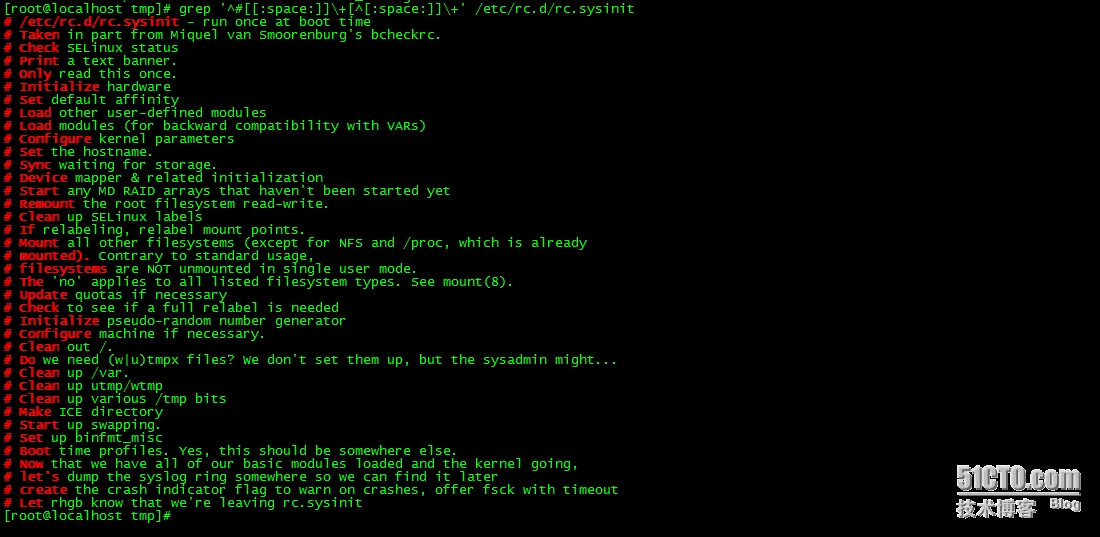
6、显示/etc/rc.d/rc.sysinit文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
grep '^#[[:space:]]\+[^[:space:]]\+' /etc/rc.d/rc.sysinit
7、找出netstat -tan命令执行结果中以'LISTEN'(后可有空白字符)结尾的行;
netstat -tan | grep 'LISTEN[[:space:]]*$'

8、添加用户bash, testbash, basher, nologin(SHELL为/sbin/nologin),而找出当前系统上其用户名和默认shell相同的用户;
grep '^\([[:alnum:]]\+\).*\1$' /etc/passwd

9、扩展题:新建一个文本文件,假设有如下内容:
He like his lover.
He love his lover.
He like his liker.
He love his liker.
找出其中最后一个单词是由此前某单词加r构成的行。
# nano blog.text
# grep '\(\<[[:alpha:]]\+\>\).*\1r' ./blog.text

使用egrep完成下面的练习
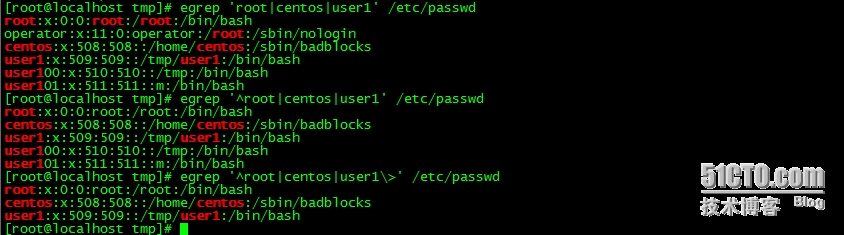
练习10:显示当前系统上root、centos或user1用户的默认shell及用户名;
egrep '^root|centos|user1\>' /etc/passwd
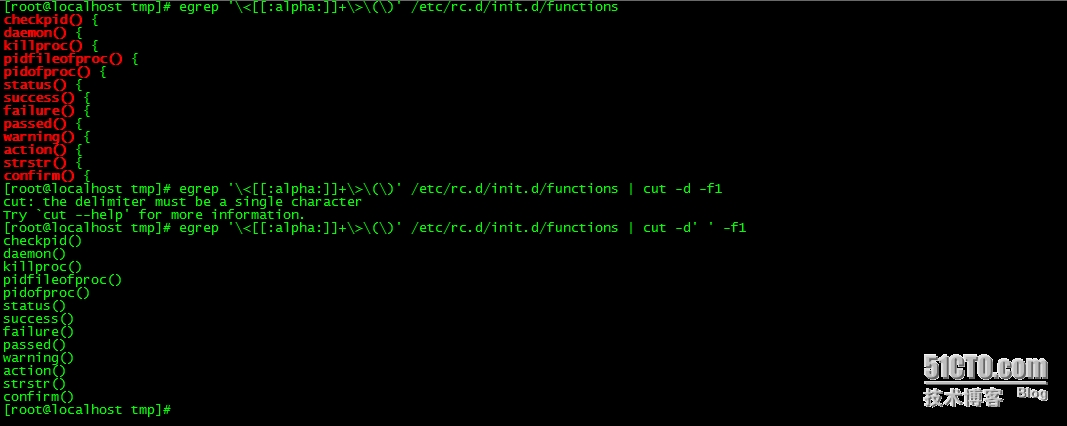
练习11:找出/etc/rc.d/init.d/functions文件中某单词后面跟一对小括号"()"的行;
egrep '\<[[:alpha:]]+\>\(\)' /etc/rc.d/init.d/functions | cut -d' ' -f1
练习12:使用echo输出一个路径,而使用egrep取出其基名;
echo /tmp/abc-/-s | egrep -o '[^/]+$'

练习13:找出ifconfig命令结果中的1-255之间的数值;
ifconfig | egrep '\<([1-9]|[1-9][0-9]|1[0-9]\+|2[0-4][0-9]|25[0-5])\>'
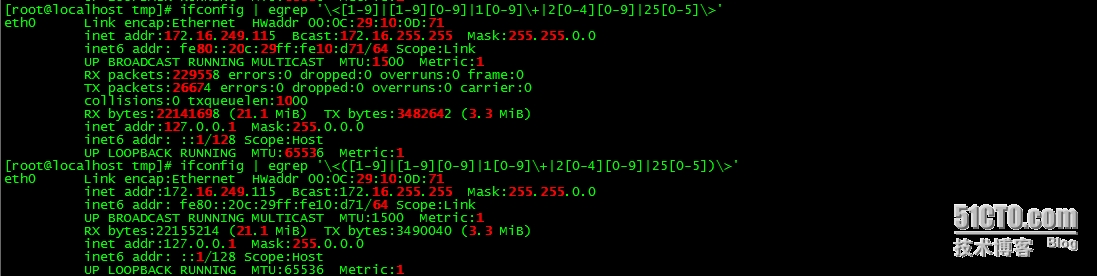
练习14:找出ifconfig命令结果中的IP地址;(提示:1.0.0.1 - 223.255.255.254)
ifconfig | egrep -o '(\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0,1][0-9]|22[0-3])\>\.\<([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>\.\<(1|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>)'

经验之谈:把要搜索的文本内容全部看成单个的字符,更容易理解。
扩展:还有一种快速检索工具fgrep,但他不支持正则表达式,因此很少使用。
grep [OPTIONS] PATTERN [FILE]
例如:我们要查找网卡0中配置的IP地址(该文件路径: /etc/sysconfig/network-scripts/ifcfg-eth0)---grep 'IPADDR' /etc/sysconfig/network-scripts/ifcfg-eth0
(注:alias grep='grep --color=auto' 让匹配结果高亮显示)
grep常用的几个选项(option)有: -v:反向选取,即显示 模式过滤之后的剩余的行
除IPADDR这一行没有显示之外,其他内容都显示给用户。
-i:忽略字符大小写
第一条命令没有过滤到任何内容,因此没有显示出结果,忽略大小写之后,显示出匹配到的行。
-o:仅显示过滤的内容
仅显示根据指定模式过滤的内容。
那么什么是Pattern呢?
PATTERN表示用户给定的模式,为什么这个地方我们把他叫做模式而不是说成字符,是因为通常要使用正则表达式[b](regexp)[/b]。而正则表达式就是一类特殊的字符,这类字符当中有些字符通常并不代表其字面意思,而是作为一种控制或通配(globbing)的功用。这类字符也被称为元字符。那么,读者朋友们可能就总结出来了,我们所称的模式Pattern其实由字符加元字符组成的。正则表达式正是由这些元字符所构成,与grep一起过滤文本,并用在以后的shell编程中。
正则表达式分为基本正则表达式和扩展正则表达式两大类。
基本正则表达式的元字符有以下字符:
过滤字符的 . 表示匹配任意单个字符。则a..b表示a和b之间有两个字符。
[]表示匹配集合内任意单个字符。则a[bc]表示ab或者ac,注:abc也是符合模式的
[^]表示匹配集合外任意[b]单个字符。[/b]
特殊表达写法:[0-9]可以用[[:digit:]]表示
[a-z]可以用[[:lower:]]表示
[A-Z]可以用[[:upper:]]表示
[a-zA-Z]即所有字母可以用[[:alpha:]]]表示
[0-9a-zA-Z]即所有字母和数字可以用[[:alnum:]]表示
空白(空格字符、Tab制表符等)用[[:space:]]表示
所有标点符号用[[:punct:]]表示
匹配次数的(对其紧邻前面字符出现的次数做出限定)
* 表示匹配*前面字符出现任意次0,1,2……,则a*b表示a出现任意次。
\? 表示匹配?前面字符出现0或1次(\仅代表转义的作用),则a\?b表示a出现0或1次
\{m\} 表示匹配{m}前面字符出现m次,则a\{2\}表示a出现2次
\{m,n\} 表示[b]匹配{m}前面字符最少出现m次最多出现n次,引申出\{m,\}最少m次, \{0,n\} 最多n次。[/b]则a\{1,2\}表示a出现最少1次最多2次。
\+也可以表示为最少出现1次
锚定位置的(对字符进行定位,书写格式简单记为:首左,尾右)
^ 表示行首锚定,则^a表示a必须出现在某行的开头
$ 表示行尾锚定,则a$表示某行以a结尾
\< 表示词首锚定,则\<a表示某词以a开头
\> 表示词尾锚定,则\>a表示某词以a结尾
分组符将指定字符分成组,以组的的形式进行匹配。
\(\),则\(ab\)表示ab为一组
[b]支持后向引用,\1,\2,\3……表示自左向右引用其第#个(开始,第#)结束直接的内容。[/b]
扩展:正则表达式引擎在对某文本内容进行检索时,若使用了分组符()的模式成功实现了匹配,此次括号内部的Pattern匹配到的文本会被正则表达式引擎予以自动记录,按照左括号“(”出现的次序,依次记录在\1,\2,\3……中;匹配到的内容可在同一模式的后面进行引用。
扩展正则表达式用法与基本正则表达式相同,只是书写格式上不必写转义符而已,比基本正则表示多了一条条件选择符:| 即ab|cd 表示ab或cd
i.匹配字符的有 . [] [^]
ii.匹配次数的有 * ? + {m} {m,n} {m,} {0,n}
iii.锚定符有 ^ $ \<或\b \>或\b
iv.分组符有 () |
正则表达式练习
1、显示/proc/meminfo文件中以大写或小写S开头的行;
grep -i '^s' /proc/meminfo
2、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
grep -v '/sbin/nologin$' /etc/passwd | cut -d: -f1
3、显示/etc/passwd文件中其默认shell为/bin/bash的用户;进一步:仅显示上述结果中其ID号最大的用户;
grep '/bin/bash$' /etc/passwd | cut -d: -f1
grep '/bin/bash$' /etc/passwd | sort -t: -k3 -n | tail -1 | grep -o '^[[:alnum:]]\+'
4、找出/etc/passwd文件中的一位数或两位数;
grep '\<[[:digit:]]\{1,2\}\>' /etc/passwd
5、显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
grep '^[[:space:]]\+' /boot/grub/grub.conf
6、显示/etc/rc.d/rc.sysinit文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
grep '^#[[:space:]]\+[^[:space:]]\+' /etc/rc.d/rc.sysinit
7、找出netstat -tan命令执行结果中以'LISTEN'(后可有空白字符)结尾的行;
netstat -tan | grep 'LISTEN[[:space:]]*$'
8、添加用户bash, testbash, basher, nologin(SHELL为/sbin/nologin),而找出当前系统上其用户名和默认shell相同的用户;
grep '^\([[:alnum:]]\+\).*\1$' /etc/passwd
9、扩展题:新建一个文本文件,假设有如下内容:
He like his lover.
He love his lover.
He like his liker.
He love his liker.
找出其中最后一个单词是由此前某单词加r构成的行。
# nano blog.text
# grep '\(\<[[:alpha:]]\+\>\).*\1r' ./blog.text
使用egrep完成下面的练习
练习10:显示当前系统上root、centos或user1用户的默认shell及用户名;
egrep '^root|centos|user1\>' /etc/passwd
练习11:找出/etc/rc.d/init.d/functions文件中某单词后面跟一对小括号"()"的行;
egrep '\<[[:alpha:]]+\>\(\)' /etc/rc.d/init.d/functions | cut -d' ' -f1
练习12:使用echo输出一个路径,而使用egrep取出其基名;
echo /tmp/abc-/-s | egrep -o '[^/]+$'
练习13:找出ifconfig命令结果中的1-255之间的数值;
ifconfig | egrep '\<([1-9]|[1-9][0-9]|1[0-9]\+|2[0-4][0-9]|25[0-5])\>'
练习14:找出ifconfig命令结果中的IP地址;(提示:1.0.0.1 - 223.255.255.254)
ifconfig | egrep -o '(\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[0,1][0-9]|22[0-3])\>\.\<([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>\.\<(1|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\>)'
经验之谈:把要搜索的文本内容全部看成单个的字符,更容易理解。
扩展:还有一种快速检索工具fgrep,但他不支持正则表达式,因此很少使用。

相关文章推荐
- Linux命令之grep用法详解:grep与正则表达式 [转]
- bzgrep命令_Linux bzgrep 命令用法详解:使用正则表达式搜索.bz2压缩包中文件
- Linux中grep命令,用或的关系查询多个字符串,正则表达式基础说明
- Linux基础知识——grep命令、正则表达式
- Linux基础入门及系统管理01-Shell三剑客之grep及正则表达式14
- Linux学习日记--基础命令(6)--grep及正则表达式
- 开发环境入门 linux基础 (部分)正则表达式 grep sed
- linux系统下的grep命令功能与正则表达式详解
- Linux基础(三)--grep的使用和基本正则表达式
- Linux基础入门及系统管理01-Linux用户管理命令详解11
- Linux中命令grep与基本正则表达式
- 【APP】Linux运维利器--Grep命令及正则表达式
- Linux基础入门及系统管理01-Linux文件管理类命令详解08
- linux之grep命令和正则表达式练习
- Linux grep 命令功能、正则表达式
- Linux 的grep命令与正则表达式
- Linux正则表达式详解_GREP
- linux基本命令grep egrep fgrep用法以及正则表达式
- Linux基础知识之正则表达式、grep、egrep的用法
- Linux grep命令与正则表达式学习