RabbitMQ学习之集群部署
2014-11-13 15:04
423 查看
生产环境:
CentOS 6.3 x86_64
服务器主机名与IP列表:
mq136 172.28.2.136
mq137 172.28.2.137
mq164 172.28.2.164
mq165 172.28.2.165
在各节点服务器上作好hosts解析
cat >>/etc/hosts/<<EOF
mq136 172.28.2.136
mq137 172.28.2.137
mq164 172.28.2.164
mq165 172.28.2.165
EOF
一、简介
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。Erlang的分布式通讯安全策略,可以归结为 All or None。。RabbitMQ是AMQP(高级消息队列协议)的标准实现。RabbitMQ的结构图如下:
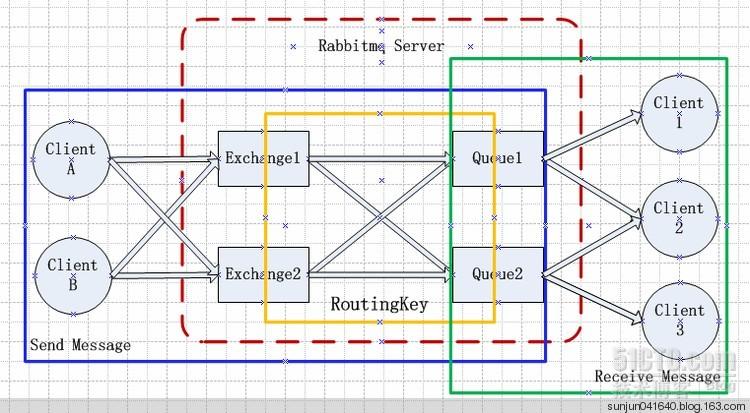
几个概念说明:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。对key进行模式匹配后进行投递的叫做Topic交换机,符号”#”匹配一个或多个词,符号”*”匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。还有一种不需要key的,叫做Fanout交换机,它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列。
RabbitMQ支持消息的持久化,也就是数据写在磁盘上,为了数据安全考虑,我想大多数用户都会选择持久化。消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode => 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
下面我们再了解下消息队列RabbitMQ集群,由于RabbitMQ是用erlang开发的,RabbitMQ 完全依赖 Erlang 的Cluster,而Erlang集群非常方便,因此配置RabbitMQ集群变得非常简单。
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
良好的设计架构可以如下:在一个集群里,有3台以上机器,其中1台使用磁盘模式,其它使用内存模式。其它几台为内存模式的节点,无疑速度更快,因此客户端(consumer、producer)连接访问它们。而磁盘模式的节点,由于磁盘IO相对较慢,因此仅作数据备份使用。
二、各节点安装rabbitmq
安装非常简单,只需几步搞定:
1. 安装epel源
rpm -ivh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-7.noarch.rpm
wget -O /etc/yum.repos.d/epel-erlang.repo http://repos.fedorapeople.org/repos/peter/erlang/epel-erlang.repo
2. 安装erlang
yum install erlang xmlto git -y
rpm --import http://www.rabbitmq.com/rabbitmq-signing-key-public.asc
3. 安装rabbitmq
可以选择用yum安装,也可以选择下载rpm包安装,也可以用源码编译安装!
下载地址: http://www.rabbitmq.com/download.html
本文选择rpm包安装:
wget http://www.rabbitmq.com/releases/rabbitmq-server/v2.8.6/rabbitmq-server-2.8.6.noarch.rpm
rpm -ivh rabbitmq-server-2.8.6.noarch.rpm
4. 启动各节点rabbitmq,并验证启动情况
[root@mq136 ~]# rabbitmq-server --detached &
[root@mq136 ~]# ps aux |grep rabbitmq
rabbitmq 1394 0.0 0.0 10828 540 ? S Oct08 0:11 /usr/lib64/erlang/erts-5.8.5/bin/epmd -daemon
root 2483 0.0 0.0 103244 836 pts/1 S+ 17:40 0:00 grep rabbitmq
rabbitmq 5657 6.3 1.9 2224044 157200 ? Sl Oct08 959:17 /usr/lib64/erlang/erts-5.8.5/bin/beam.smp -W w -K true -A30 -P 1048576 -- -root /usr/lib64/erlang -progname erl -- -home /var/lib/rabbitmq --
-noshell -noinput -sname rabbit@mq136 -boot /var/lib/rabbitmq/mnesia/rabbit@mq136-plugins-expand/rabbit -kernel inet_default_connect_options [{nodelay,true}] -sasl errlog_type error -sasl sasl_error_logger false -rabbit error_logger {file,"/var/log/rabbitmq/rabbit@mq136.log"}
-rabbit sasl_error_logger {file,"/var/log/rabbitmq/rabbit@mq136-sasl.log"} -os_mon start_cpu_sup false -os_mon start_disksup false -os_mon start_memsup false -mnesia dir"/var/lib/rabbitmq/mnesia/rabbit@mq136" -noshell -noinput
rabbitmq 5698 0.0 0.0 10788 520 ? Ss Oct08 0:00 inet_gethost 4
rabbitmq 5699 0.0 0.0 12892 692 ? S Oct08 0:00 inet_gethost 4
rabbitmq 11446 0.0 0.0 12892 680 ? S Oct13 0:00 inet_gethost 4
[root@mq136 ~]# lsof -i:5672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5657 rabbitmq 18u IPv4 5879364 0t0 TCP *:amqp (LISTEN)
三、集群配置
集群环境说明:
mq136作为磁盘节点,其它所有节点都作为内存节点!
1. 在各节点创建加入集群脚本
mq136:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster
rabbitmqctl start_app
EOF
mq137:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
mq164:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
mq165:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
2. 各节点加入集群环境
[root@mq136 ~]# chmod +x /home/zjqui/scripts/cluster.sh
启动脚本顺序:先运行mq136节点集群脚本,然后再运行其它节点集群脚本:
[root@mq136 ~]# /home/zjqui/scripts/cluster.sh
各节点运行成功后,查看集群整体状态:
[root@mq136 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@mq136 ...
[{nodes,[{disc,[rabbit@mq136]},
{ram,[rabbit@mq165,rabbit@mq164,rabbit@mq137]}]},
{running_nodes,[rabbit@mq164,rabbit@mq165,rabbit@mq137,rabbit@mq136]}]
...done.
可以看到mq136作为disc节点,其它节点是ram节点!集群简单配置到此完成!!
部署nova使用高可用队列主要两个步骤:
1. 配置RabbitMQ集群
确保所有RabbitMQ服务不在运行,之后同步集群中所有RabbitMQ服务器上的cookie:
sudo service rabbitmq-server stop
scp /var/lib/rabbitmq/.erlang.cookie \
root@rabbit2:/var/lib/rabbitmq/.erlang.cookie
sudo service rabbitmq-server start
建立集群
root@rabbit2: rabbitmqctl stop_app
root@rabbit2: rabbitmqctl cluster rabbit@rabbit1
root@rabbit2: rabbitmqctl start_app
建立disc集群
root@rabbit2: rabbitmqctl stop_app
root@rabbit2: rabbitmqctl cluster rabbit@rabbit1 rabbit@rabbit2
root@rabbit2: rabbitmqctl start_app
完成后可以在集群中任意一台RabbitMQ上看到集群状态
$ sudo rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1]},{ram,[rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]
...done.
2. 配置nova
编辑nova.conf
rabbit_hosts = rabbit1:5672,rabbit2:5672
rabbit_host = rabbit1
rabbit_ha_queues = true
如果配置了rabbit_hosts,那么nova将会按照顺序连接一个RabbitMQ服务,如果正在使用的MQ服务断开则依次尝试连接下一个,由于所有MQ的消息都是同步的,所以消息不会丢失。
如果配置了rabbit_host,那么需要在集群前架设haproxy,保证集群VIP服务正常。
之后重启nova的所有服务即可。
可以通过以下命令查看队列是否为高可用
sudo rabbitmqctl list_queues name arguments
Listing queues ...
compute [{"x-ha-policy","all"}]
compute.u2 [{"x-ha-policy","all"}]
compute_fanout_e35fae767bf645afa37649ece0fbc20f [{"x-ha-policy","all"}]
conductor [{"x-ha-policy","all"}]
conductor.u2 [{"x-ha-policy","all"}]
conductor_fanout_e36e99cf03214e45be95aed2028b998a [{"x-ha-policy","all"}]
glance_notifications.error [{"x-ha-policy","all"}]
glance_notifications.info [{"x-ha-policy","all"}]
glance_notifications.warn [{"x-ha-policy","all"}]
network [{"x-ha-policy","all"}]
network.u2 [{"x-ha-policy","all"}]
network_fanout_06a0feca2c2f4252bf6c60051f5e162d [{"x-ha-policy","all"}]
notifications.error [{"x-ha-policy","all"}]
notifications.info [{"x-ha-policy","all"}]
reply_bffe093751b1422e9a23464086d78c26 [{"x-ha-policy","all"}]
scheduler [{"x-ha-policy","all"}]
scheduler.u2 [{"x-ha-policy","all"}]
scheduler_fanout_afab782a2ade4b12848262b4259f1cb1 [{"x-ha-policy","all"}]
...done.
按照如上配置方法,测试havana的nova,确认在某MQ停服的情况下nova的反应。
此case意在验证rabbitmq集群的同步功能,是否会对nova造成影响。
配置RabbitMQ集群,并且nova.conf中开启rabbit_ha_queues = true。nova-api使用的rabbit_host=rabbit1, 其他nova-X使用的rabbit_host=rabbit2,注意这里没有配置rabbit_hosts。之后正常使用nova服务,所有操作都正常执行。说明MQ的镜像模式可以支持nova的消息通信。
此case意在观察MQ集群出现问题时nova的反应。同样配置RabbitMQ集群,配置nova.conf的rabbit_hosts=rabbit1:5672, rabbit2:5672。正常开启nova服务,观察到nova-X服务首先连接rabbit1服务,当关闭rabbit1服务后,连接断开,再次尝试连接rabbit1,失败后开始尝试连接rabbit2,之后保持连接rabbit2并正常服务。说明nova可以自行判断MQ服务的状态,并且自动重连,可以在不部署Haproxy的情况下使用高可用MQ。
havana nova对高可用RabbitMQ的支持比较好,基本可以满足高可用需求,对于RabbitMQ的集群既可以部署haproxy,也可以直接配置rabbit_hosts,让nova自动重连。从方便运维的角度出发,减少不必要的依赖,减少出问题的可能,所以建议直接使用nova的rabbit_hosts。
CentOS 6.3 x86_64
服务器主机名与IP列表:
mq136 172.28.2.136
mq137 172.28.2.137
mq164 172.28.2.164
mq165 172.28.2.165
在各节点服务器上作好hosts解析
cat >>/etc/hosts/<<EOF
mq136 172.28.2.136
mq137 172.28.2.137
mq164 172.28.2.164
mq165 172.28.2.165
EOF
一、简介
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。Erlang的分布式通讯安全策略,可以归结为 All or None。。RabbitMQ是AMQP(高级消息队列协议)的标准实现。RabbitMQ的结构图如下:
几个概念说明:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。对key进行模式匹配后进行投递的叫做Topic交换机,符号”#”匹配一个或多个词,符号”*”匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。还有一种不需要key的,叫做Fanout交换机,它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列。
RabbitMQ支持消息的持久化,也就是数据写在磁盘上,为了数据安全考虑,我想大多数用户都会选择持久化。消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode => 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
下面我们再了解下消息队列RabbitMQ集群,由于RabbitMQ是用erlang开发的,RabbitMQ 完全依赖 Erlang 的Cluster,而Erlang集群非常方便,因此配置RabbitMQ集群变得非常简单。
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
良好的设计架构可以如下:在一个集群里,有3台以上机器,其中1台使用磁盘模式,其它使用内存模式。其它几台为内存模式的节点,无疑速度更快,因此客户端(consumer、producer)连接访问它们。而磁盘模式的节点,由于磁盘IO相对较慢,因此仅作数据备份使用。
二、各节点安装rabbitmq
安装非常简单,只需几步搞定:
1. 安装epel源
rpm -ivh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-7.noarch.rpm
wget -O /etc/yum.repos.d/epel-erlang.repo http://repos.fedorapeople.org/repos/peter/erlang/epel-erlang.repo
2. 安装erlang
yum install erlang xmlto git -y
rpm --import http://www.rabbitmq.com/rabbitmq-signing-key-public.asc
3. 安装rabbitmq
可以选择用yum安装,也可以选择下载rpm包安装,也可以用源码编译安装!
下载地址: http://www.rabbitmq.com/download.html
本文选择rpm包安装:
wget http://www.rabbitmq.com/releases/rabbitmq-server/v2.8.6/rabbitmq-server-2.8.6.noarch.rpm
rpm -ivh rabbitmq-server-2.8.6.noarch.rpm
4. 启动各节点rabbitmq,并验证启动情况
[root@mq136 ~]# rabbitmq-server --detached &
[root@mq136 ~]# ps aux |grep rabbitmq
rabbitmq 1394 0.0 0.0 10828 540 ? S Oct08 0:11 /usr/lib64/erlang/erts-5.8.5/bin/epmd -daemon
root 2483 0.0 0.0 103244 836 pts/1 S+ 17:40 0:00 grep rabbitmq
rabbitmq 5657 6.3 1.9 2224044 157200 ? Sl Oct08 959:17 /usr/lib64/erlang/erts-5.8.5/bin/beam.smp -W w -K true -A30 -P 1048576 -- -root /usr/lib64/erlang -progname erl -- -home /var/lib/rabbitmq --
-noshell -noinput -sname rabbit@mq136 -boot /var/lib/rabbitmq/mnesia/rabbit@mq136-plugins-expand/rabbit -kernel inet_default_connect_options [{nodelay,true}] -sasl errlog_type error -sasl sasl_error_logger false -rabbit error_logger {file,"/var/log/rabbitmq/rabbit@mq136.log"}
-rabbit sasl_error_logger {file,"/var/log/rabbitmq/rabbit@mq136-sasl.log"} -os_mon start_cpu_sup false -os_mon start_disksup false -os_mon start_memsup false -mnesia dir"/var/lib/rabbitmq/mnesia/rabbit@mq136" -noshell -noinput
rabbitmq 5698 0.0 0.0 10788 520 ? Ss Oct08 0:00 inet_gethost 4
rabbitmq 5699 0.0 0.0 12892 692 ? S Oct08 0:00 inet_gethost 4
rabbitmq 11446 0.0 0.0 12892 680 ? S Oct13 0:00 inet_gethost 4
[root@mq136 ~]# lsof -i:5672
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
beam.smp 5657 rabbitmq 18u IPv4 5879364 0t0 TCP *:amqp (LISTEN)
三、集群配置
集群环境说明:
mq136作为磁盘节点,其它所有节点都作为内存节点!
1. 在各节点创建加入集群脚本
mq136:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster
rabbitmqctl start_app
EOF
mq137:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
mq164:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
mq165:
cat >>/home/zjqui/scripts/cluster.sh<<EOF
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl cluster rabbit@mq136
rabbitmqctl start_app
EOF
2. 各节点加入集群环境
[root@mq136 ~]# chmod +x /home/zjqui/scripts/cluster.sh
启动脚本顺序:先运行mq136节点集群脚本,然后再运行其它节点集群脚本:
[root@mq136 ~]# /home/zjqui/scripts/cluster.sh
各节点运行成功后,查看集群整体状态:
[root@mq136 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@mq136 ...
[{nodes,[{disc,[rabbit@mq136]},
{ram,[rabbit@mq165,rabbit@mq164,rabbit@mq137]}]},
{running_nodes,[rabbit@mq164,rabbit@mq165,rabbit@mq137,rabbit@mq136]}]
...done.
可以看到mq136作为disc节点,其它节点是ram节点!集群简单配置到此完成!!
部署nova使用高可用队列主要两个步骤:
1. 配置RabbitMQ集群
确保所有RabbitMQ服务不在运行,之后同步集群中所有RabbitMQ服务器上的cookie:
sudo service rabbitmq-server stop
scp /var/lib/rabbitmq/.erlang.cookie \
root@rabbit2:/var/lib/rabbitmq/.erlang.cookie
sudo service rabbitmq-server start
建立集群
root@rabbit2: rabbitmqctl stop_app
root@rabbit2: rabbitmqctl cluster rabbit@rabbit1
root@rabbit2: rabbitmqctl start_app
建立disc集群
root@rabbit2: rabbitmqctl stop_app
root@rabbit2: rabbitmqctl cluster rabbit@rabbit1 rabbit@rabbit2
root@rabbit2: rabbitmqctl start_app
完成后可以在集群中任意一台RabbitMQ上看到集群状态
$ sudo rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1]},{ram,[rabbit@rabbit2]}]},
{running_nodes,[rabbit@rabbit2,rabbit@rabbit1]}]
...done.
2. 配置nova
编辑nova.conf
rabbit_hosts = rabbit1:5672,rabbit2:5672
rabbit_host = rabbit1
rabbit_ha_queues = true
如果配置了rabbit_hosts,那么nova将会按照顺序连接一个RabbitMQ服务,如果正在使用的MQ服务断开则依次尝试连接下一个,由于所有MQ的消息都是同步的,所以消息不会丢失。
如果配置了rabbit_host,那么需要在集群前架设haproxy,保证集群VIP服务正常。
之后重启nova的所有服务即可。
可以通过以下命令查看队列是否为高可用
sudo rabbitmqctl list_queues name arguments
Listing queues ...
compute [{"x-ha-policy","all"}]
compute.u2 [{"x-ha-policy","all"}]
compute_fanout_e35fae767bf645afa37649ece0fbc20f [{"x-ha-policy","all"}]
conductor [{"x-ha-policy","all"}]
conductor.u2 [{"x-ha-policy","all"}]
conductor_fanout_e36e99cf03214e45be95aed2028b998a [{"x-ha-policy","all"}]
glance_notifications.error [{"x-ha-policy","all"}]
glance_notifications.info [{"x-ha-policy","all"}]
glance_notifications.warn [{"x-ha-policy","all"}]
network [{"x-ha-policy","all"}]
network.u2 [{"x-ha-policy","all"}]
network_fanout_06a0feca2c2f4252bf6c60051f5e162d [{"x-ha-policy","all"}]
notifications.error [{"x-ha-policy","all"}]
notifications.info [{"x-ha-policy","all"}]
reply_bffe093751b1422e9a23464086d78c26 [{"x-ha-policy","all"}]
scheduler [{"x-ha-policy","all"}]
scheduler.u2 [{"x-ha-policy","all"}]
scheduler_fanout_afab782a2ade4b12848262b4259f1cb1 [{"x-ha-policy","all"}]
...done.
测试结果
按照如上配置方法,测试havana的nova,确认在某MQ停服的情况下nova的反应。
Case1:nova-api使用rabbit1,其他nova-X服务使用rabbit2
此case意在验证rabbitmq集群的同步功能,是否会对nova造成影响。配置RabbitMQ集群,并且nova.conf中开启rabbit_ha_queues = true。nova-api使用的rabbit_host=rabbit1, 其他nova-X使用的rabbit_host=rabbit2,注意这里没有配置rabbit_hosts。之后正常使用nova服务,所有操作都正常执行。说明MQ的镜像模式可以支持nova的消息通信。
Case2:配置nova使用rabbit_hosts
此case意在观察MQ集群出现问题时nova的反应。同样配置RabbitMQ集群,配置nova.conf的rabbit_hosts=rabbit1:5672, rabbit2:5672。正常开启nova服务,观察到nova-X服务首先连接rabbit1服务,当关闭rabbit1服务后,连接断开,再次尝试连接rabbit1,失败后开始尝试连接rabbit2,之后保持连接rabbit2并正常服务。说明nova可以自行判断MQ服务的状态,并且自动重连,可以在不部署Haproxy的情况下使用高可用MQ。
总结
havana nova对高可用RabbitMQ的支持比较好,基本可以满足高可用需求,对于RabbitMQ的集群既可以部署haproxy,也可以直接配置rabbit_hosts,让nova自动重连。从方便运维的角度出发,减少不必要的依赖,减少出问题的可能,所以建议直接使用nova的rabbit_hosts。

相关文章推荐
- (转)RabbitMQ学习之集群部署
- RabbitMQ学习之集群部署
- RabbitMQ学习之集群部署
- hadoop学习3-MapReduce的集群安装与部署
- 分布式系统学习:Hadoop集群部署(1)
- RabbitMQ (消息队列)专题学习01 RabbitMQ部署
- rabbitMQ集群部署
- RabbitMQ集群环境部署
- dubbo学习之dubbo管理控制台装配及集成zookeeper集群部署(1)
- RabbitMQ学习之集群镜像模式配置
- rabbitMQ集群部署以及集群之间同步
- 【Ceph学习之一】Centos7上部署Ceph存储集群以及CephFS的安装
- rabbitmq 学习-16 rabbitmq集群-1 介绍
- 高可用rabbitmq集群服务部署步骤
- 160328、rabbitMQ集群部署示例
- 非常不错的rabbitmq集群高可用部署
- C# Hadoop学习笔记(三)—集群部署结构
- Cloud Foundry 深入学习二 集群部署
- Spark Hadoop集群部署与Spark操作HDFS运行详解---Spark学习笔记10
- Ceph学习1——Ubuntu12.04手动安装Ceph&&部署Ceph集群