OSChina 的全文搜索设计说明 —— 索引过程
2014-11-12 18:28
78 查看
http://www.oschina.net/question/12_71591
言: OSChina 的搜索做得并不好,很久之前一直想在细节方面进行改造,一直也没什么好的思路。但作为整体的结构或许对大家还是有一些参考的价值,之前也分享过一些代码,这次主要是把整个模块的设计思路详细的介绍一下,本文要求了解 Lucene 的基本使用。
OSChina 使用的是全文搜索的技术,涉及到的开源软件包括 Lucene 和国产的 IKAnalyzer。谈到分词,有些人喜欢问,你怎么不用xxx呢?很不好意思,鄙人只用过和熟悉 IKAnalyzer ,所以选型的时候肯定考虑的是它。另外 IKAnalyzer 的作者就在 OSC 上,有什么问题也方便直接请教,请看之前 OSC 对 IKAnalyzer 的作者林良益的访谈。
以下内容来自百度百科:
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。
结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。
全文搜索技术的特点是:速度超快,但不及时,主要体现在刚发布的文章并不能马上搜到(这句话并不绝对,请勿纠结)。
一般全文搜索引擎都有自己独立的索引库,这个索引库跟数据库是完全隔离的,没有任何关系。Lucene 使用的是文件系统来存储索引库。当我们发布一篇文章时,这篇文章是存在于数据库中,需要通过 Lucene 提供的 API 将文章进行索引(Indexing),然后写到索引库中才能检索得到。
由于Web应用是一个多用户并发的系统,简单的说,同一个时间点可能有不止一个人在发帖,而 Lucene 的索引库支持并发读,但如果同时多人写入或者更新就会导致索引库被锁住(索引库目录下有名为 lock 文件),因此必须避免在发帖的时候同时更新索引库,一般的做法由一个独立的进程来负责索引的添加、删除和修改操作,这也就是我前面说的 “不及时” 的原因。
总结一下,如果要用 Lucene 来做全文搜索,必须注意的问题是:避免有多个线程、进程同时操作索引库,包括添加、修改和删除。
下图是一个 OSChina 全文搜索的基本结构:

由于 OSC 需要做全文搜索的内容有好几种,包括:软件、新闻、问答、代码、博客,目前这几种类型的文章都是使用独立的索引库存储(这也是我想改造的一个不足之一),为了统一索引过程,我定义了一个接口 —— SearchEnabled
?
而软件、帖子、新闻等对象对应的类必须实现 SearchEnabled 接口才能支持全文搜索。这个接口中的两个扩展方法 GetExtendValues() 和 GetExtendIndexValues() 是为了让 Bean 类能有更灵活的方式来提供索引数据,例如帖子里是包含了标签列表,这个标签本身并不是 Bean 类的一个属性,就可以通过这个方式来提供给索引器。而为什么这里有些方法是大写字母开头呢,这不符合 Java 的编码规范,这里主要是为了避免索引器把这个方法当成是 Java Bean 的 getter/setter 方法。
前面我们讲到了对索引的修改操作要独立到一个进程或者线程来处理,并保证是单实例的。OSChina 是通过一个单独的 Apache Ant 任务来执行这个索引过程,Ant 任务定义如下:
?
然后通过 Linux 下的 crontab 每隔五分钟运行一次 lucene_build 任务,这个任务对应的 Java 类是 net.oschina.search.LuceneUpdater 。这个类是负责增量的构建和更新索引,我们会在下面详细介绍。而另外一个任务是 lucene_init ,对应的类是 net.oschina.search.RebuildLuceneIndex,这相当于是对索引库进行初始化。它会读取传递进来的参数(也就是一些Bean的类名),然后实例化这个类,并调用 ListAfter 方法获取记录并构建索引。
这个 RebuildLuceneIndex 主要是用于手工执行的,有时候需要完全重构整个索引库,有时候需要从某个 id 开始构建索引等等,这是维护上的需要。
如何实现增量的索引?
索引的更改包括:添加、修改和删除,Lucene 没有修改的操作,修改等同于删除后重建。为了实现增量操作,OSChina 把所有的这些操作记录到一个专门的索引任务表中,表名 osc_lucene_tasks 结构如下:
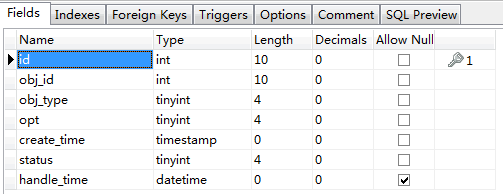
请大家不要再纠结什么 datetime 和 timestamp 的问题了,这不重要 :)
字段说明:
id -> 记录的唯一标识
obj_id -> 对象的编号,例如等同于软件的编号
obj_type -> 对象类型,例如软件的类型是1
opt -> 操作类型:添加、删除或者是修改
create_time -> 操作时间
status -> 处理状态
handle_time -> 处理的时间
当我发布一个帖子时,obj_id 值为帖子的编号;obj_type 值为帖子对应类型常量,这里是2;opt 值为 OPT_ADD 常量值;create_time 为发帖时间;status 值为0表示待处理;handle_time 值为空。
而 LuceneUpdater 这个类会由 Linux 下的 crontab 进程每 5 分钟调用一次,LuceneUpdater 启动后就扫描 osc_lucene_tasks 这个表中所有 status 为待处理的记录,然后根据 obj_id 和 obj_type 二者的值到对应的表中读取数据,并根据 opt 字段指定的值来决定是添加到索引库,还是从索引库中删除,又或者是更新索引库的操作。
LuceneUpdater 完整代码如下:
?
这就完成了索引的构建和增量更新的过程,而检索的操作就跟你做普通的 Lucene 检索没有什么两样。
言: OSChina 的搜索做得并不好,很久之前一直想在细节方面进行改造,一直也没什么好的思路。但作为整体的结构或许对大家还是有一些参考的价值,之前也分享过一些代码,这次主要是把整个模块的设计思路详细的介绍一下,本文要求了解 Lucene 的基本使用。
OSChina 使用的是全文搜索的技术,涉及到的开源软件包括 Lucene 和国产的 IKAnalyzer。谈到分词,有些人喜欢问,你怎么不用xxx呢?很不好意思,鄙人只用过和熟悉 IKAnalyzer ,所以选型的时候肯定考虑的是它。另外 IKAnalyzer 的作者就在 OSC 上,有什么问题也方便直接请教,请看之前 OSC 对 IKAnalyzer 的作者林良益的访谈。
以下内容来自百度百科:
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。
结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。
全文搜索技术的特点是:速度超快,但不及时,主要体现在刚发布的文章并不能马上搜到(这句话并不绝对,请勿纠结)。
一般全文搜索引擎都有自己独立的索引库,这个索引库跟数据库是完全隔离的,没有任何关系。Lucene 使用的是文件系统来存储索引库。当我们发布一篇文章时,这篇文章是存在于数据库中,需要通过 Lucene 提供的 API 将文章进行索引(Indexing),然后写到索引库中才能检索得到。
由于Web应用是一个多用户并发的系统,简单的说,同一个时间点可能有不止一个人在发帖,而 Lucene 的索引库支持并发读,但如果同时多人写入或者更新就会导致索引库被锁住(索引库目录下有名为 lock 文件),因此必须避免在发帖的时候同时更新索引库,一般的做法由一个独立的进程来负责索引的添加、删除和修改操作,这也就是我前面说的 “不及时” 的原因。
总结一下,如果要用 Lucene 来做全文搜索,必须注意的问题是:避免有多个线程、进程同时操作索引库,包括添加、修改和删除。
下图是一个 OSChina 全文搜索的基本结构:
由于 OSC 需要做全文搜索的内容有好几种,包括:软件、新闻、问答、代码、博客,目前这几种类型的文章都是使用独立的索引库存储(这也是我想改造的一个不足之一),为了统一索引过程,我定义了一个接口 —— SearchEnabled
?
前面我们讲到了对索引的修改操作要独立到一个进程或者线程来处理,并保证是单实例的。OSChina 是通过一个单独的 Apache Ant 任务来执行这个索引过程,Ant 任务定义如下:
?
这个 RebuildLuceneIndex 主要是用于手工执行的,有时候需要完全重构整个索引库,有时候需要从某个 id 开始构建索引等等,这是维护上的需要。
如何实现增量的索引?
索引的更改包括:添加、修改和删除,Lucene 没有修改的操作,修改等同于删除后重建。为了实现增量操作,OSChina 把所有的这些操作记录到一个专门的索引任务表中,表名 osc_lucene_tasks 结构如下:
请大家不要再纠结什么 datetime 和 timestamp 的问题了,这不重要 :)
字段说明:
id -> 记录的唯一标识
obj_id -> 对象的编号,例如等同于软件的编号
obj_type -> 对象类型,例如软件的类型是1
opt -> 操作类型:添加、删除或者是修改
create_time -> 操作时间
status -> 处理状态
handle_time -> 处理的时间
当我发布一个帖子时,obj_id 值为帖子的编号;obj_type 值为帖子对应类型常量,这里是2;opt 值为 OPT_ADD 常量值;create_time 为发帖时间;status 值为0表示待处理;handle_time 值为空。
而 LuceneUpdater 这个类会由 Linux 下的 crontab 进程每 5 分钟调用一次,LuceneUpdater 启动后就扫描 osc_lucene_tasks 这个表中所有 status 为待处理的记录,然后根据 obj_id 和 obj_type 二者的值到对应的表中读取数据,并根据 opt 字段指定的值来决定是添加到索引库,还是从索引库中删除,又或者是更新索引库的操作。
LuceneUpdater 完整代码如下:
?

相关文章推荐
- OSChina 的全文搜索设计说明 —— 索引过程
- OSChina 的全文搜索设计说明 —— 索引过程
- 避免因索引制作过程中出现错误而影响搜索
- SQL Server 2005全文索引的过程
- lucene 3.4索引和搜索过程中核心类
- OSChina 用户动态设计说明
- 超轻量级全文搜索框架的设计和实现 (1)
- 分布式搜索Elasticsearch源码分析之二------索引过程源码概要分析
- 转一研究Mysql全文索引的好文,对于小站做简单搜索特有用
- HubbleDotNet 开源全文搜索数据库项目--内存索引
- 建立SQL全文索引提升搜索速度
- 全文索引在SQL200和SQL2005的简单建立过程及用法
- 数据库是否使用外键,及视图,索引,存储过程的一些说明(zz)
- 索引过程和搜索过程
- lucene 3.4索引和搜索过程中核心类
- 针对Lucene 建立索引过程与搜索过程耗费时间的矛盾一点思路
- HubbleDotNet 开源全文搜索数据库项目--数据表的数据类型和索引类型
- HubbleDotNet 开源全文搜索数据库项目--为数据库现有表或视图建立全文索引(三) 多表关联全文索引模式
- 开源:完全自主研发搜索引擎1.0源代码及说明,单机400万网页全文索引,任意50词以内的检索不超过 20毫秒
- Lucene 索引和搜索过程