python字符串编码问题
2014-09-05 21:28
323 查看
问题
关注这个问题是源于python程序在调用raw_input()时的出错提示:unicodeencodeerror 'ascii' codec can't encode characters in position(python 2.7.x版本,据说python3不会有这样的问题)
程序如下:
# -*- coding: utf-8 -*-
raw_input(u'输入')输出

但是对print语句,却没有问题
# -*- coding: utf-8 -*-
print u'输入'
原因可能是raw_input函数在接受参数u'输入'时,采用的是ascii解码方式,而首行注释 coding: utf-8,只是声明.py文件在读取的时候的解码方式,对raw_input并不起作用。
解决方法:
在python27目录下的Lib目录中的site.py文件
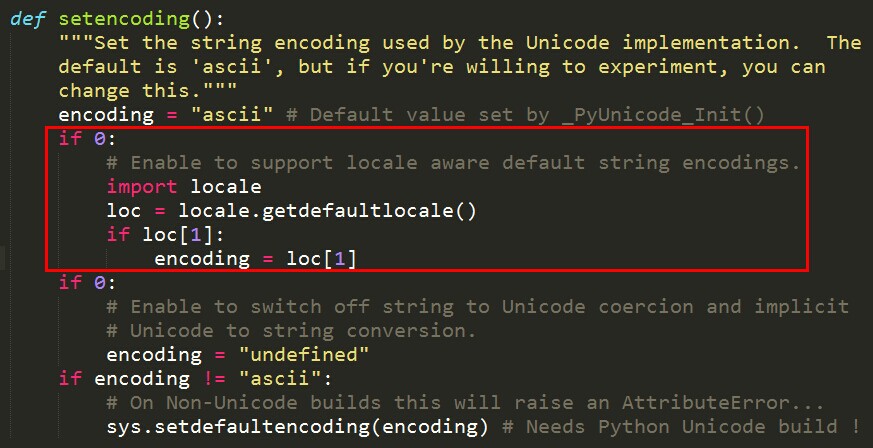
修改为
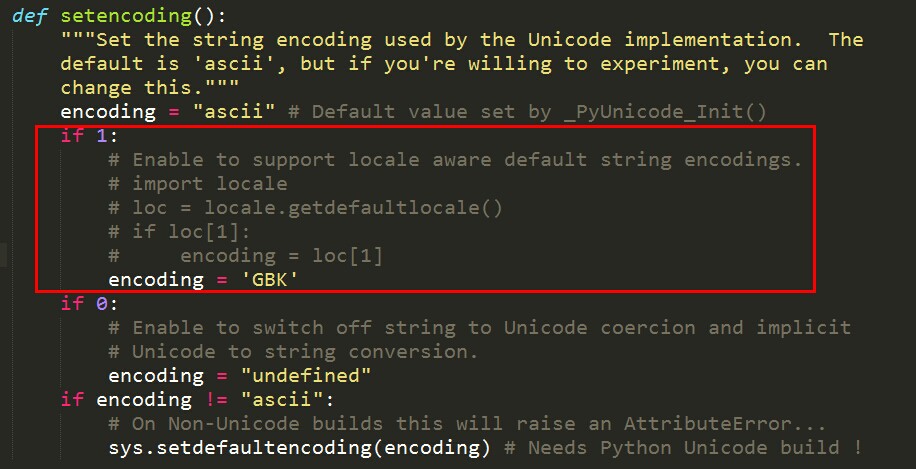
查了网上很多种方法,即使解决了异常,但是会引起输出乱码的问题。上面这种方法亲测有效,如果哪位亲按照我这种方法出现了问题,请告诉我(*^__^*)。
原因
解决完问题之后,让我们来分析一下原因。因为自己是python的初学者,也只能是猜测一下,如果有不对的地方,请指出。
原因可能是raw_input函数在调用的时候,它自己可能直接或者间接的调用了上图中的setencoding函数def setencoding():
"""Set the string encoding used by the Unicode implementation. The
default is 'ascii', but if you're willing to experiment, you can
change this."""
encoding = "ascii" # Default value set by _PyUnicode_Init()
if 0:
Enable to support locale aware default string encodings.
import locale
loc = locale.getdefaultlocale()
if loc[1]:
encoding = loc[1]
if 0:
# Enable to switch off string to Unicode coercion and implicit
# Unicode to string conversion.
encoding = "undefined"
if encoding != "ascii":
# On Non-Unicode builds this will raise an AttributeError...
sys.setdefaultencoding(encoding) # Needs Python Unicode build !而这个函数在第五行,设置了 encoding=ascii,这就导致了raw_input函数在对参数 u'输入',按照ascii码来处理,由于在ascii码表中没有匹配到字符,便抛出异常。解决方式就是将encoding设置为中文编码‘GBK’,这样对参数 u'输入'
就能正确处理了。将‘GBK’修改为‘CP936’也是正确的。更多原因以及字符编码,关于字符编码,请参考:点这里。
补充
在上面加超链接的参考资料中,提到这么一个有趣的事情:
你可能听说过UTF-8不需要BOM,这种说法是不对的,只是绝大多数编辑器在没有BOM时都是以UTF-8作为默认编码读取。即使是保存时默认使用ANSI(MBCS)的记事本,在读取文件时也是先使用UTF-8测试编码,如果可以成功解码,则使用UTF-8解码。记事本这个别扭的做法造成了一个BUG:如果你新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成"汉a",你不妨试试
:)
让我们用python来探究一下为什么:
新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成""
我们在保存记事本文件时,采用的编码方式为:ANSI。仔细阅读了超链接中的文章,就知道在window简体中文系统中,ANSI指的就是GBK编码。用python程序查看一下“”和汉a的GBK编码和utf-8编码:
# -*- coding: utf-8 -*-
u1 = u'汉a'
print repr(u1)
print repr(u1.encode('utf-8'))
u2 = u'姹塧'
print repr(u2)
print repr(u2.encode('gbk'))
输出如下
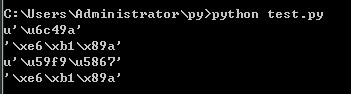
可以看到 汉a 的utf-8编码和 姹塧
的GBK编码是一样的。
这么一来,原因就显而易见了,记事本在保存 姹塧 时,按照ANSI也就是GBK编码来保存,在打开文件时,先按照utf-8进行测试编码,如果可以解码,则按照utf-8解码。
再探讨一下u'字符串'和'字符串'的区别。
u表示后面跟的字符串按照Unicode编码,而不加u表示字符串按照类似C语言中char类型,一个字节一个字节的储存编码。用程序验证,区别如下# -*- coding: utf-8 -*-
u1 = '汉'
u2 = u'汉'
print repr(u1)
print repr(u2)<pre name="code" class="python">print len(u1)
print len(u2)
输出如下:

从程序的输出可以体会到,它们的却别类似于C/C++中的char和wchar_t两种数据类型的区别。
关注这个问题是源于python程序在调用raw_input()时的出错提示:unicodeencodeerror 'ascii' codec can't encode characters in position(python 2.7.x版本,据说python3不会有这样的问题)
程序如下:
# -*- coding: utf-8 -*-
raw_input(u'输入')输出
但是对print语句,却没有问题
# -*- coding: utf-8 -*-
print u'输入'
原因可能是raw_input函数在接受参数u'输入'时,采用的是ascii解码方式,而首行注释 coding: utf-8,只是声明.py文件在读取的时候的解码方式,对raw_input并不起作用。
解决方法:
在python27目录下的Lib目录中的site.py文件
修改为
查了网上很多种方法,即使解决了异常,但是会引起输出乱码的问题。上面这种方法亲测有效,如果哪位亲按照我这种方法出现了问题,请告诉我(*^__^*)。
原因
解决完问题之后,让我们来分析一下原因。因为自己是python的初学者,也只能是猜测一下,如果有不对的地方,请指出。
原因可能是raw_input函数在调用的时候,它自己可能直接或者间接的调用了上图中的setencoding函数def setencoding():
"""Set the string encoding used by the Unicode implementation. The
default is 'ascii', but if you're willing to experiment, you can
change this."""
encoding = "ascii" # Default value set by _PyUnicode_Init()
if 0:
Enable to support locale aware default string encodings.
import locale
loc = locale.getdefaultlocale()
if loc[1]:
encoding = loc[1]
if 0:
# Enable to switch off string to Unicode coercion and implicit
# Unicode to string conversion.
encoding = "undefined"
if encoding != "ascii":
# On Non-Unicode builds this will raise an AttributeError...
sys.setdefaultencoding(encoding) # Needs Python Unicode build !而这个函数在第五行,设置了 encoding=ascii,这就导致了raw_input函数在对参数 u'输入',按照ascii码来处理,由于在ascii码表中没有匹配到字符,便抛出异常。解决方式就是将encoding设置为中文编码‘GBK’,这样对参数 u'输入'
就能正确处理了。将‘GBK’修改为‘CP936’也是正确的。更多原因以及字符编码,关于字符编码,请参考:点这里。
补充
在上面加超链接的参考资料中,提到这么一个有趣的事情:
你可能听说过UTF-8不需要BOM,这种说法是不对的,只是绝大多数编辑器在没有BOM时都是以UTF-8作为默认编码读取。即使是保存时默认使用ANSI(MBCS)的记事本,在读取文件时也是先使用UTF-8测试编码,如果可以成功解码,则使用UTF-8解码。记事本这个别扭的做法造成了一个BUG:如果你新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成"汉a",你不妨试试
:)
让我们用python来探究一下为什么:
新建文本文件并输入"姹塧"然后使用ANSI(MBCS)保存,再打开就会变成""
我们在保存记事本文件时,采用的编码方式为:ANSI。仔细阅读了超链接中的文章,就知道在window简体中文系统中,ANSI指的就是GBK编码。用python程序查看一下“”和汉a的GBK编码和utf-8编码:
# -*- coding: utf-8 -*-
u1 = u'汉a'
print repr(u1)
print repr(u1.encode('utf-8'))
u2 = u'姹塧'
print repr(u2)
print repr(u2.encode('gbk'))
输出如下
可以看到 汉a 的utf-8编码和 姹塧
的GBK编码是一样的。
这么一来,原因就显而易见了,记事本在保存 姹塧 时,按照ANSI也就是GBK编码来保存,在打开文件时,先按照utf-8进行测试编码,如果可以解码,则按照utf-8解码。
再探讨一下u'字符串'和'字符串'的区别。
u表示后面跟的字符串按照Unicode编码,而不加u表示字符串按照类似C语言中char类型,一个字节一个字节的储存编码。用程序验证,区别如下# -*- coding: utf-8 -*-
u1 = '汉'
u2 = u'汉'
print repr(u1)
print repr(u2)<pre name="code" class="python">print len(u1)
print len(u2)
输出如下:
从程序的输出可以体会到,它们的却别类似于C/C++中的char和wchar_t两种数据类型的区别。

相关文章推荐
- 8.python中字符串的编码和解码问题——decode/encode
- python 2.7的字符串编码问题
- Python中的字符串与字符编码:编码和转换问题
- python字符串拼接编码问题
- Python中的字符串与字符编码:编码和转换问题
- 8.python中字符串的编码和解码问题——decode/encode
- Python学习笔记,5,字符串和编码问题
- python3 中字符串编码问题
- python3与python2的字符串编码问题
- python:字符串编码问题
- python字符串编码常见问题
- Python字符串的encode与decode研究心得乱码问题解决方法(很多的编码问题都可以从此得出答案)
- Python字符串编码+MySQLdb中的中文字符问题
- Python中文编码问题(字符串前面加'u')
- python字符串编码问题
- 【python】字符串编码问题
- Python字符串的编码问题
- Windows下Python字符串编码问题
- Python2和Python3中的字符串编码问题解决
- python3的字符串编码问题