基本正则表达式和文本处理工具之grep、egrep和fgrep
2014-08-28 00:43
726 查看
基本正则表达式和文本处理工具之grep、egrep和fgrep
Grep(global search regular expression and print out the line全局搜索正则表达式并把行打印出来),是一种强大的文本搜索工具,egrep和fgrep的命令跟grep只有很少的差别,linux使用的是GNU版本的grep,功能非常强大,可以通过-G,-E,-F命令选项来使用egrep和fgrep的功能,grep的工作方式为在一个或多个文件中搜索字符串模板,如果模板包括空格则必须被引用,模板后的所有字符串被看做文件名,搜索的结果被送到屏幕,不影响元文件内容,grep搜索成功返回值为0,搜索不成功返回值为1,如果搜做的文件不存在则返回值为2,因此grep可以用于脚本来进行一些自动化的文本处理工作。
Grep常用参数:
-i:忽略大小写
-v:取反,即得到的结果与设置的要求是相反的
-n:输出结果时候显示行号
常用的基本在正则表达式:
^ 行首
$ 行末
[] 匹配指定的字符
[^] 匹配指定以外的字符
\< 单词首
\> 单词尾
\(a,\)..\n 分组并引用
^$ 空白行
[0-9],[[:digit:]] 任意数字
[a-z],[[:lower:]] 任意小写字母
[A-Z],[[:upper:]] 任意大写字母
[[:alpha:]] 所有的大小写字母,全行匹配
[[:alnum:]] 所有的大小写字母和数字
[[:space:]] 所有的空白字符
[[:punct:]] 所有的标点符号
* 匹配其前面的字符0次或任意次
| 或,比如a|b
.* 匹配任意长度的任意字符
\? 匹配之前的字符0次或一次
\{1\} 精确匹配多少次
\{1,\} 最少匹配多少次
\{0,m\} 最多匹配第三次
\{n,m\} 匹配n到m次
gt 大于
lt 小于
ge 大于等于
le 小于等于
ne 不等于
eq 等于
$0 脚本本身
$1 脚本第一个参数
$*,$@ 引用的所有参数
$# 位置参数的格式,多少行
分组和引用:字符分组以它们的左括号的出现顺序来排序,例如在表达式((1)(2(3))),有四个分组,第0组永远表示表达式本:
1、((1)(2(3)))
2、(1)
3、(2(3))
4、(3)
一、字符匹配:
1、. 用于匹配任意的单个字符,必须要有这个字符,固定.的位置匹配结果
[root@localhost ~]# grep 'ro.t' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
2、[] 匹配里面的任意单个字符,匹配全行
[root@localhost ~]# grep [wp] /etc/fstab
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
UUID=16f1df10-ed2b-488b-9086-a48c60ab9ebe swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
proc /proc proc defaults 0 0
/dev/cdrom /var/ftp/pub/ iso9660 defaults,ro,loop 0 0
3、[0-9],[[:digit:]]表示匹配从0-9其中的任意一个数字,全行匹配
[root@localhost ~]# grep [[:digit:]] 1.txt 1
64
676
4、[a-z],[[:lower:]] 匹配a-z任意一个小写字母,整行匹配
[root@localhost ~]# grep [ae-z] 1.txt #匹配字母a和e到z,把b和c去除
hI
hIlucy
asdxx
5、[A-Z],[[:upper:]] 匹配任意一个大写字母,全行匹配
[root@localhost ~]# grep [[:upper:]] 1.txt
HI
hIlucy
6、[[:alpha:]] 所有的大小写字母,全行匹配
[root@localhost ~]# grep [[:alpha:]] 1.txt
hi
asdxx
2w
7、[[:alnum:]] 所有的数字和大小写字母,全行匹配
[root@localhost ~]# grep [[:alnum:]] 1.txt
hi
HI
hIlucy
1
2fg
8、[[:space:]] 所以的空白字符,全行匹配
[root@localhost ~]# grep [[:space:]] 1.txt
asdxx
]
1 2
asd
9、[[:punct:]] 匹配所以的标点符号,全行匹配
[root@localhost ~]# grep [[:punct:]] 1.txt
,,
]
[][
1.2
二:次数匹配,用来匹配字符出现的字数
1、*匹配*前面的那一个字符没有出现或者出现任意次,本例代表2没出现或出现多次,即1开头,1后面可以跟2,也可以不跟2,即使2后面还有字符,只有匹配到第一个1就算匹配到,而显示出来,所以其匹配到要么两个相同字符,要么没有
[root@localhost ~]# grep '12*' 1.txt
1
1223
111
w1
i12
1.2
2、.*匹配从.开始包含.在内的0或任意次数,本例为以12为开头,后面跟任意字符任意次数,即指定12必须匹配,与*最大的不同是.*往后匹配字符,后面有没有字符都匹配,而*则先往前匹配一位字符,其前面的一位字符如能匹配就出现两个同样字符,如果不能匹配就把前面字符取消,相比较之下*匹配的范围更大
[root@localhost ~]# grep '12*1' 1.txt
12221
111
3、\? 匹配前面的字符0次或一次,本例匹配12后面的2,有或者有一次即可,与*最大的区别是\?同一个字符最多连续出现两次,而*可以连续出现无数次
[root@localhost ~]# grep '12\?1' 1.txt
111
4、\{m\};匹配其前面的字符m次,需完成匹配次数
[root@localhost ~]# grep --color=auto '12\{3\}' 1.txt
12221
12222221
5、\{m,\}:匹配前面的字符至少m次
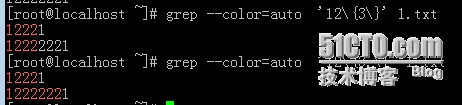
6、\{m,n}:匹配前面的字符m-n次,如本例匹配前面的2的次数为2次、3次、4次

7、\{0,m\}\ 匹配前面的字符至多m次,即包含最对次以内的0次以上的所有次数
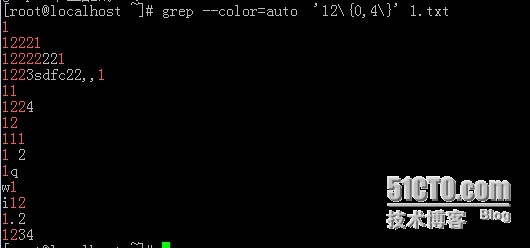
8、匹配以R1r开头,32结尾,中间间隔任意两个字符串的组合结果

三:位置锚定,即指定要匹配的字符串在行中的具体位置,比如在一行的首部、中间、或者最后的位置
1、^指定匹配的字符串位置在行首

2、$指定匹配的字符串位置在行尾

3、^$ 指定匹配的字符串为空白行,后面的wc –l为统计行数,即共有96个空白行

4、\< 指定匹配的字符串的词首

5、\>指定匹配的字符串的词尾

即指定词首又指定词尾,等于把一个单词固定了

6、\(ab\)*xy\1 分组和引用,\1为引用的从左边开始的第几个括号里面所匹配到内容

本文出自 “Linux” 博客,请务必保留此出处http://zhangshijie.blog.51cto.com/806066/1545945
Grep(global search regular expression and print out the line全局搜索正则表达式并把行打印出来),是一种强大的文本搜索工具,egrep和fgrep的命令跟grep只有很少的差别,linux使用的是GNU版本的grep,功能非常强大,可以通过-G,-E,-F命令选项来使用egrep和fgrep的功能,grep的工作方式为在一个或多个文件中搜索字符串模板,如果模板包括空格则必须被引用,模板后的所有字符串被看做文件名,搜索的结果被送到屏幕,不影响元文件内容,grep搜索成功返回值为0,搜索不成功返回值为1,如果搜做的文件不存在则返回值为2,因此grep可以用于脚本来进行一些自动化的文本处理工作。
Grep常用参数:
-i:忽略大小写
-v:取反,即得到的结果与设置的要求是相反的
-n:输出结果时候显示行号
常用的基本在正则表达式:
^ 行首
$ 行末
[] 匹配指定的字符
[^] 匹配指定以外的字符
\< 单词首
\> 单词尾
\(a,\)..\n 分组并引用
^$ 空白行
[0-9],[[:digit:]] 任意数字
[a-z],[[:lower:]] 任意小写字母
[A-Z],[[:upper:]] 任意大写字母
[[:alpha:]] 所有的大小写字母,全行匹配
[[:alnum:]] 所有的大小写字母和数字
[[:space:]] 所有的空白字符
[[:punct:]] 所有的标点符号
* 匹配其前面的字符0次或任意次
| 或,比如a|b
.* 匹配任意长度的任意字符
\? 匹配之前的字符0次或一次
\{1\} 精确匹配多少次
\{1,\} 最少匹配多少次
\{0,m\} 最多匹配第三次
\{n,m\} 匹配n到m次
gt 大于
lt 小于
ge 大于等于
le 小于等于
ne 不等于
eq 等于
$0 脚本本身
$1 脚本第一个参数
$*,$@ 引用的所有参数
$# 位置参数的格式,多少行
分组和引用:字符分组以它们的左括号的出现顺序来排序,例如在表达式((1)(2(3))),有四个分组,第0组永远表示表达式本:
1、((1)(2(3)))
2、(1)
3、(2(3))
4、(3)
一、字符匹配:
1、. 用于匹配任意的单个字符,必须要有这个字符,固定.的位置匹配结果
[root@localhost ~]# grep 'ro.t' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
2、[] 匹配里面的任意单个字符,匹配全行
[root@localhost ~]# grep [wp] /etc/fstab
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
UUID=16f1df10-ed2b-488b-9086-a48c60ab9ebe swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
proc /proc proc defaults 0 0
/dev/cdrom /var/ftp/pub/ iso9660 defaults,ro,loop 0 0
3、[0-9],[[:digit:]]表示匹配从0-9其中的任意一个数字,全行匹配
[root@localhost ~]# grep [[:digit:]] 1.txt 1
64
676
4、[a-z],[[:lower:]] 匹配a-z任意一个小写字母,整行匹配
[root@localhost ~]# grep [ae-z] 1.txt #匹配字母a和e到z,把b和c去除
hI
hIlucy
asdxx
5、[A-Z],[[:upper:]] 匹配任意一个大写字母,全行匹配
[root@localhost ~]# grep [[:upper:]] 1.txt
HI
hIlucy
6、[[:alpha:]] 所有的大小写字母,全行匹配
[root@localhost ~]# grep [[:alpha:]] 1.txt
hi
asdxx
2w
7、[[:alnum:]] 所有的数字和大小写字母,全行匹配
[root@localhost ~]# grep [[:alnum:]] 1.txt
hi
HI
hIlucy
1
2fg
8、[[:space:]] 所以的空白字符,全行匹配
[root@localhost ~]# grep [[:space:]] 1.txt
asdxx
]
1 2
asd
9、[[:punct:]] 匹配所以的标点符号,全行匹配
[root@localhost ~]# grep [[:punct:]] 1.txt
,,
]
[][
1.2
二:次数匹配,用来匹配字符出现的字数
1、*匹配*前面的那一个字符没有出现或者出现任意次,本例代表2没出现或出现多次,即1开头,1后面可以跟2,也可以不跟2,即使2后面还有字符,只有匹配到第一个1就算匹配到,而显示出来,所以其匹配到要么两个相同字符,要么没有
[root@localhost ~]# grep '12*' 1.txt
1
1223
111
w1
i12
1.2
2、.*匹配从.开始包含.在内的0或任意次数,本例为以12为开头,后面跟任意字符任意次数,即指定12必须匹配,与*最大的不同是.*往后匹配字符,后面有没有字符都匹配,而*则先往前匹配一位字符,其前面的一位字符如能匹配就出现两个同样字符,如果不能匹配就把前面字符取消,相比较之下*匹配的范围更大
[root@localhost ~]# grep '12*1' 1.txt
12221
111
3、\? 匹配前面的字符0次或一次,本例匹配12后面的2,有或者有一次即可,与*最大的区别是\?同一个字符最多连续出现两次,而*可以连续出现无数次
[root@localhost ~]# grep '12\?1' 1.txt
111
4、\{m\};匹配其前面的字符m次,需完成匹配次数
[root@localhost ~]# grep --color=auto '12\{3\}' 1.txt
12221
12222221
5、\{m,\}:匹配前面的字符至少m次
6、\{m,n}:匹配前面的字符m-n次,如本例匹配前面的2的次数为2次、3次、4次
7、\{0,m\}\ 匹配前面的字符至多m次,即包含最对次以内的0次以上的所有次数
8、匹配以R1r开头,32结尾,中间间隔任意两个字符串的组合结果
三:位置锚定,即指定要匹配的字符串在行中的具体位置,比如在一行的首部、中间、或者最后的位置
1、^指定匹配的字符串位置在行首
2、$指定匹配的字符串位置在行尾
3、^$ 指定匹配的字符串为空白行,后面的wc –l为统计行数,即共有96个空白行
4、\< 指定匹配的字符串的词首
5、\>指定匹配的字符串的词尾
即指定词首又指定词尾,等于把一个单词固定了
6、\(ab\)*xy\1 分组和引用,\1为引用的从左边开始的第几个括号里面所匹配到内容
本文出自 “Linux” 博客,请务必保留此出处http://zhangshijie.blog.51cto.com/806066/1545945

相关文章推荐
- 【Linux相识相知】文本处理工具之grep\egrep\fgrep及正则表达式
- 文本搜索之grep、fgrep、egrep以及正则表达式
- Linux 文本处理,文本工具,查看,分析,统计文本文件,grep,正则表达式
- Linux 文本处理工具、grep、正则表达式
- Linux正则表达式的使用和基本命令grep、egrep、fgrep的用法
- Linux的文本处理工具及grep正则表达式的使用
- 文本处理——grep,egrep,fgrep与正则
- 关于 文本处理工具、正则表达式、grep 的简单举例
- linux基本命令grep egrep fgrep用法以及正则表达式
- 字符及文本处理之正则表达式:Linux/Unix工具与正则表达式的POSIX规范
- 牛刀小试之 ---文本处理工具之 grep egrep用法
- grep, egrep, 基本正则表达式及扩展表达式学习及用法
- grep, egrep, 基本正则表达式及扩展表达式;
- 文本查找工具grep,正则表达式,扩展表达式
- 20150827-Linux grep文本过滤工具及正则表达式
- bash 正则表达式,文本文件查找 grep egrep
- 文本查找工具grep的使用(含正则表达式用法)
- 文本搜索必学命令-grep egrep fgrep用法以及正则表达式
- linux 中的文本处理工具,grep,egrep
- 字符及文本处理之二:grep及正则表达式详解