正则表达式
2014-08-20 18:09
274 查看
修饰符
^ 表示匹配到行首eg: grep -n '^a' file
在file中匹配以a开头的行;
[^]表示不匹配字符集中的内容
eg:grep -n '[^a]' file 在file中匹配不含有a的行;
$ 表示匹配到行未
eg: grep -n 'a$' file 在file中匹配以a结尾的行;
[abc] 匹配abc中的任意一个
eg:grep -n '^[abc]' 匹配以a,b,或c,开头的行;
* 表示匹配前一个字符0~n次
. 表示匹配任意一个字符
+ 表示匹配前一个字符1~n次
? 表示匹配前一个字符0~1次
\{n\} 表示匹配前面的字符n次
\{n,\} 表示匹配前一个字符至少n次
\{n,m\} 表示匹配前一个字符n~m次
eg:grep -n ‘go*d’ 匹配god,good,goood...
转义字符
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如,''er\b'' 可以匹配"never" 中的''er'',但不能匹配 "verb"中的 ''er''。\B 匹配非单词边界。''er\B''能匹配"verb"中的''er'',但不能匹配"never"中的 ''er''
\w 匹配包括下划线的任何单词字符。等价于''[A-Za-z0-9]''。
\W 匹配任何非单词字符。等价于''[^A-Za-z0-9]''。
\d 匹配一个数字字符。等价于[0-9]。
\D 匹配一个非数字字符。等价于[^0-9]。
\f 匹配一个换页符。等价于\x0c和\cL。
\n 匹配一个换行符。等价于\x0a和\cJ。
\r 匹配一个回车符。等价于\x0d和\cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。
\S 匹配任何非空白字符。等价于[^\f\n\r\t\v]。
\t 匹配一个制表符。等价于\x09 和 \cI。
\v 匹配一个垂直制表符。等价于\x0b和\cK。
POSIX字符集
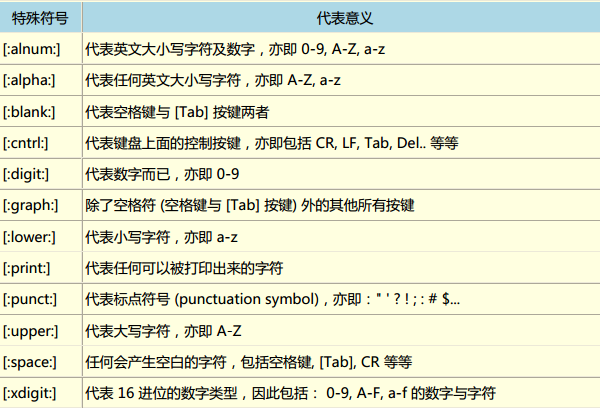
eg;grep -n '[[:digit:]]' 匹配所有含有数字的行;

相关文章推荐
- 1小时教你学会正则表达式
- javascript正则表达式
- javascript 手机号码正则表达式验证函数
- 正则表达式判断号码靓号类型
- Python正则表达式指南
- 如何用正则表达式实现规定用户输入密码的格式为:(长度6到18个字符,不能全为重复字母,或者连续字母)
- 【python】正则表达式-group和group的区别
- 常见的 JQuery 正则表达式以及验证方法
- 常用正则表达式
- 常用正则表达式 整理篇
- 揭开正则表达式的神秘面纱
- Python用正则表达式判断中文字符
- JAVA 正则表达式:使用group方法计算匹配到的字符串个数
- JAVA正则表达式4种常用的功能
- 正则表达式
- 正则表达式1
- 正则表达式
- 常用正则表达式大全
- iOS 由中英文数字组成 正则表达式
- java代码中邮箱正则表达式和js版