二叉搜索树;二叉查找树;二叉排序树;Binary Search Tree
2014-07-12 21:16
288 查看
http://blog.csdn.net/jiqiren007/article/details/6534810
Binary Search Tree,中文翻译为二叉搜索树、二叉查找树或者二叉排序树。简称为BST
二叉搜索树是一种很基础的树,后续的AVL、红黑树等都是在此基础上增加了一些其他限制条件形成的。
定义与树的定义是类似的,也是一个递归的定义:
1、要么是一棵空树
2、如果不为空,那么其左子树节点的值都小于根节点的值;右子树节点的值都大于根节点的值
3、其左右子树也是二叉搜索树
在算法导论中的定义:

下图中是BST的两个例子:

其中(b)图中的树是很不平衡的(所谓不平衡是值左右子树的高度差比较大)
BST在数据结构中占有很重要的地位,一些高级树结构都是其的变种,例如AVL树、红黑树等,因此理解BST对于后续树结构的学习有很好的作用。同时利用BST可以进行排序,称为二叉排序,也是很重要的一种思想。
在BST中有下列操作:
1、在树中插入一个节点:insert(tree *root, datatype t)
2、在将树中的某个节点删除: remove(tree *root, datatype t);
3、查找树中值最大/小的节点:find_max(tree root) / find_min(tree root);
4、查找树中的某个节点:search_tree(tree root, datatype t);
当然作为二叉树,还有对BST的各种遍历,主要是中序遍历,对BST的中序遍历(In-Order Traversal)其实就是二叉搜索、二叉排序的实现。
上面的几个操作中最复杂的一个操作是删除树中的节点,后面会详细介绍。
3. BST的具体操作实现
下面就根据BST的定义和各个操作的含义,实现BST的相应操作。
1、插入操作insert(tree *root, datatype t)
插入操作是在指定的BST中插入一个节点,该节点的数据域为t。同时插入节点后需要保证BST仍然满足二叉搜索树的定义
若二叉树为空,则首先单独生成根结点;若二叉树不为空,新插入的结点总是叶子结点。
插入操作的大概过程如下:
将root->data 与t进行比较,如果t < root->data,那么递归将t插入到root->lchild; 否则将t插入到root->rchild中。如果root是空的话,则新建一个节点。
上面是插入操作的一个简单实现,在图形化中的二叉搜索树的展示如下:

这里是插入节点13
从上面实现可以知道,插入操作的时间复杂度是O(lgn),其中n是节点的个数,也就是时间复杂度是树的高度。当然在最坏情况下时间复杂度是O(n)。(当插入的数列已经排好序时,生成的二叉树及其不平衡,只有一个分支,而且深度为插入的个数)
2、二叉搜索树的删除操作
在介绍完二叉搜索树的插入操作后,下面介绍下二叉搜索树中最复杂的操作,删除节点操作remove(tree *root, datatype t).二叉搜索树的删除操作是相对要复杂的,这是因为删除操作有多种情况需要考虑,下面分别一一介绍:
假设要删除的节点是p,该节点的父节点是q,那么对p有下面的一些考察:
p和q的关系如下图所示:其中p的两个子节点用虚线表示,表示可能有也可能没有子节点;同时p也有可能是q的右孩子

针对上面的描述,可能有下面的几种情况需要考虑
a、如果p节点没有孩子节点,也就是说p节点是叶子节点,那么直接删除p对二叉搜索树是没有影响的,这样的情况下可以直接将q相应的子节点指针设置为空,然后free掉p
b、如果p的孩子节点有一个为空,例如左孩子为空或者右孩子为空。
对于这样的情况也可以分成两种讨论
同理
c、p的左右孩子都不为空,这是最复杂的一种情况
在这种情况下需要考虑的比较多,如果要删除p节点的话,需要找到p的后继者(p的后继者肯定比p大,但是比其他数都小;此时p的后继者肯定是p的右子树中最小的一个,因为p有右孩子),然后将其放在p的位置,这样才能保证维持BST的性质。因此这种情况下就可以先找到p节点的后继者,然后将其和p进行交换,然后将交换后的节点删除。
下图是《算法导论》中删除节点的三种情况描述:



其中z节点是要删除的节点。(c)中的y节点是z的后继者
对于p的左右孩子都不为空的伪代码如下:
node *successor; //指向p的后继者
successor = find_min(p->rchild); //找到p的后继者y
p->data = successor->data; //将后继者y的值copy到p的数据域中
successor->parent->lchild = successor->rchild;//这里successor一定是其父节点的左孩子,因为如果他是父节点的右孩子的话,那么p的后继者就不是successor了,而应该是successor的parent了,因为successor的parent比successor小。这是这条语句左边的原因;对于右边来说,因为successor是p的后继者,那么successor一定是没有左孩子的,如果有的话,p的后继者就不是successor了,而是successor的左孩子了,因此successor至多有一个右孩子。这是对这条语句的解释。
操作完后就可以将successor释放掉了。
这些基本就是二叉搜索树的操作了,比较复杂的是插入和删除操作。
Binary Search Tree,中文翻译为二叉搜索树、二叉查找树或者二叉排序树。简称为BST
二叉搜索树是一种很基础的树,后续的AVL、红黑树等都是在此基础上增加了一些其他限制条件形成的。
1. 二叉搜索树的定义
定义与树的定义是类似的,也是一个递归的定义:1、要么是一棵空树
2、如果不为空,那么其左子树节点的值都小于根节点的值;右子树节点的值都大于根节点的值
3、其左右子树也是二叉搜索树
在算法导论中的定义:
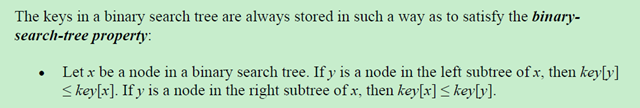
下图中是BST的两个例子:
其中(b)图中的树是很不平衡的(所谓不平衡是值左右子树的高度差比较大)
BST在数据结构中占有很重要的地位,一些高级树结构都是其的变种,例如AVL树、红黑树等,因此理解BST对于后续树结构的学习有很好的作用。同时利用BST可以进行排序,称为二叉排序,也是很重要的一种思想。
2. 二叉搜索树的操作定义
在BST中有下列操作:1、在树中插入一个节点:insert(tree *root, datatype t)
2、在将树中的某个节点删除: remove(tree *root, datatype t);
3、查找树中值最大/小的节点:find_max(tree root) / find_min(tree root);
4、查找树中的某个节点:search_tree(tree root, datatype t);
当然作为二叉树,还有对BST的各种遍历,主要是中序遍历,对BST的中序遍历(In-Order Traversal)其实就是二叉搜索、二叉排序的实现。
上面的几个操作中最复杂的一个操作是删除树中的节点,后面会详细介绍。
3. BST的具体操作实现
typedef struct node_t
{
<span style="white-space:pre"> </span>datatype data;
<span style="white-space:pre"> </span>struct node_t *lchild, *rchild;
}node, *tree;下面就根据BST的定义和各个操作的含义,实现BST的相应操作。
1、插入操作insert(tree *root, datatype t)
插入操作是在指定的BST中插入一个节点,该节点的数据域为t。同时插入节点后需要保证BST仍然满足二叉搜索树的定义
若二叉树为空,则首先单独生成根结点;若二叉树不为空,新插入的结点总是叶子结点。
插入操作的大概过程如下:
将root->data 与t进行比较,如果t < root->data,那么递归将t插入到root->lchild; 否则将t插入到root->rchild中。如果root是空的话,则新建一个节点。
void insert(tree *root, node *t)
{
if(*root == NULL)
{
<span style="white-space:pre"> </span>*root =t;
<span style="white-space:pre"> </span>return;
}
if(t->data < temp->data) //左子树
{
<span style="white-space:pre"> </span>insert(&((*root)->lchid), t);
}
else //插入到右子树
{
<span style="white-space:pre"> </span>insert(&((*root)->rchild), t);
}
}上面是插入操作的一个简单实现,在图形化中的二叉搜索树的展示如下:
这里是插入节点13
从上面实现可以知道,插入操作的时间复杂度是O(lgn),其中n是节点的个数,也就是时间复杂度是树的高度。当然在最坏情况下时间复杂度是O(n)。(当插入的数列已经排好序时,生成的二叉树及其不平衡,只有一个分支,而且深度为插入的个数)
2、二叉搜索树的删除操作
在介绍完二叉搜索树的插入操作后,下面介绍下二叉搜索树中最复杂的操作,删除节点操作remove(tree *root, datatype t).二叉搜索树的删除操作是相对要复杂的,这是因为删除操作有多种情况需要考虑,下面分别一一介绍:
假设要删除的节点是p,该节点的父节点是q,那么对p有下面的一些考察:
p和q的关系如下图所示:其中p的两个子节点用虚线表示,表示可能有也可能没有子节点;同时p也有可能是q的右孩子
针对上面的描述,可能有下面的几种情况需要考虑
a、如果p节点没有孩子节点,也就是说p节点是叶子节点,那么直接删除p对二叉搜索树是没有影响的,这样的情况下可以直接将q相应的子节点指针设置为空,然后free掉p
b、如果p的孩子节点有一个为空,例如左孩子为空或者右孩子为空。
对于这样的情况也可以分成两种讨论
if(p的左孩子为空)
{
if(p是q的左孩子)
{
q->左孩子 = p->右孩子:
}
if(p是q的右孩子)
{
q->右孩子 = p->右孩子
}
}同理
if(p的右孩子为空)
{
if(p是q的左孩子)
{
q->左孩子 = p->左孩子
}
if(p是q的右孩子)
{
q->右孩子 = p->左孩子
}
}上面是p的一个孩子为空c、p的左右孩子都不为空,这是最复杂的一种情况
在这种情况下需要考虑的比较多,如果要删除p节点的话,需要找到p的后继者(p的后继者肯定比p大,但是比其他数都小;此时p的后继者肯定是p的右子树中最小的一个,因为p有右孩子),然后将其放在p的位置,这样才能保证维持BST的性质。因此这种情况下就可以先找到p节点的后继者,然后将其和p进行交换,然后将交换后的节点删除。
下图是《算法导论》中删除节点的三种情况描述:
其中z节点是要删除的节点。(c)中的y节点是z的后继者
对于p的左右孩子都不为空的伪代码如下:
node *successor; //指向p的后继者
successor = find_min(p->rchild); //找到p的后继者y
p->data = successor->data; //将后继者y的值copy到p的数据域中
successor->parent->lchild = successor->rchild;//这里successor一定是其父节点的左孩子,因为如果他是父节点的右孩子的话,那么p的后继者就不是successor了,而应该是successor的parent了,因为successor的parent比successor小。这是这条语句左边的原因;对于右边来说,因为successor是p的后继者,那么successor一定是没有左孩子的,如果有的话,p的后继者就不是successor了,而是successor的左孩子了,因此successor至多有一个右孩子。这是对这条语句的解释。
操作完后就可以将successor释放掉了。
这些基本就是二叉搜索树的操作了,比较复杂的是插入和删除操作。

相关文章推荐
- 二叉搜索树;二叉查找树;二叉排序树;binary search tree
- Binary Search Tree(二叉搜索树、二叉查找树、二叉排序树)
- ※数据结构※→☆非线性结构(tree)☆============二叉搜索树(二叉查找树) 链式存储结构(tree Binary Search list)(二十五)
- 二叉搜索树;二叉查找树;二叉排序树;binary search tree(BST)
- 二叉排序树BinarySortTree(二叉搜索树Binary Search Tree)
- 二叉排序树(Binary Sort Tree,二叉查找树,二叉搜索树)--【算法导论】
- 编程算法 - 二叉搜索树(binary search tree) 代码(C)
- 二叉搜索树 ( 二叉查找树)( 二叉排序树)的定义和遍历
- [Data Structure] 二叉搜索树(Binary Search Tree) - 笔记
- 二叉搜索树(二叉查找树、二叉排序树)及其实现
- 二叉查找树(Binary Search Tree)的实现
- 编程算法 - 二叉搜索树(binary search tree) 集合(set)和映射(map) 代码(C)
- [LintCode]95.验证二叉查找树(二叉排序树/二叉搜索树) 中序遍历
- 二叉搜索树(Binary Search Tree)
- 二叉查找树 _ 二叉排序树 _ 二叉搜索树_C++
- Java二叉搜索树(Binary Search Tree)实现
- 节点node[算法导论]二叉排序树(Binary Search Tree)
- 二叉搜索树(Binary Search Tree)实现及测试
- 二叉搜索树(Binary Search Tree)
- 二叉搜索树(Binary Search Tree)的插入与删除