grep正则表达式原理介绍及应用实例
2014-07-12 15:15
661 查看
应用背景:我们刚刚添加了一个用户Luffy,但是不知道他的默认shell是什么。
问题:如何取出一个用户的默认shell?
解决方法:
#grep '^Luffy\>' /etc/passwd | cut -d: -f7
/bin/bashf
通过上面的方法,我们就得到了Luffy这个用户的默认shell
文本搜索工具:就是要根据用户指定的文本模式,逐行的进行匹配,最终得到符合文本模式的行
grep是一个强大的文本搜索工具,下面我们就介绍一下grep的语法:
grep [OPTIONS] PATTERN [FILE...]
grep后面上选项,然后是模式,最后是文件名
1、它的常用选项有:
-E, --extended-regexp //即,扩展的grep,我们后面会提及到egrep
-i, --ignore-case //即,忽略大小写
-v, --invert-match //即,取相反的操作
-o, --only-matching //即,仅显示匹配到的字串,并非所在行
-B, --before-context=NUM //即,取出匹配的行的前面三行的数据
-A, --after-context=NUM //即,取出匹配的行的后面三行的数据
-C, --context=NUM //即,取出匹配的行的上下三行的数据
-n, --line-number//即,匹配结果显示时,加上行号
2、说到匹配模式,我们就引入第二个概念,正则表达式:
正则表达式:是一类字符所组成的模式,且其中的字符,不表示其字面的意义,是一种控制或是通配功能的元字符。
简单来说,正则就是为了我们精确描述需要的内容所设置的,可以用于多个命令。
基本正则表达式的元字符:
a、字符匹配:
.:匹配任意的单个字符
举例:L..e 匹配有个L,后面跟两个字符,最后有个e的行
[]:匹配指定范围内的任意的单个字符
[0-9],[[:digit:]]----匹配数字
[a-z],[[:lower:]]----匹配小写字母
[A-Z],[[:upper:]]----匹配大写字母
[[:punct:]]----匹配标点符号
[[:alnum:]]----匹配字母或是数字
[[:alpha:]]----匹配字母(可以使大写、小写)
[[:space:]]----匹配空格
[^]-----取反
举例:[^A-Z] 匹配不在范围A到Z之间的任意个字符
b、次数匹配元字符:实现其前面的字符出现的次数:
*:表示其前面的字符可以出现任意次
\?:表示其前面的字符可以出现0次或是1次,即该字符是可有可无的
举例:lover\? 即r是可有可无的,可以使lover也可以是love
\{m\}:精确匹配,表示其前面的字符要出现m次
\{m,n\}:范围匹配,表示其前面的字符出现的次数在m,n之间,最小m次,最大n次
\{m,\}::范围匹配,表示其前面的字符出现最少m次
\{0,n\}:范围匹配,表示其前面的字符出现最多n次,可以在0到n次匹配
c、位置锚定:
^:行首锚定,即一行的开始位置
举例:^love 匹配所有以love开头的行
$:行尾锚定,即一行的末尾位置
举例:love$ 匹配所有以love结尾的行
^$:行首和行尾,表示空白行
\<:词首锚定,匹配单词的左侧,也可以用\b
举例:\<love 匹配包含以love开头的词的行
\>:词尾锚定,匹配单词的右侧,也可以用\b
举例:love\> 匹配包含以love结尾的词的行
d、分组:
\(\):分组中的模式匹配到的内容,可由正则记忆在内存中,之后可被使用
e、引用:
\n:引用第几个括号所匹配到的内容,而非模式本身
举例:\(love\).*\1r 匹配love,然后引用,后面加r,变成lover
扩展正则表示式(egrep):grep -e = egrep
字符匹配:
.:匹配任意的单个字符
[]:匹配指定范围内的任意的单个字符(应用如上面的基本正则)
[^]:表示取反
次数匹配:(与上方的基本正则不同的是,没有转义符\)
*:任意次
?:0次或是1次
+:至少一次
{m}:精确匹配m次
{m,n}:至少m次,最多n次
{m,}:最少m次
{0,n}:最多n次
锚定:(参考上面基本正则的用法)
分组:
( ):分组中的模式匹配到的内容,可由正则记忆在内存中,之后可被使用
注意:与上面的基本正则不同,没有转义符
引用:同上基本正则
或者:|
redhat|centos : redhat或者centos
实例应用(基础):
准备:将对如下的名为chsang.txt的文件进行操作

grep篇:
1、显示b和y之间有一个字符的行

2、找出以小写s开头的行:

3、找出以空白开头的行

4、找出含有数字开头的行

5、找出有most和must单词的行

6、找出small和smll开头的行

7、找出一个单词开头最面加r的行

egrep篇:
1、找出大小写s开头的行

2、只显示后面以点结尾的单词
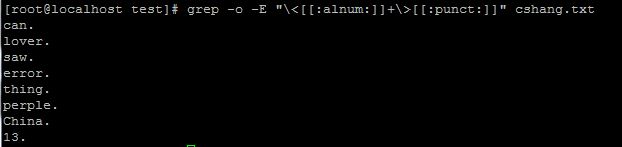
3、找出两位数或是两位数以上的行

提高题:
1、取出当前主机的ip地址

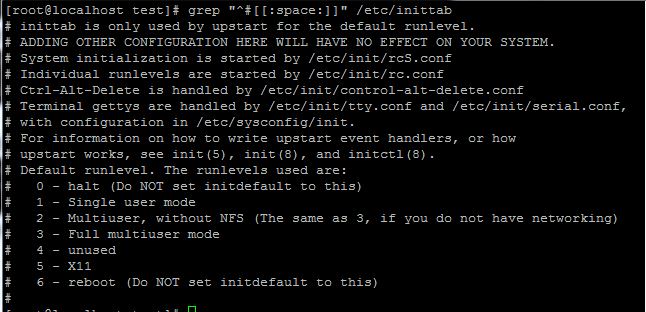
2、取出/etc/inittab文件中,以#开头,且后面跟一个空格的行
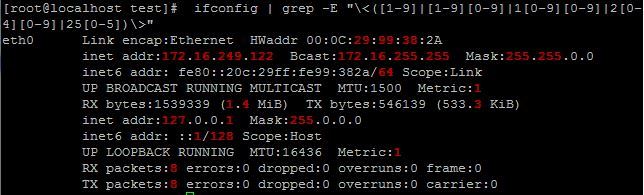
3、找出ifconfig命令结果中的1-255之间的数字
总结:grep在对于数据的处理,通过正则,我们可以从文件中取到我们需要的数据,并将其显示出来
对于不懂的地方,希望读者朋友多用man去查阅或是google一下。
以上都是个人通过学习后的理解,在这里我要感谢马哥教育给我带来的成长,同时,对于文章中的不对之处,请各位读者联系我,sch_0221@163.com,这是我的第一个博客,不喜勿喷,谢谢
问题:如何取出一个用户的默认shell?
解决方法:
#grep '^Luffy\>' /etc/passwd | cut -d: -f7
/bin/bashf
通过上面的方法,我们就得到了Luffy这个用户的默认shell
文本搜索工具:就是要根据用户指定的文本模式,逐行的进行匹配,最终得到符合文本模式的行
grep是一个强大的文本搜索工具,下面我们就介绍一下grep的语法:
grep [OPTIONS] PATTERN [FILE...]
grep后面上选项,然后是模式,最后是文件名
1、它的常用选项有:
-E, --extended-regexp //即,扩展的grep,我们后面会提及到egrep
-i, --ignore-case //即,忽略大小写
-v, --invert-match //即,取相反的操作
-o, --only-matching //即,仅显示匹配到的字串,并非所在行
-B, --before-context=NUM //即,取出匹配的行的前面三行的数据
-A, --after-context=NUM //即,取出匹配的行的后面三行的数据
-C, --context=NUM //即,取出匹配的行的上下三行的数据
-n, --line-number//即,匹配结果显示时,加上行号
2、说到匹配模式,我们就引入第二个概念,正则表达式:
正则表达式:是一类字符所组成的模式,且其中的字符,不表示其字面的意义,是一种控制或是通配功能的元字符。
简单来说,正则就是为了我们精确描述需要的内容所设置的,可以用于多个命令。
基本正则表达式的元字符:
a、字符匹配:
.:匹配任意的单个字符
举例:L..e 匹配有个L,后面跟两个字符,最后有个e的行
[]:匹配指定范围内的任意的单个字符
[0-9],[[:digit:]]----匹配数字
[a-z],[[:lower:]]----匹配小写字母
[A-Z],[[:upper:]]----匹配大写字母
[[:punct:]]----匹配标点符号
[[:alnum:]]----匹配字母或是数字
[[:alpha:]]----匹配字母(可以使大写、小写)
[[:space:]]----匹配空格
[^]-----取反
举例:[^A-Z] 匹配不在范围A到Z之间的任意个字符
b、次数匹配元字符:实现其前面的字符出现的次数:
*:表示其前面的字符可以出现任意次
\?:表示其前面的字符可以出现0次或是1次,即该字符是可有可无的
举例:lover\? 即r是可有可无的,可以使lover也可以是love
\{m\}:精确匹配,表示其前面的字符要出现m次
\{m,n\}:范围匹配,表示其前面的字符出现的次数在m,n之间,最小m次,最大n次
\{m,\}::范围匹配,表示其前面的字符出现最少m次
\{0,n\}:范围匹配,表示其前面的字符出现最多n次,可以在0到n次匹配
c、位置锚定:
^:行首锚定,即一行的开始位置
举例:^love 匹配所有以love开头的行
$:行尾锚定,即一行的末尾位置
举例:love$ 匹配所有以love结尾的行
^$:行首和行尾,表示空白行
\<:词首锚定,匹配单词的左侧,也可以用\b
举例:\<love 匹配包含以love开头的词的行
\>:词尾锚定,匹配单词的右侧,也可以用\b
举例:love\> 匹配包含以love结尾的词的行
d、分组:
\(\):分组中的模式匹配到的内容,可由正则记忆在内存中,之后可被使用
e、引用:
\n:引用第几个括号所匹配到的内容,而非模式本身
举例:\(love\).*\1r 匹配love,然后引用,后面加r,变成lover
扩展正则表示式(egrep):grep -e = egrep
字符匹配:
.:匹配任意的单个字符
[]:匹配指定范围内的任意的单个字符(应用如上面的基本正则)
[^]:表示取反
次数匹配:(与上方的基本正则不同的是,没有转义符\)
*:任意次
?:0次或是1次
+:至少一次
{m}:精确匹配m次
{m,n}:至少m次,最多n次
{m,}:最少m次
{0,n}:最多n次
锚定:(参考上面基本正则的用法)
分组:
( ):分组中的模式匹配到的内容,可由正则记忆在内存中,之后可被使用
注意:与上面的基本正则不同,没有转义符
引用:同上基本正则
或者:|
redhat|centos : redhat或者centos
实例应用(基础):
准备:将对如下的名为chsang.txt的文件进行操作
grep篇:
1、显示b和y之间有一个字符的行
2、找出以小写s开头的行:
3、找出以空白开头的行
4、找出含有数字开头的行
5、找出有most和must单词的行
6、找出small和smll开头的行
7、找出一个单词开头最面加r的行
egrep篇:
1、找出大小写s开头的行
2、只显示后面以点结尾的单词
3、找出两位数或是两位数以上的行
提高题:
1、取出当前主机的ip地址
2、取出/etc/inittab文件中,以#开头,且后面跟一个空格的行
3、找出ifconfig命令结果中的1-255之间的数字
总结:grep在对于数据的处理,通过正则,我们可以从文件中取到我们需要的数据,并将其显示出来
对于不懂的地方,希望读者朋友多用man去查阅或是google一下。
以上都是个人通过学习后的理解,在这里我要感谢马哥教育给我带来的成长,同时,对于文章中的不对之处,请各位读者联系我,sch_0221@163.com,这是我的第一个博客,不喜勿喷,谢谢

相关文章推荐
- grep正则表达式原理介绍及应用实例
- php中常用的正则表达式的介绍及应用实例代码
- php中常用的正则表达式的介绍及应用实例代码
- 正则表达式的原理和介绍,应用(概念篇)
- 正则表达式的原理和介绍,应用(概念篇)
- 正则表达式的原理和介绍,应用(概念篇)
- 正则表达式的简单应用实例
- Google base的介绍、原理分析与应用实例 推荐
- TCL的读取、写入文件,正则表达式的应用及列表的应用实例
- 正则表达式以及grep的应用
- 正则表达式的实例应用
- JavaScript中简单应用正则表达式的小实例_文本替换_replace
- c#正则表达式应用实例(转)
- c#正则表达式应用实例
- 正则表达式应用实例
- 进阶--正则表达式的应用实例通俗说明
- [收藏] 正则表达式的入门与应用,1~4篇!grep/sed/perl/awk
- grep和正则表达式的配合应用
- 正则表达式的应用实例通俗说明
- PHP编程中正则表达式应用实例一