<Hadoop实战>学习 -- 基础知识,初级入门
2014-06-16 17:45
645 查看
Hadoop实现了一个分布式文件系统(Hadoop
Distributed File System)HDFS,其具有高容错性、高伸缩性等特点,设计用来部署在低廉的常用商业硬件上;它提供高吞吐率(high
throughput)来访问应用程序的数据,适合那些有着超大数据集(large
data set)的应用程序。HDFS放宽了对可移植操作系统接口(POSIX,Portable Operating System Interface)的要求,实现以流的形式(streaming access)访问文件系统中的数据。
由于具备低成本和前所未有的高扩展性,Hadoop已被公认为是新一代的大数据处理平台。就像30年前SQL(Structured
Query Language)出现一样,Hadoop正带来了新一轮的数据革命。如今Hadoop已从初出茅庐的小象变成了行业的巨人,但Hadoop仍需继续完善。
基于Java语言构建的Hadoop框架实际上一种分布式处理大数据平台,其包括软件和众多子项目。在近十年中Hadoop已成为大数据革命的中心。MapReduce作为Hadoop的核心是一种处理大型及超大型数据集(TB级别的数据。包括网络点击产生的流数据、日志文件、社交网络等所带来的数据)并生成相关的执行的编程模型。其主要思想是从函数式编程语言借鉴而来的,同时也包含了从矢量编程语言借鉴的特性。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,能够自动将失败的任务重新分配。存储冗余数据来确保数据的安全性。
低成本。普通的商业通用机器就可以运行Hadoop,Hadoop是开源的,项目的软件成本因此会大大降低。
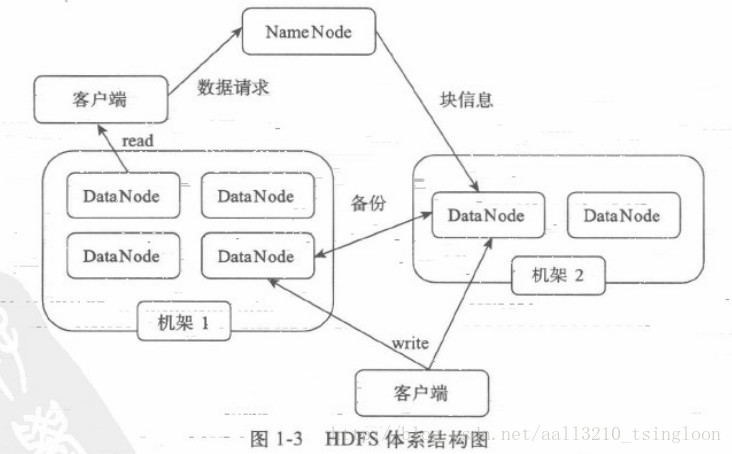
HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。图1-3给出了HDFS的体系结构。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。Map(映射)和Reduce(归约),和他们的主要思想,都是从函数式编程语言里来的。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,经过一定处理后交给Reduce,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
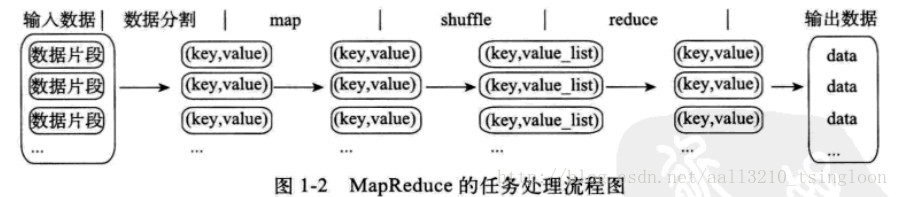
Hadoop上的并行应用程序开发是基于MapReduce编程框架的。MapReduce编程模型的原理是:利用一个输入的key/value 对集合来产生一个输出的key/value 对集合。MapReduce库的用户用两个函数来表达这个计算:Map和Reduce。
用户自定义的map函数接收一个输入的key/value 对,然后产生一个中间key/value 对的集合。MapReduce把所有具有相同key值的value集合在一起,然后传递给reduce函数。用户自定义的reduce函数接收key和相关的value集合。reduce函数合并这些value值,形成一个较小的value集合。一般来说,每次reduce函数调用只产生0或1个输出的value值。通常我们通过一个迭代器把中间的value值提供给reduce
函数,这样就可以处理无法全部放入内存中的大量的value值集合了。
1. 数据分布存储
Hadoop分布式文件系统(HDFS)由一个名称节点(NameNode )和N个数据节点 (DataNode)组成,每个节点均是一台普通的计算机。在使用方式上HDFS与我们熟悉的单机文件系统非常类似,它可以创建目录,创建、复制和删除文件,以及查看文件的内容等。但HDFS底层把文件切割成了Block,然后这些
Block 分散地存储于不同的 DataNode 上,每个 Block 还可以复制数份数据存储于不同的 DataNode 上,达到容错容灾的目的。NameNode 则是整个 HDFS 的核心,它通过维护一些数据结构来记录每一个文件被切割成了多少个 Block、这些 Block 可以从哪些 DataNode 中获得,以及各个 DataNode 的状态等重要信息。
2. 分布式并行计算
Hadoop 中有一个作为主控的
JobTracker,用于调度和管理其他的 TaskTracker,JobTracker 可以运行于集群中的任意一台计算机上。TaskTracker则负责执行任务,它必须运行于 DataNode 上,也就是说DataNode 既是数据存储节点,也是计算节点。 JobTracker 将 map 任务和 reduce 任务分发给空闲的 TaskTracker,让这些任务并行运行,并负责监控任务的运行情况。如果某一个
TaskTracker 出了故障,JobTracker 会将其负责的任务转交给另一个空闲的 TaskTracker 重新运行。
3. 本地计算
数据存储在哪一台计算机上,就由哪台计算机进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的需求。在 Hadoop 这类基于集群的分布式并行系统中,计算节点可以很方便地扩充,它所能够提供的计算能力近乎无限,但是由于数据需要在不同的计算机之间流动,故网络带宽变成了瓶颈,“本地计算”是一种最有效的节约网络带宽的手段,业界把这形容为“移动计算比移动数据更经济”。
4. 任务粒度
把原始大数据集切割成小数据集时,通常让小数据集小于或等于 HDFS 中一个 Block 的大小(默认是64MB),这样能够保证一个小数据集是位于一台计算机上的,便于本地计算。有 M 个小数据集待处理,就启动 M 个 map 任务,注意这 M 个map 任务分布于 N 台计算机上,它们会并行运行,reduce 任务的数量 R 则可由用户指定。
5. 数据分割(Partition)
把 map 任务输出的中间结果按 key 的范围划分成R份(R是预先定义的reduce 任务的个数),划分时通常使用 hash 函数(如:hash(key) mod R),这样可以保证某一范围内的 key一定是由一个 reduce 任务来处理的,可以简化 Reduce 的过程。
6. 数据合并(Combine)
在数据分割之前,还可以先对中间结果进行数据合并(Combine),即将中间结果中有相同 key的 <key, value> 对合并成一对。Combine 的过程与reduce 的过程类似,很多情况下可以直接使用reduce 函数,但 Combine 是作为map 任务的一部分,在执行完map函数后紧接着执行的。Combine 能够减少中间结果中 <key, value>
对的数目,从而降低网络流量。
7. Reduce
Map 任务的中间结果在做完 Combine 和 Partition 之后,以文件形式存于本地磁盘上。中间结果文件的位置会通知主控 JobTracker,JobTracker 再通知 reduce 任务到哪一个 DataNode 上去取中间结果。注意,所有的map 任务产生的中间结果均按其key 值用同一个 hash 函数划分成了R份,R个reduce 任务各自负责一段key 区间。每个reduce 需要向许多个map
任务节点取得落在其负责的key 区间内的中间结果,然后执行reduce函数,形成一个最终的结果文件。
8. 任务管道
有 R 个 reduce 任务,就会有 R 个最终结果,很多情况下这 R 个最终结果并不需要合并成一个最终结果,因为这 R 个最终结果又可以作为另一个计算任务的输入,开始另一个并行计算任务,这也就形成了任务管道。
Distributed File System)HDFS,其具有高容错性、高伸缩性等特点,设计用来部署在低廉的常用商业硬件上;它提供高吞吐率(high
throughput)来访问应用程序的数据,适合那些有着超大数据集(large
data set)的应用程序。HDFS放宽了对可移植操作系统接口(POSIX,Portable Operating System Interface)的要求,实现以流的形式(streaming access)访问文件系统中的数据。
由于具备低成本和前所未有的高扩展性,Hadoop已被公认为是新一代的大数据处理平台。就像30年前SQL(Structured
Query Language)出现一样,Hadoop正带来了新一轮的数据革命。如今Hadoop已从初出茅庐的小象变成了行业的巨人,但Hadoop仍需继续完善。
基于Java语言构建的Hadoop框架实际上一种分布式处理大数据平台,其包括软件和众多子项目。在近十年中Hadoop已成为大数据革命的中心。MapReduce作为Hadoop的核心是一种处理大型及超大型数据集(TB级别的数据。包括网络点击产生的流数据、日志文件、社交网络等所带来的数据)并生成相关的执行的编程模型。其主要思想是从函数式编程语言借鉴而来的,同时也包含了从矢量编程语言借鉴的特性。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,能够自动将失败的任务重新分配。存储冗余数据来确保数据的安全性。
低成本。普通的商业通用机器就可以运行Hadoop,Hadoop是开源的,项目的软件成本因此会大大降低。
HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。图1-3给出了HDFS的体系结构。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。Map(映射)和Reduce(归约),和他们的主要思想,都是从函数式编程语言里来的。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,经过一定处理后交给Reduce,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Hadoop上的并行应用程序开发是基于MapReduce编程框架的。MapReduce编程模型的原理是:利用一个输入的key/value 对集合来产生一个输出的key/value 对集合。MapReduce库的用户用两个函数来表达这个计算:Map和Reduce。
用户自定义的map函数接收一个输入的key/value 对,然后产生一个中间key/value 对的集合。MapReduce把所有具有相同key值的value集合在一起,然后传递给reduce函数。用户自定义的reduce函数接收key和相关的value集合。reduce函数合并这些value值,形成一个较小的value集合。一般来说,每次reduce函数调用只产生0或1个输出的value值。通常我们通过一个迭代器把中间的value值提供给reduce
函数,这样就可以处理无法全部放入内存中的大量的value值集合了。
1. 数据分布存储
Hadoop分布式文件系统(HDFS)由一个名称节点(NameNode )和N个数据节点 (DataNode)组成,每个节点均是一台普通的计算机。在使用方式上HDFS与我们熟悉的单机文件系统非常类似,它可以创建目录,创建、复制和删除文件,以及查看文件的内容等。但HDFS底层把文件切割成了Block,然后这些
Block 分散地存储于不同的 DataNode 上,每个 Block 还可以复制数份数据存储于不同的 DataNode 上,达到容错容灾的目的。NameNode 则是整个 HDFS 的核心,它通过维护一些数据结构来记录每一个文件被切割成了多少个 Block、这些 Block 可以从哪些 DataNode 中获得,以及各个 DataNode 的状态等重要信息。
2. 分布式并行计算
Hadoop 中有一个作为主控的
JobTracker,用于调度和管理其他的 TaskTracker,JobTracker 可以运行于集群中的任意一台计算机上。TaskTracker则负责执行任务,它必须运行于 DataNode 上,也就是说DataNode 既是数据存储节点,也是计算节点。 JobTracker 将 map 任务和 reduce 任务分发给空闲的 TaskTracker,让这些任务并行运行,并负责监控任务的运行情况。如果某一个
TaskTracker 出了故障,JobTracker 会将其负责的任务转交给另一个空闲的 TaskTracker 重新运行。
3. 本地计算
数据存储在哪一台计算机上,就由哪台计算机进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的需求。在 Hadoop 这类基于集群的分布式并行系统中,计算节点可以很方便地扩充,它所能够提供的计算能力近乎无限,但是由于数据需要在不同的计算机之间流动,故网络带宽变成了瓶颈,“本地计算”是一种最有效的节约网络带宽的手段,业界把这形容为“移动计算比移动数据更经济”。
4. 任务粒度
把原始大数据集切割成小数据集时,通常让小数据集小于或等于 HDFS 中一个 Block 的大小(默认是64MB),这样能够保证一个小数据集是位于一台计算机上的,便于本地计算。有 M 个小数据集待处理,就启动 M 个 map 任务,注意这 M 个map 任务分布于 N 台计算机上,它们会并行运行,reduce 任务的数量 R 则可由用户指定。
5. 数据分割(Partition)
把 map 任务输出的中间结果按 key 的范围划分成R份(R是预先定义的reduce 任务的个数),划分时通常使用 hash 函数(如:hash(key) mod R),这样可以保证某一范围内的 key一定是由一个 reduce 任务来处理的,可以简化 Reduce 的过程。
6. 数据合并(Combine)
在数据分割之前,还可以先对中间结果进行数据合并(Combine),即将中间结果中有相同 key的 <key, value> 对合并成一对。Combine 的过程与reduce 的过程类似,很多情况下可以直接使用reduce 函数,但 Combine 是作为map 任务的一部分,在执行完map函数后紧接着执行的。Combine 能够减少中间结果中 <key, value>
对的数目,从而降低网络流量。
7. Reduce
Map 任务的中间结果在做完 Combine 和 Partition 之后,以文件形式存于本地磁盘上。中间结果文件的位置会通知主控 JobTracker,JobTracker 再通知 reduce 任务到哪一个 DataNode 上去取中间结果。注意,所有的map 任务产生的中间结果均按其key 值用同一个 hash 函数划分成了R份,R个reduce 任务各自负责一段key 区间。每个reduce 需要向许多个map
任务节点取得落在其负责的key 区间内的中间结果,然后执行reduce函数,形成一个最终的结果文件。
8. 任务管道
有 R 个 reduce 任务,就会有 R 个最终结果,很多情况下这 R 个最终结果并不需要合并成一个最终结果,因为这 R 个最终结果又可以作为另一个计算任务的输入,开始另一个并行计算任务,这也就形成了任务管道。

相关文章推荐
- Angular 4 学习笔记 从入门到实战 打造在线竞拍网站 基础知识 快速入门 个人感悟
- <<UNIX环境高级编程>>学习总结——第一章:UNIX基础知识
- java 从零开始,学习笔记之基础入门<统计图>(四十四)
- Linux学习笔记一 ---- Linux基础知识认知以及初识Linux下C编程入门
- 基础知识04 - 零基础入门学习汇编语言04
- undo系列学习之undo入门基础知识介绍
- 基础知识01 - 零基础入门学习汇编语言01
- 新手必看的PHP学习入门的一些基础知识
- <笔记>.NET基础知识03
- <笔记>.NET基础知识01
- 基础知识03 - 零基础入门学习汇编语言03
- JAVA基础学习--IO流总结<一>
- PHP学习入门的一些基础知识(菜鸟必看)
- MVC学习笔记之入门篇(二)mvc3相关介绍以及基础知识篇
- struts 入门基础知识学习总结(转)
- HTML入门学习 -- HTML基础知识
- 基础知识04 - 零基础入门学习汇编语言04
- 基础知识02 - 零基础入门学习汇编语言02
- html系统学习之一<基础知识,标签,元素>
- SVC学习小结-SVC入门知识和JSVM基础实验