协同过滤推荐算法
2014-05-16 00:00
260 查看
摘要: 协同过滤推荐算法
皮尔森相关系数计算公式如下:

分子是协方差,分子是两个变量标准差的乘积。显然要求X和Y的标准差都不能为0。
因为

,所以皮尔森相关系数计算公式还可以写成:

当两个变量的线性关系增强时,相关系数趋于1或-1。
step1.如果用户i对项目j没有评过分,就找到与用户i最相似的K个邻居(使用向量相似度度量方法)
step2.然后用这K个邻居对项目j的评分的加权平均来预测用户i对项目j的评分。
用户评分数据矩阵
step1.
用户评分矩阵是个高度稀疏的矩阵,即用户对很多项目都没有评分。在高度稀疏的情况下用传统的向量相似度度量方法来度量两个用户的相似度就会很不准确。一种简单的处理办法是对未评分的项都令其等于该用户的平均评分值。
度量用户i和用户j相似度更好的方法是:
1.用户i参与评分的项目集合为Ii,用户i参与评分的项目集合为Ij,找到它们的并集

2.在集合

中用户i未评分的项目是
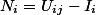
,重新估计用户i对

中每个项目的评分

。
2.1.取出评分矩阵的两列,计算这两列的相似度就是这两个项目的相似度。

。找到与

最相似的V个项目构成集合

。
2.2.

3.这样用户i和j对
的评分就都是非0值了,在此情况下计算他们的相似度。
step2.


表示用户u对所有评分过的项目的评分平均值。
完了,可以看到算法非常的简单,核心就是计算向量的相似度。代码量也很少。
Collaborative Filtering Recommendation
向量之间的相似度
度量向量之间的相似度方法很多了,你可以用距离(各种距离)的倒数,向量夹角,Pearson相关系数等。皮尔森相关系数计算公式如下:
分子是协方差,分子是两个变量标准差的乘积。显然要求X和Y的标准差都不能为0。
因为
,所以皮尔森相关系数计算公式还可以写成:
当两个变量的线性关系增强时,相关系数趋于1或-1。
用户评分预测
用户评分预测的基本原理是:step1.如果用户i对项目j没有评过分,就找到与用户i最相似的K个邻居(使用向量相似度度量方法)
step2.然后用这K个邻居对项目j的评分的加权平均来预测用户i对项目j的评分。
| iterm1 | ………… | itemn | |
| user1 | R11 | R1n | |
| …… | Rij | ||
| userm | Rm1 | Rmn |
step1.
用户评分矩阵是个高度稀疏的矩阵,即用户对很多项目都没有评分。在高度稀疏的情况下用传统的向量相似度度量方法来度量两个用户的相似度就会很不准确。一种简单的处理办法是对未评分的项都令其等于该用户的平均评分值。
度量用户i和用户j相似度更好的方法是:
1.用户i参与评分的项目集合为Ii,用户i参与评分的项目集合为Ij,找到它们的并集
2.在集合
中用户i未评分的项目是
,重新估计用户i对
中每个项目的评分
。
2.1.取出评分矩阵的两列,计算这两列的相似度就是这两个项目的相似度。
。找到与
最相似的V个项目构成集合
。
2.2.
3.这样用户i和j对
的评分就都是非0值了,在此情况下计算他们的相似度。
step2.
表示用户u对所有评分过的项目的评分平均值。
完了,可以看到算法非常的简单,核心就是计算向量的相似度。代码量也很少。
#include<iostream>
#include<queue>
#include<cmath>
#include<cassert>
#include<cstdlib>
#include<fstream>
#include<sstream>
#include<vector>
#include<algorithm>
using namespace std;
const int ITERM_SIZE=1682;
const int USER_SIZE=943;
const int V=15; //ITERM的最近邻居数
const int S=10; //USER的最近邻居数
struct MyPair{
int id;
double value;
MyPair(int i=0,double v=0):id(i),value(v){}
};
struct cmp{
bool operator() (const MyPair & obj1,const MyPair & obj2)const{
return obj1.value < obj2.value;
}
};
double rate[USER_SIZE][ITERM_SIZE]; //评分矩阵
MyPair nbi[ITERM_SIZE][V]; //存放每个ITERM的最近邻居
MyPair nbu[USER_SIZE][S]; //存放每个USER的最近邻居
double rate_avg[USER_SIZE]; //每个用户的平均评分
//从文件中读入评分矩阵
int readRate(string filename){
ifstream ifs;
ifs.open(filename.c_str());
if(!ifs){
cerr<<"error:unable to open input file "<<filename<<endl;
return -1;
}
string line;
while(getline(ifs,line)){
string str1,str2,str3;
istringstream strstm(line);
strstm>>str1>>str2>>str3;
int userid=atoi(str1.c_str());
int itermid=atoi(str2.c_str());
double rating=atof(str3.c_str());
rate[userid-1][itermid-1]=rating;
line.clear();
}
ifs.close();
return 0;
}
//计算每个用户的平均评分
void getAvgRate(){
for(int i=0;i<USER_SIZE;++i){
double sum=0;
for(int j=0;j<ITERM_SIZE;++j)
sum+=rate[i][j];
rate_avg[i]=sum/ITERM_SIZE;
}
}
//计算两个向量的皮尔森相关系数
double getSim(const vector<double> &vec1,const vector<double> &vec2){
int len=vec1.size();
assert(len==vec2.size());
double sum1=0;
double sum2=0;
double sum1_1=0;
double sum2_2=0;
double sum=0;
for(int i=0;i<len;i++){
sum+=vec1[i]*vec2[i];
sum1+=vec1[i];
sum2+=vec2[i];
sum1_1+=vec1[i]*vec1[i];
sum2_2+=vec2[i]*vec2[i];
}
double ex=sum1/len;
double ey=sum2/len;
double ex2=sum1_1/len;
double ey2=sum2_2/len;
double exy=sum/len;
double sdx=sqrt(ex2-ex*ex);
double sdy=sqrt(ey2-ey*ey);
assert(sdx!=0 && sdy!=0);
double sim=(exy-ex*ey)/(sdx*sdy);
return sim;
}
//计算每个ITERM的最近邻
void getNBI(){
for(int i=0;i<ITERM_SIZE;++i){
vector<double> vec1;
priority_queue<MyPair,vector<MyPair>,cmp> neighbour;
for(int k=0;k<USER_SIZE;k++)
vec1.push_back(rate[k][i]);
for(int j=0;j<ITERM_SIZE;j++){
if(i==j)
continue;
vector<double> vec2;
for(int k=0;k<USER_SIZE;k++)
vec2.push_back(rate[k][j]);
double sim=getSim(vec1,vec2);
MyPair p(j,sim);
neighbour.push(p);
}
for(int j=0;j<V;++j){
nbi[i][j]=neighbour.top();
neighbour.pop();
}
}
}
//预测用户对未评分项目的评分值
double getPredict(const vector<double> &user,int index){
double sum1=0;
double sum2=0;
for(int i=0;i<V;++i){
int neib_index=nbi[index][i].id;
double neib_sim=nbi[index][i].value;
sum1+=neib_sim*user[neib_index];
sum2+=fabs(neib_sim);
}
return sum1/sum2;
}
//计算两个用户的相似度
double getUserSim(const vector<double> &user1,const vector<double> &user2){
vector<double> vec1;
vector<double> vec2;
int len=user1.size();
assert(len==user2.size());
for(int i=0;i<len;++i){
if(user1[i]!=0 || user2[i]!=0){
if(user1[i]!=0)
vec1.push_back(user1[i]);
else
vec1.push_back(getPredict(user1,i));
if(user2[i]!=0)
vec2.push_back(user2[i]);
else
vec2.push_back(getPredict(user2,i));
}
}
return getSim(vec1,vec2);
}
//计算每个USER的最近邻
void getNBU(){
for(int i=0;i<USER_SIZE;++i){
vector<double> user1;
priority_queue<MyPair,vector<MyPair>,cmp> neighbour;
for(int k=0;k<ITERM_SIZE;++k)
user1.push_back(rate[i][k]);
for(int j=0;j<USER_SIZE;++j){
if(j==i)
continue;
vector<double> user2;
for(int k=0;k<ITERM_SIZE;++k)
user2.push_back(rate[j][k]);
double sim=getUserSim(user1,user2);
MyPair p(j,sim);
neighbour.push(p);
}
for(int j=0;j<S;++j){
nbu[i][j]=neighbour.top();
neighbour.pop();
}
}
}
//产生推荐,预测某用户对某项目的评分
double predictRate(int user,int iterm){
double sum1=0;
double sum2=0;
for(int i=0;i<S;++i){
int neib_index=nbu[user][i].id;
double neib_sim=nbu[user][i].value;
sum1+=neib_sim*(rate[neib_index][iterm]-rate_avg[neib_index]);
sum2+=fabs(neib_sim);
}
return rate_avg[user]+sum1/sum2;
}
//测试
int main(){
string file="/home/orisun/DataSet/movie-lens-100k/u.data";
if(readRate(file)!=0){
return -1;
}
getAvgRate();
getNBI();
getNBU();
while(1){
cout<<"please input user index and iterm index which you want predict"<<endl;
int user,iterm;
cin>>user>>iterm;
cout<<predictRate(user,iterm)<<endl;
}
return 0;
}

相关文章推荐
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 推荐引擎算法学习导论:协同过滤、聚类、分类
- 深入推荐引擎相关算法 – 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密:深入推荐引擎相关算法 - 协同过滤
- 协同过滤推荐算法之Slope One的介绍
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 深入推荐引擎相关算法 - 协同过滤
- 深入相关算法,协同过滤:探索推荐引擎内部的秘密(2)
- 推荐引擎算法学习导论:协同过滤、聚类、分类
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 推荐引擎算法学习导论:协同过滤、聚类、分类
- 探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤
- 协同过滤推荐算法