分布式系统概念和设计 第十五章 (2)
2014-04-29 13:58
253 查看
由于blog的字数限制,将本章分为两个部分,参见分布式系统概念和设计 第十五章 (1)。
附件为完整版。
本文出自 “天天向上呗” 博客,请务必保留此出处http://usdaydayup.blog.51cto.com/8723085/1404527
附件为完整版。
| A simple totally ordered broadcast protocol by Benjamin Reed, Flavio P.Junqueira from Yahoo (Zookeeper) 文章概要介绍了一个全序广播协议Zab,并且基于Zab实现了一个高可用性的一致协商服务(coordination service), ZooKeeper。 ZooKeeper可以支持大规模应用程序执行协商, 比如master选举,状态广播,配置(rendezvous??)等。 Zookeeper以树状层级结构的方式来表示逻辑资源(类似一个文件系统的结构),每个节点称为znodes, Client程序利用znodes来实现协商。 基于这种设计架构的Zookeeper可以为大量(web-scale),重要(mission critical)的应用程序服务。 Zookeeper放弃锁机制而是实现了在共享数据对象上的无等待(wait-free),并基于操作顺序来保证对这些共享对象的有序访问。对于Zookeeper来说相比锁机制,它更侧重于对顺序访问的保证。 有序广播是实现顺序访问的保证,并且确保每个副本机器上状态的一致性。 ZooKeeper通常由3到7台机器组成,当然更多的机器也可以支持,不过3到7台可以满足一个足够的性能和弹性要求。Client连接任意一个提供服务的副本机器。 如果ZooKeeper集群配置为2f + 1 个 副本机器,那么ZooKeeper服务能够容忍f个副本机器的失败而不中断服务。 ZooKeeper支持数以千记的客户端并发访问。 ZooKeeper设计的工作负载假设为读写比为2:1, 但是ZooKeeper对写操作的高吞吐量支持使得它可以被用在即使写占主要比例的工作负载下。ZooKeeper通过每台副本都可以提供从本地副本中支持读服务来提供高吞吐量的读操作支持。 因此也可以通过增加机器来提供fault-tolerant 和 更高的读操作吞吐量的要求。 但是写操作的吞吐量受限于广播协议本身。 ZooKeeper的读写操作的逻辑结构: 1> 读操作直接从本地的复制数据库来获得服务。 2> 写操作被转化为Zab协议的幂等性事务请求(idempotent transactions, 见下面的介绍),然后通过根据Zab协议提交后,写入本地复制数据库再返回给客户端。 (多次调用而执行相同的操作, 比如参考链接中的使用http来取款http://www.cnblogs.com/weidagang2046/archive/2011/06/04/2063696.html, 如果取款消息在返回的过程中包丢失,则用户可能重新提交,此时会再次扣款,通过增加一个本地的ticketID,使得多次提交带有ticketID的请求,即<ticketID, accountID, withDrawNum> 的多次调用返回相同结果,web client和server端执行相同的操作和结果)。 许多写请求是基于某些条件的。比如说一个znode只能在不包含任何子znode的时候才能被删除。一个znode可以根据一个名字和序列号来创建,更改只能被应用在被期望的版本上。当然非条件型的写操作,比如修改版本数据也是被支持的(需要吗??) 从单独一个master机器上广播所有的更新, 并将非幂等性请求转换为幂等性事务。论文中使用事务来表示请求的幂等性版本。因为master具有最新的副本状态,因此它可以执行这个请求转换。
另一篇介绍Zookeeper细节的论文, ZooKeeper: Wait-free coordination for Internet-scale systems。https://www.usenix.org/legacy/event/usenix10/tech/full_papers/Hunt.pdf ZooKeeper视频http://www.hakkalabs.co/articles/apache-zookeeper-introduction/ |
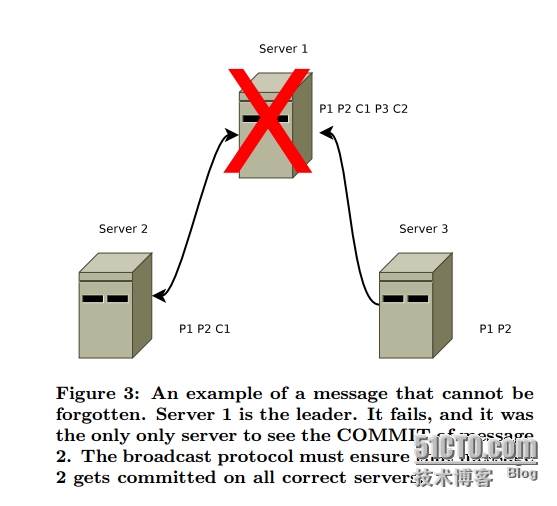
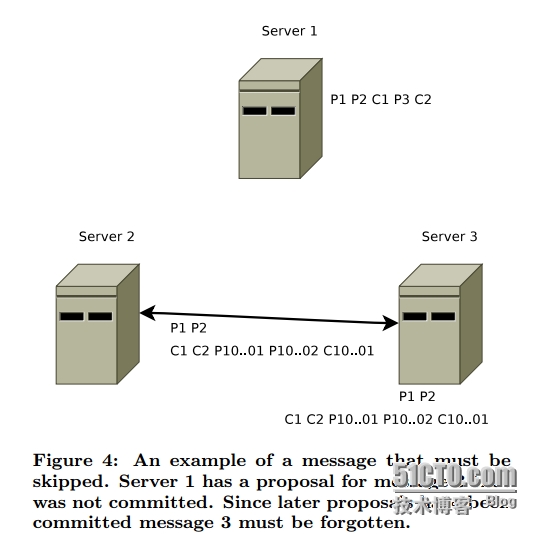
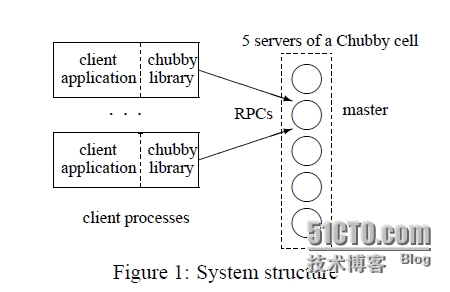
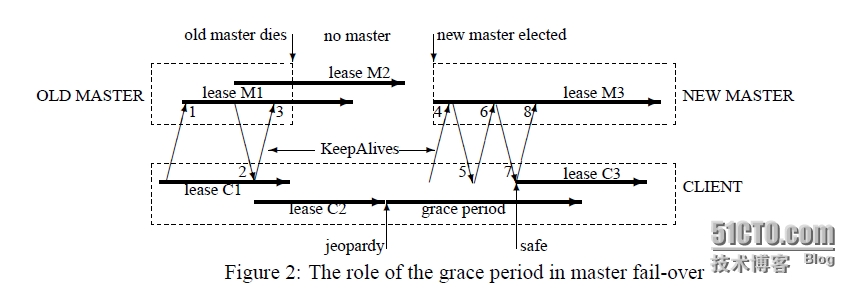
| The Chubby lock service for loosely-coupled distributed systems Mike Burrows, Google Inc. Chubby锁服务,提供一个基于松散耦合的分布式系统上的粗粒度锁和可靠的低容量存储服务。 提供一个类似带有文件锁(advisory lock)的分布式文件系统API接口。 文件锁的介绍 http://www.thegeekstuff.com/2012/04/linux-file-locking-types/ http://wenku.baidu.com/link?url=v-lG71nbM80IH9-B7pbpfeBDwst1qW59xZL_NJxO5hBI0mFCG_GxOGeb7kBfY5So7VRmwICObAAok0qqInEOOy0Td4vexDtkNJOxPMvFfUm 设计重点侧重于可用性和可靠性而非高性能(high performance)。
Paxos made parallelhttp://research.microsoft.com/apps/pubs/default.aspx?id=178045 Building Reliable Large-Scale Distributed System: When Theory Meets Practice. by Lidong Zhou |
| CAP 理论(http://www.cnblogs.com/mmjx/)CAP理论被很多人拿来作为分布式系统设计的金律,然而感觉大家对CAP这三个属性的认识却存在不少误区。从CAP的证明中可以看出来,这个理论的成立是需要很明确的对C、A、P三个概念进行界定的前提下的。在本文中笔者希望可以对论文和一些参考资料进行总结并附带一些思考。 一、什么是CAP理论CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩放的网络服务时候会遇到三个特性:一致性(consistency)、可用性(Availability)、分区容错(partition-tolerance)都需要的情景,然而这是不可能都实现的。之后在2003年的时候,Mit的Gilbert和Lynch就正式的证明了这三个特征确实是不可以兼得的。 二、CAP的概念Consistency、Availability、Partition-tolerance的提法是由Brewer提出的,而Gilbert和Lynch在证明的过程中改变了Consistency的概念,将其转化为Atomic。Gilbert认为这里所说的Consistency其实就是数据库系统中提到的ACID的另一种表述:一个用户请求要么成功、要么失败,不能处于中间状态(Atomic);一旦一个事务完成,将来的所有事务都必须基于这个完成后的状态(Consistent);未完成的事务不会互相影响(Isolated);一旦一个事务完成,就是持久的(Durable)。对于Availability,其概念没有变化,指的是对于一个系统而言,所有的请求都应该‘成功’并且收到‘返回’。对于Partition-tolerance,所指就是分布式系统的容错性。节点crash或者网络分片都不应该导致一个分布式系统停止服务。 三、基本CAP的证明思路CAP的证明基于异步网络,异步网络也是反映了真实网络中情况的模型。真实的网络系统中,节点之间不可能保持同步,即便是时钟也不可能保持同步,所有的节点依靠获得的消息来进行本地计算和通讯。这个概念其实是相当强的,意味着任何超时判断也是不可能的,因为没有共同的时间标准。之后我们会扩展CAP的证明到弱一点的异步网络中,这个网络中时钟不完全一致,但是时钟运行的步调是一致的,这种系统是允许节点做超时判断的。CAP的证明很简单,假设两个节点集{G1, G2},由于网络分片导致G1和G2之间所有的通讯都断开了,如果在G1中写,在G2中读刚写的数据, G2中返回的值不可能G1中的写值。由于A的要求,G2一定要返回这次读请求,由于P的存在,导致C一定是不可满足的。 四、CAP的扩展CAP的证明使用了一些很强的假设,比如纯粹的异步网络,强的C、A、P要求。事实上,我们可以放松某些条件,从而达到妥协。首先 ―― 弱异步网络模型弱异步网络模型中所有的节点都有一个时钟,并且这些时钟走的步调是一致的,虽然其绝对时间不一定相同,但是彼此的相对时间是固定的,这样系统中的节点可以不仅仅根据收到的消息来决定自己的状态,还可以使用时间来判断状态,比如超时什么的。在这种场景下,CAP假设依旧是成立的,证明跟上面很相似。 不可能的尝试 ―― 放松Availability或者Partition-tolerance放弃Partition-tolerance意味着把所有的机器搬到一台机器内部,或者放到一个要死大家一起死的机架上(当然机架也可能出现部分失效),这明显违背了我们希望的scalability。放弃Availability意味着,一旦系统中出现partition这样的错误,系统直接停止服务,这是不能容忍的。 最后的选择 ―― 放松一致性我们可以看出,证明CAP的关键在于对于一致性的强要求。在降低一致性的前提下,可以达到CAP的和谐共处,这也是现在大部分的分布式存储系统所采用的方式:Cassandra、Dynamo等。“Scalability is a bussness concern”是我们降低一致性而不是A和P的关键原因。Brewer后来提出了BASE (Basically Available, Soft-state, Eventually consistent),作为ACID的替代和补充。 五、战胜CAP1,2008年9月CTO of atomikos写了一篇文章“A CAP Solution (Proving Brewer Wrong)”,试图达到CAP都得的效果。这篇文章的核心内容就是放松Gilbert和Lynch证明中的限制:“系统必须同时达到CAP三个属性”,放松到“系统可以不同时达到CAP,而是分时达到”。Rules Beat CAP:1) 尽量从数据库中读取数据,如果数据库不能访问,读取缓存中的数据2) 所有读都必须有版本号3) 来自客户端的更新操作排队等候执行,update必须包括导致这次更新的读操作的版本信息4) 分区数量足够低的时候排队等待的update操作开始执行,附带的版本信息用来验证update是否应该执行5) 不管是确认还是取消更新,所有的结构都异步的发送给请求方证明:1) 系统保证了consistency,因为所有的读操作都是基于snapshot的,而不正确的update操作将被拒绝,不会导致错误执行2) 系统保证了availability,因为所有的读一定会返回,而写也一样,虽然可能会因为排队而返回的比较慢3) 系统允许节点失效缺点:1) 读数据可能会不一致,因为之前的写还在排队2) partition必须在有限的时间内解决3) update操作必须在所有的节点上保持同样的顺序 2, 2011年11月Twitter的首席工程师Nathan Marz写了一篇文章,描述了他是如何试图打败CAP定理的: How to beat the CAP theorem本文中,作者还是非常尊重CAP定律,并表示不是要“击败”CAP,而是尝试对数据存储系统进行重新设计,以可控的复杂度来实现CAP。Marz认为一个分布式系统面临CAP难题的两大问题就是:在数据库中如何使用不断变化的数据,如何使用算法来更新数据库中的数据。Marz提出了几个由于云计算的兴起而改变的传统概念:1) 数据不存在update,只存在append操作。这样就把对数据的处理由CRUD变为CR2) 所有的数据的操作就只剩下Create和Read。把Read作为一个Query来处理,而一个Query就是一个对整个数据集执行一个函数操作。在这样的模型下,我们使用最终一致性的模型来处理数据,可以保证在P的情况下保证A。而所有的不一致性都可以通过重复进行Query去除掉。Martz认为就是因为要不断的更新数据库中的数据,再加上CAP,才导致那些即便使用最终一致性的系统也会变得无比复杂,需要用到向量时钟、读修复这种技术,而如果系统中不存在会改变的数据,所有的更新都作为创建新数据的方式存在,读数据转化为一次请求,这样就可以避免最终一致性的复杂性,转而拥抱CAP。具体的做法这里略过。 总结:其实对于大规模分布式系统来说,CAP是非常稳固的,可以扩展的地方也不多。它很大程度上限制了大规模计算的能力,通过一些设计方式来绕过CAP管辖的区域或许是下一步大规模系统设计的关键。 问题:Paxos协议算是解决CAP了吗?? --------------- 参考文献 -----------------------[1] Seth Gilbert and Nancy Lynch. 2002. Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services. SIGACT News 33, 2 (June 2002), 51-59. DOI=10.1145/564585.564601 http://doi.acm.org/10.1145/564585.564601[2] Guy Pardon, 2008, A CAP Solution (Proving Brewer Wrong), http://blog.atomikos.com/2008/09/a-cap-solution-proving-brewer-wrong/[3] Werner Vogels, 2007, Availability & Consistency, http://www.infoq.com/presentations/availability-consistency[4] Nathan Marz, 2011, How to beat the CAP theorem, http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html |
| The Byzantine Generals Problem (TBR, to be read) 上面介绍过一小部分Byzantine问题,在n个节点中,可以容忍有f个节点传递错误消息而整个系统还是可以达成一致的条件是:n >=3 * f + 1。 在之上的分布式系统中,特别是组播算法中,都是假设没有拜占庭问题的,通常使用checksum 和 安全认证 来避免错误消息或者伪造消息。 |

相关文章推荐
- 分布式系统概念和设计 第十五章 (3) 转CAP作者的论述
- 分布式系统概念和设计 第十五章 (1)
- 分布式系统概念与设计-第十四章笔记
- 分布式系统概念与设计-CH4进程间通信t
- 分布式系统概念与设计-CH1:分布式系统的特征
- 分布式系统概念与设计学习(01),本书概要与基础概念
- 分布系统概念与设计---分布式系统特征
- 分布式系统概念与设计-第一章笔记
- 【分布式系统设计】基础概念
- [心得]分布式系统概念与设计知识整理
- 浅析海量用户的分布式系统设计
- 分布式日志收集系统Apache Flume的设计详细介绍
- 分布式电子邮件系统设计
- 分布式环境下限流系统的设计总结
- 分布式发布订阅消息系统 Kafka 架构设计
- 机房收费系统数据库概念设计模型——ER图
- 高并发服务端分布式系统设计概要(上)
- 分布式系统开发常见问题-1. session的复制与共享 2. 分布式缓存的设计
- 分布式发布订阅消息系统 Kafka 架构设计