以hadoop为数据源,用birt处理海量数据的方法
2014-04-14 14:27
141 查看
BIRT使用的开放数据接入框架(ODA),该框架很容易按照需要将新数据源加入BIRT。本文以Hadoop为数据源,简单介绍birt连接hadoop处理海量数据的方法。使用HQL来查询Hadoop数据BIRT允许使用HQL通过Hive来访问Hadoop数据。Hive是基于Hadoop的数据仓库的架构,用于提供数据摘要、查询和分析。只要编写HQL就能够从Hadoop中查询数据。HQL类似SQL支持多种相同关键词,如SELECT, WHERE, GROUP BY, ORDER BY, JOIN, 和 UNION。Hive查询的执行是通过一系列自动生成的MapReduce job完成的。也可以通过使用Hive中的TRANSFORM来自定义编写脚本转换为Hadoop中的MapReduce方法。这些脚本基本可以使用任何程序语言编写。例如,下面的HQL使用Python编写为mytest.py文件。
在BIRT中建立HQL查询从新数据源向导选择Hive数据源,进入连接属性,用于建立新查询,如下图所示。
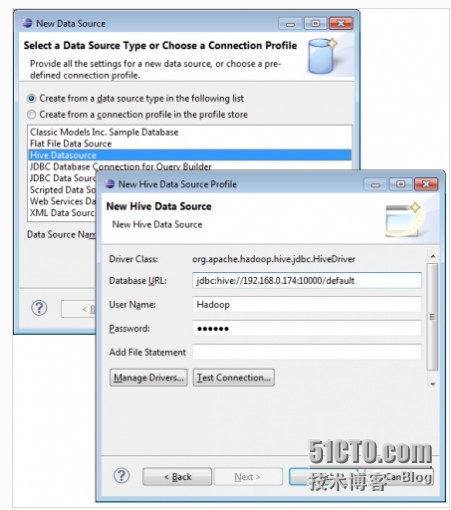
接下来,选择驱动并且添加Hive客户端JAR文件。

现在能够使用HQL查询建立一个数据集。如果查询使用TRANSFORM来引用脚本文件,使用添加文件属性将文件添加至Hadoop分布式缓存中。加入多个文件命令使用分号分隔。该属性能够在数据源或数据集中,使用绑定属性或脚本进行覆盖。在数据集编辑器中的查询文本框区域输入HQL查询语句,如下图。
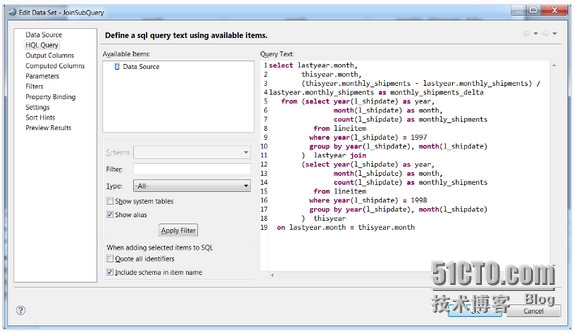


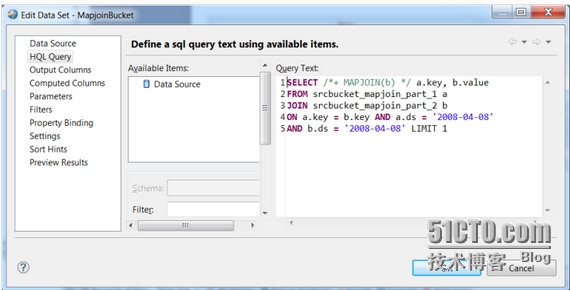
将重要数据突出的显示按照上述步骤建立多个数据集,甚至在BIRT中关联数据。一旦定义好海量数据连接和查询,就能够通过定义BIRT中的报告来使用数据了。此时能够简单拖拉数据集在报告界面上并且开始规格化。

但是为了能够存储更多数据带来了一系列的问题。更多的数据通常意味这更多的数据需要被分析及展示。重要的数据特别需要突出展示。BIRT通过一些开箱即可用的特性来支持这样的要求。高亮使用BIRT中的高亮特性,你能够基于表达式建立规格化规则。你能够构建从简单到复杂的表达式来高亮数据。高亮能够添加至网格,表格,列,行,数据元素,标签,图表和图像。

可见性
可见性特性允许使用表达式来定义BIRT的那些部分是可见的。在确定分组用户只能查看自己数据的场景是很有效的,而且可以用于隐藏发现数据的所有区域。可见性同样可以应用到网格,表格,列,行,数据元素,标签,图表和图像,而且还仍然可以建立单独的可见规则基于最终输出,如PDF,HTML等。

来自:http://www.importnew.com/4276.html
接下来,选择驱动并且添加Hive客户端JAR文件。
现在能够使用HQL查询建立一个数据集。如果查询使用TRANSFORM来引用脚本文件,使用添加文件属性将文件添加至Hadoop分布式缓存中。加入多个文件命令使用分号分隔。该属性能够在数据源或数据集中,使用绑定属性或脚本进行覆盖。在数据集编辑器中的查询文本框区域输入HQL查询语句,如下图。
将重要数据突出的显示按照上述步骤建立多个数据集,甚至在BIRT中关联数据。一旦定义好海量数据连接和查询,就能够通过定义BIRT中的报告来使用数据了。此时能够简单拖拉数据集在报告界面上并且开始规格化。
但是为了能够存储更多数据带来了一系列的问题。更多的数据通常意味这更多的数据需要被分析及展示。重要的数据特别需要突出展示。BIRT通过一些开箱即可用的特性来支持这样的要求。高亮使用BIRT中的高亮特性,你能够基于表达式建立规格化规则。你能够构建从简单到复杂的表达式来高亮数据。高亮能够添加至网格,表格,列,行,数据元素,标签,图表和图像。
可见性
可见性特性允许使用表达式来定义BIRT的那些部分是可见的。在确定分组用户只能查看自己数据的场景是很有效的,而且可以用于隐藏发现数据的所有区域。可见性同样可以应用到网格,表格,列,行,数据元素,标签,图表和图像,而且还仍然可以建立单独的可见规则基于最终输出,如PDF,HTML等。
来自:http://www.importnew.com/4276.html

相关文章推荐
- 常用海量数据处理方法/算法总结
- 海量数据的处理方法
- 从hadoop框架与MapReduce模式中谈海量数据处理
- 十道海量数据处理面试题与十个方法大总结
- 大数据量,海量数据 处理方法总结
- 十道海量数据处理面试题与十个方法大总结
- 海量数据 处理方法
- 从Hadoop框架与MapReduce模式中谈海量数据处理(淘宝技术架构)
- 从Hadoop框架与MapReduce模式中谈海量数据处理(淘宝技术架构)
- 海量数据处理方法总结
- ios数据源方法中一点细节的处理记录
- Hadoop启动异常的处理方法
- mysql处理海量数据时的一些优化查询速度方法
- 十道海量数据处理面试题与十个方法大总结(转载)
- 海量数据处理常用思路和方法
- 实战hadoop海量数据处理系列04预热篇:窗函数row_number 从理论到实践
- 十道海量数据处理面试题与十个方法大总结
- 海量数据处理方法总结
- 十道海量数据处理面试题与十个方法大总结
- 海量数据处理常用思路和方法