【算法-排序之二】快速排序
2014-03-13 21:09
218 查看
算法-排序之快速排序
快速排序得名于实际应用的高效率,它几乎是最快的排序算法,入选20世纪十大算法之列。快速排序体现了计算机设计的“分治法”思想,核心是将整个问题分割成多块相对容易处理的小问题,分而治之。利用分治法原理的排序算法,还有希尔排序(【算法-排序之四】希尔排序)算法等等。1.快速排序QuickSort
核心:如果你知道多少人该站你前面,多少人站你后面,你一定知道你该站哪个位置。
快速排序的步骤分为:
1.选取分界数,参考这个分界数,大于参考数放在右边,小于的放在左边。
2.对左右两边的序列分别递归进行1处理
3.将整个序列合并得到有序结果
相比冒泡排序【算法-排序之一】冒泡排序”冒泡“的形象,快速排序似乎就不那么贴切了。分析上述步骤,该算法每次分区,实际上确定了所选分界数的位置。
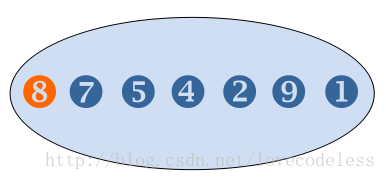
选中分界数:8 然后将序列分割
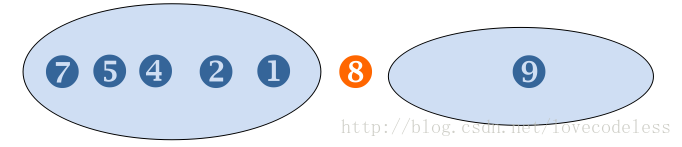
比8小的数 比8大的数
根据左右两个框内的数字个数,可以知道分界数8应该摆放的位置。快速排序的实现方式有很多,下面给出一种实现:
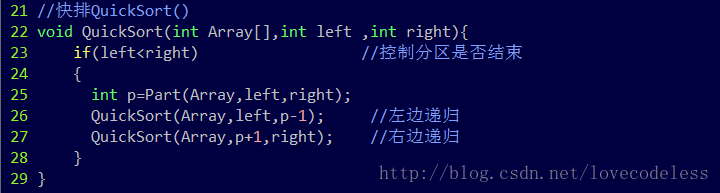
快速排序是众多排序算法中较复杂的一种,只要认真抓住算法的核心,理解快速排序还是不难的。
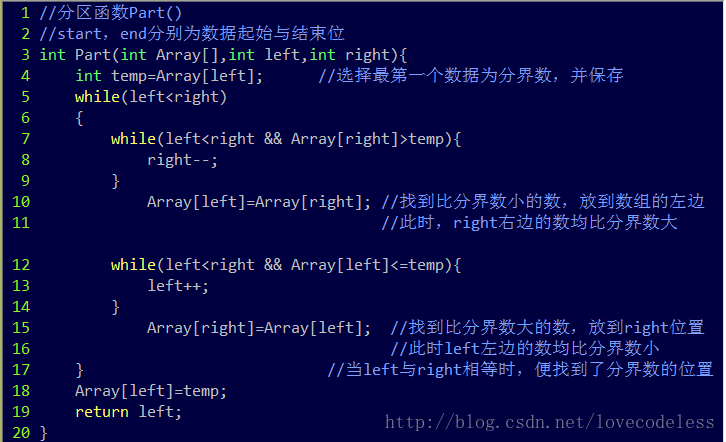
//分区函数Part()
//start,end分别为数据起始与结束位
int Part(int Array[],int left,int right){
int temp=Array[left]; //选择最第一个数据为分界数,并保存
while(lefttemp){
right--;
}
Array[left]=Array[right]; //找到比分界数小的数,放到数组的左边
//此时,right右边的数均比分界数大
while(left2.时间复杂度
分析快速排序的时间复杂度比较困难,通过递归方法,可以初略地看到结果:
n=1时: F(1)=0
F(n)=n-1+2*F(n/2) //分成两个大小为n/2的块
=n-1+2*(n/2-1)+4F(n/4)
=n-1+2*(n/2-1)+4*(n/4-1)+8F(n/8)
....
=O(nlogn)
得到这个结果需要较为复杂的数学推导。读者可以通过下面的图示理解:
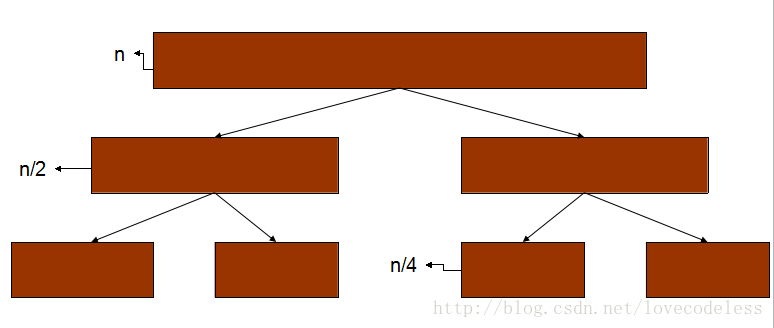
快速排序每次通过一个分界数把一个区域分成两份,越分越小,知道所有的区域都为1,整个数列便排好序了。
1.现在我们看看对数量为n的序列一共有几层(不算起始数,上图为2层)?
n=2,显然分1层;
n=4, 分2层;
n=8, 分3层;
......
n, logn层;
2.再来看看每层都有多少操作?
每层到下一层的过程,所有的数都需要且仅需要与该数所在区域分界数比较一次,便可确定在下一层的位置。由于序列的总数不变,故为n。
所以时间复杂度为:
n(每层比较次数)* logn(层数)= nlogn
你可能要说,每层的数不是n啊,因为还有选中的分界数,的确,但算法时间复杂度的分析有一个重要的原则:复杂度函数主要贡献主要来至大的数据,那些不能显著改变数量级的部分可以忽略不计。
这个时间复杂度优于冒泡排序【算法-排序之一】冒泡排序。
3. 空间复杂度
快速排序的空间消耗主要来源于递归调用时产生的栈消耗,其复杂度介于O(logn)与O(n)之间。

相关文章推荐
- 【算法-排序之二】快速排序
- 【算法-排序之二】快速排序
- 排序算法之二:快速排序
- Algorithms - 排序算法之二:快速排序
- 【重温经典算法之二】快速排序
- 白话经典算法系列之六 快速排序 快速搞定
- 基本的排序算法:冒泡排序、插入排序、希尔排序、选择排序、归并排序、快速排序、堆排序
- 常用的选择排序.Shell排序.快速排序.冒泡排序.插入排序的算法
- 第十六周项目1-(4)验证算法快速排序
- java 快速排序 算法
- 白话经典算法系列之六 快速排序 快速搞定
- C++——算法基础之排序——快速排序
- 算法导论快速排序python实现
- 【C#】3.算法温故而知新 - 快速排序
- 白话经典算法系列之六 快速排序 快速搞定
- 经典算法之快速排序
- 白话经典算法系列之六 快速排序
- 白话算法 快速排序
- 第16周SHH数据结构-【项目1-验证算法(4)快速排序 】
- 白话经典算法系列之六 快速排序 快速搞定