BFGS优化算法的理解以及LBFGS源码求解最优化问题
2014-03-13 20:09
393 查看
关于最优化求解,吴军有篇blog讲的很不错,证明和解释都很清楚,具体可以参考http://www.cnblogs.com/joneswood/archive/2012/03/11/2390529.html。
这里根据那篇blog的内容,主要讲解运用最广泛的LBFGS的算法思想和LBFGS源码的求解实际的最优化问题。
理论部分
一般优化算法中,比较简单的是梯度下降法,其主要思想为:
给定目标函数f(x),给定初始值x,沿着目标函数梯度方向下降,寻找最优解。
通过将目标函数,在初始值位置按照梯度下降方向,进行泰勒展开:
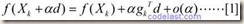
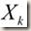
:代表第k个点的自变量(向量);
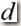
:单位方向(向量),即|d|=1;
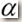
:步长(实数);
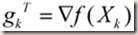
:目标函数在Xk这一点的梯度(导数向量);
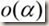
:α的高阶无穷小。
式[1]中的高阶无穷小可以忽略,因此,要使[1]式取得最小值,应使

取到最小,由此可得,
取
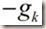
时,目标函数下降得最快,这就是负梯度方向作为“最速下降”方向的由来。
由于梯度下降法只用到了目标函数的一阶导数信息,由此想到将二阶导数信息运用到优化求解中,这就是牛顿法的思想。在
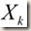
点处对目标函数进行泰勒展开,并只取二阶导数及其之前的几项(忽略更高阶的导数项),可得:
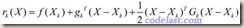
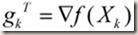
:目标函数在
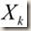
这一点的梯度;
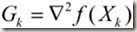
:目标函数在
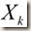
这一点的Hessian矩阵(二阶导数矩阵)。
由于极小值点必然是驻点,而驻点是一阶导数为0的点,所以,对 r(X) 这个函数来说,要取到极小值,应该分析其一阶导数。对X求一阶导数,并令其等于0:
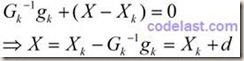
因此,下一点的计算方法:
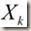
在方向d上按步长1(1×d
= d)移动到点X,方向d的计算方法:
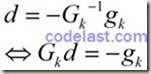
牛顿法的基本步骤:每一步迭代过程中,通过解线性方程组得到搜索方向,然后将自变量移动到下一个点,然后再计算是否符合收敛条件,不符合的话就一直按这个策略(解方程组→得到搜索方向→移动点→检验收敛条件)继续下去。由于牛顿法利用了目标函数的二阶导数信息,其收敛速度为二阶收敛,因此它比最速下降法要快,但是其对一般问题不是整体收敛的,只有当初始点充分接近极小点时,才有很好的收敛性。
牛顿法中,在每一次要得到新的搜索方向的时候,都需要计算Hessian矩阵(二阶导数矩阵)。在自变量维数非常大的时候,这个计算工作是非常耗时的,因此,拟牛顿法的诞生的意义就是:它采用了一定的方法来构造与Hessian矩阵相似的正定矩阵,而这个构造方法计算量比牛顿法小。
a. DFP算法
假设目标函数可以用二次函数进行近似(实际上很多函数可以用二次函数很好地近似):
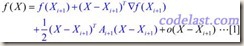
忽略高阶无穷小部分,只看前面3项,其中A为目标函数的Hessian矩阵。此式等号两边对X求导,可得:
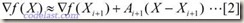
于是,当 X=Xi 时,将[2]式两边均左乘Ai+1-1,有:
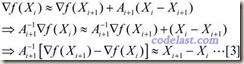
上式左右两边近似相等,但如果我们把它换成等号,并且用另一个矩阵H来代替上式中的A-1,则得到:
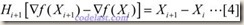
方程[4]就是拟牛顿方程,其中的矩阵H,就是Hessian矩阵的逆矩阵的一个近似矩阵.在迭代过程中生成的矩阵序列H0,H1,H2,……中,每一个矩阵Hi+1,都是由前一个矩阵Hi修正得到的。DFP算法的修正方法如下,设:
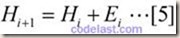
再设:
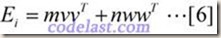
其中,m和n均为实数,v和w均为N维向量。将[6]代入[5]式,再将[5]式代入[4]式,可得:
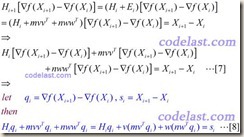
得到的m,n,v,w值如下:

将[8]~[11]代入[6]式,然后再将[6]代入[5]式,就得到了Hessian矩阵的逆矩阵的近似阵H的计算方法:
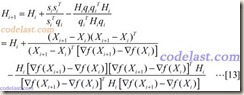
通过上述描述,DFP算法的流程大致如下:
已知初始正定矩阵H0,从一个初始点开始(迭代),用式子

来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序终止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序终止条件。
值得注意的是,矩阵H正定是使目标函数值下降的条件,所以,它保持正定性很重要。可以证明,矩阵H保持正定的充分必要条件是:
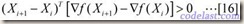
在迭代过程中,这个条件也是容易满足的。
b. BFGS算法
BFGS算法和DFP算法有些相似,但是形式上更加复杂一些。BFGS算法目前仍然被认为是最好的拟牛顿算法。BFGS算法中矩阵H的计算公式如下所示:
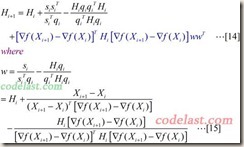
在[14]式中的最后一项(蓝色部分)就是BFGS比DFP多出来的部分,其中w是一个n×1的向量。
在目标函数为二次型时,无论是DFP还是BFGS——也就是说,无论[14]式中有没有最后一项——它们均可以使矩阵H在n步之内收敛于A-1。
代码实验:
网络上面有很多BFGS的实现算法,用的比较多的是c++实现的源码库libbfgs,http://www.chokkan.org/software/liblbfgs/.
网上编译即可以使用。
本文以求解 f(x1,x2) = 100(x2-x1^2)^2 + (1-x1)^2为例,对比matlab和libbfgs的结果。
在matlab中求解该优化问题,可得如下结果:

运用libbfgs库,编程实现优化问题:
运行程序:

对比可得,L-BFGS程序经过36次迭代即可求得最优解,且跟matlab的求解结果一致。
这里根据那篇blog的内容,主要讲解运用最广泛的LBFGS的算法思想和LBFGS源码的求解实际的最优化问题。
理论部分
一般优化算法中,比较简单的是梯度下降法,其主要思想为:
给定目标函数f(x),给定初始值x,沿着目标函数梯度方向下降,寻找最优解。
通过将目标函数,在初始值位置按照梯度下降方向,进行泰勒展开:
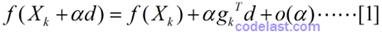
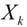
:代表第k个点的自变量(向量);
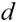
:单位方向(向量),即|d|=1;
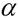
:步长(实数);
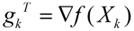
:目标函数在Xk这一点的梯度(导数向量);
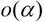
:α的高阶无穷小。
式[1]中的高阶无穷小可以忽略,因此,要使[1]式取得最小值,应使
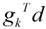
取到最小,由此可得,
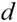
取
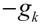
时,目标函数下降得最快,这就是负梯度方向作为“最速下降”方向的由来。
由于梯度下降法只用到了目标函数的一阶导数信息,由此想到将二阶导数信息运用到优化求解中,这就是牛顿法的思想。在
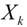
点处对目标函数进行泰勒展开,并只取二阶导数及其之前的几项(忽略更高阶的导数项),可得:
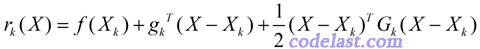

:目标函数在

这一点的梯度;
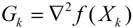
:目标函数在
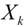
这一点的Hessian矩阵(二阶导数矩阵)。
由于极小值点必然是驻点,而驻点是一阶导数为0的点,所以,对 r(X) 这个函数来说,要取到极小值,应该分析其一阶导数。对X求一阶导数,并令其等于0:
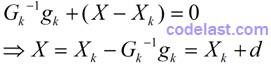
因此,下一点的计算方法:
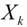
在方向d上按步长1(1×d
= d)移动到点X,方向d的计算方法:

牛顿法的基本步骤:每一步迭代过程中,通过解线性方程组得到搜索方向,然后将自变量移动到下一个点,然后再计算是否符合收敛条件,不符合的话就一直按这个策略(解方程组→得到搜索方向→移动点→检验收敛条件)继续下去。由于牛顿法利用了目标函数的二阶导数信息,其收敛速度为二阶收敛,因此它比最速下降法要快,但是其对一般问题不是整体收敛的,只有当初始点充分接近极小点时,才有很好的收敛性。
牛顿法中,在每一次要得到新的搜索方向的时候,都需要计算Hessian矩阵(二阶导数矩阵)。在自变量维数非常大的时候,这个计算工作是非常耗时的,因此,拟牛顿法的诞生的意义就是:它采用了一定的方法来构造与Hessian矩阵相似的正定矩阵,而这个构造方法计算量比牛顿法小。
a. DFP算法
假设目标函数可以用二次函数进行近似(实际上很多函数可以用二次函数很好地近似):
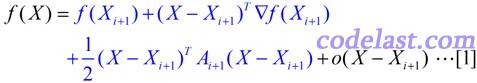
忽略高阶无穷小部分,只看前面3项,其中A为目标函数的Hessian矩阵。此式等号两边对X求导,可得:
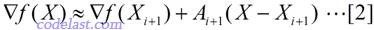
于是,当 X=Xi 时,将[2]式两边均左乘Ai+1-1,有:
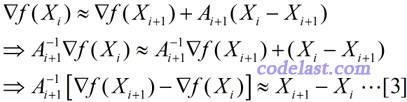
上式左右两边近似相等,但如果我们把它换成等号,并且用另一个矩阵H来代替上式中的A-1,则得到:
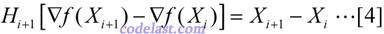
方程[4]就是拟牛顿方程,其中的矩阵H,就是Hessian矩阵的逆矩阵的一个近似矩阵.在迭代过程中生成的矩阵序列H0,H1,H2,……中,每一个矩阵Hi+1,都是由前一个矩阵Hi修正得到的。DFP算法的修正方法如下,设:
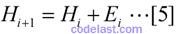
再设:
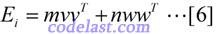
其中,m和n均为实数,v和w均为N维向量。将[6]代入[5]式,再将[5]式代入[4]式,可得:
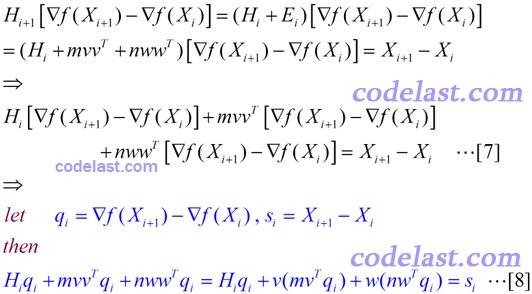
得到的m,n,v,w值如下:
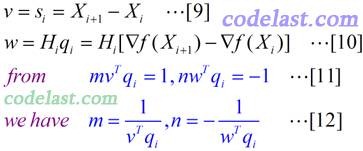
将[8]~[11]代入[6]式,然后再将[6]代入[5]式,就得到了Hessian矩阵的逆矩阵的近似阵H的计算方法:
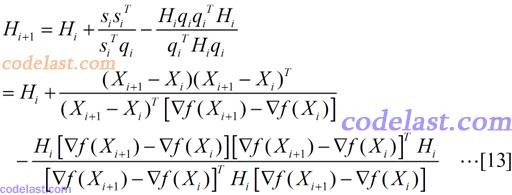
通过上述描述,DFP算法的流程大致如下:
已知初始正定矩阵H0,从一个初始点开始(迭代),用式子

来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序终止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序终止条件。
值得注意的是,矩阵H正定是使目标函数值下降的条件,所以,它保持正定性很重要。可以证明,矩阵H保持正定的充分必要条件是:

在迭代过程中,这个条件也是容易满足的。
b. BFGS算法
BFGS算法和DFP算法有些相似,但是形式上更加复杂一些。BFGS算法目前仍然被认为是最好的拟牛顿算法。BFGS算法中矩阵H的计算公式如下所示:
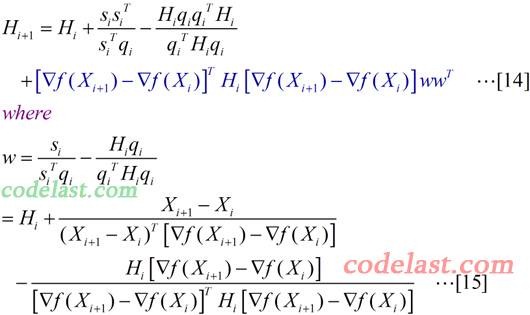
在[14]式中的最后一项(蓝色部分)就是BFGS比DFP多出来的部分,其中w是一个n×1的向量。
在目标函数为二次型时,无论是DFP还是BFGS——也就是说,无论[14]式中有没有最后一项——它们均可以使矩阵H在n步之内收敛于A-1。
代码实验:
网络上面有很多BFGS的实现算法,用的比较多的是c++实现的源码库libbfgs,http://www.chokkan.org/software/liblbfgs/.
网上编译即可以使用。
本文以求解 f(x1,x2) = 100(x2-x1^2)^2 + (1-x1)^2为例,对比matlab和libbfgs的结果。
在matlab中求解该优化问题,可得如下结果:
运用libbfgs库,编程实现优化问题:
#include <stdio.h> #include <lbfgs.h>
//优化回调函数,每次迭代运行,在这里设置目标函数和梯度方程
static lbfgsfloatval_t evaluate(
void *instance,
const lbfgsfloatval_t *x,
lbfgsfloatval_t *g,
const int n,
const lbfgsfloatval_t step
)
{
lbfgsfloatval_t fx = 0.0;
//计算目标函数
fx = 100 * (x[1] - x[0] * x[0]) * (x[1] - x[0] * x[0]) + (1 - x[0]) * (1 - x[0]);
//计算梯度方程
g[0] = -(400 * x[0] * (x[1] - x[0] * x[0]) + 2 * (1 - x[0]));
g[1] = 200 * (x[1] - x[0] * x[0]);
return fx;
}//迭代回调函数,每次迭代可以用来输出迭代求解获得的值
static int progress(
void *instance,
const lbfgsfloatval_t *x,
const lbfgsfloatval_t *g,
const lbfgsfloatval_t fx,
const lbfgsfloatval_t xnorm,
const lbfgsfloatval_t gnorm,
const lbfgsfloatval_t step,
int n,
int k,
int ls
)
{//输出当前迭代次数,目标值,x1,x2的值以及目标函数和梯度的误差二范数等
printf("Iteration %d:\n", k);
printf(" fx = %f, x[0] = %f, x[1] = %f\n", fx, x[0], x[1]);
printf(" xnorm = %f, gnorm = %f, step = %f\n", xnorm, gnorm, step);
printf("\n");
return 0;
}//定义当前参数的个数
#define N 2
int main(int argc, char *argv[])
{
lbfgsfloatval_t fx; //目标函数
lbfgsfloatval_t *x = lbfgs_malloc(N); //分配变量空间
lbfgs_parameter_t param; //参数值
if (x == NULL) {
printf("ERROR: Failed to allocate a memory block for variables.\n");
return 1;
}
/* 初始化参数. */
x[0] = -1.2;
x[1] = 2;
/* 初始化 L-BFGS 优化算法的设置参数. */
lbfgs_parameter_init(¶m);
/*
优化求解
*/
ret = lbfgs(N, x, &fx, evaluate, progress, NULL, ¶m);
/* 输出最终的优化结果. */
printf("L-BFGS optimization terminated with status code = %d\n", ret);
printf(" fx = %f, x[0] = %f, x[1] = %f\n", fx, x[0], x[1]);
lbfgs_free(x); //释放变量空间
return 0;
}运行程序:
对比可得,L-BFGS程序经过36次迭代即可求得最优解,且跟matlab的求解结果一致。

相关文章推荐
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 对动态规划DP求解最优化问题的理解及应满足的条件
- 深入浅出数据分析:最优化-用Excel求解一个线性规划问题
- 使用redis缓存数据需要注意的问题以及个人的一些思考和理解
- Application的用法以及安卓入口问题的理解
- 理解AIDL原理以及系统生成的源码
- 理解em,rem以及rem的失效问题
- MATLAB 求解最优化问题
- 利用maven整合SSH步骤以及源码解析可以更好的深入理解
- JAVA CAS 理解以及ABA问题
- Linux 从源码编译安装 OpenSSH以及各问题解决