Performance Measures and Evaluation on IR System
2014-02-28 13:30
288 查看
All common measures generally assume a ground truth notion of relevance: every document is known to be either relevant or non-relevance to a particular query.
1. Precision and Recall
Precision is the fraction of the documents retrieved that are relevant to the user’s information need.
Recall is the fraction of the documents that are relevant to the query that are successful retrieved.

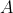
: Retrieved documents

Relevant documents

So, we will have

2. Fall-out
Fall-out is the proportion of non-relevant documents that are retrieved, out of all non-relevant documents available:

It can be looked at as the probability that a non-relevant document is retrieved by a query.
3. F-measure
F-measure or F-score is the weighted harmonic mean of precision and recall.
The traditional F-measure or balanced F-score is:
%7D)
The general formula for non-negative real
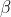
is
%7B%5Ccdot%7Dprecision%7B%5Ccdot%7Drecall%7D%7B%5Cleft(%5Cbeta%5E2%7B%5Ccdot%7Dprecision+recall%5Cright)%7D)
4. Average Precision
By computing a precision and recall at every position in the ranked sequence of documents, one can plot a precision-recall curve, plotting precision as
)
a function of recall

.
Average Precision computes the average value of over the interval from
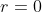
to
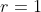
.
%5C,%5Cmathrm%7Bd%7Dx)
This integral is in practice replaced with a finite sum over every position in the ranked sequence of documents.
%5CDetar(k))
Where k is the rank in the sequence of retrieved documents, n is the number of retrieved documents,P(k) is the precision at cut-off k in the list, and
)
is the change in recall from items k-1 to k.
5. R-Precision
Precision at

position in the ranking of results for a query that has R relevant documents.
6. Mean average precision
Mean average precision for a set of queries is the mean of the average precision scores for each query.
%7D%7BQ%7D)
Where Q is the number of queries.
7. Discounted cumulative gain
DCG uses a graded relevance scale of documents from the results set to evaluate the usefulness or gain, of a document based on its position in the result list.
The DCG accumulated at a particular rank position p is defined as:

Precision and Recall
1. Information Retrieval
Precision is defined as the number of relevant documents retrieved by a search divided by the total number of documents retrieved by that search.
Recall is defined as the number of relevant documents retrieved by a search divided by the total number of existing relevant documents.
2. Classification task
Precision is defined as the number of true positives divided by the total number of elements labeled as belonging to the positive class
(i.e.the sum of true positives and false positives). Precision is also called positive predict value (PPV).
Recall is defined as the number of true positives divided by the total number of elements that actually belong to positive class (i.e.the
sum of true positives and false negatives). Recall is also called sensitivity or true positive rate.
3. Relationship
Often, there is an inverse relationship between precision and recall.Usually, precision and recall scores are not discussed in isolation. Instead,either values for one measure are compared for a fixed level at the other measure
or both are combined into a single measure (such as F-measure).
Confusion Matrix(contingency table)
Each column of the matrix represents the instance in a predicted class, while each row represents the instances in an actual class.
Confusion Matrix allows more detailed analysis than accuracy. Accuracy is not a reliable metric for the real performance of a classifier, because it will yield misleading results if the data set is unbalanced (that is, when the
number of samples in different classes vary greatly).
Reference:
[1] http://en.wikipedia.org/wiki/Information_retrieval
[2] http://en.wikipedia.org/wiki/Precision_and_recall
[3] http://en.wikipedia.org/wiki/Confusion_matrix
1. Precision and Recall
Precision is the fraction of the documents retrieved that are relevant to the user’s information need.
Recall is the fraction of the documents that are relevant to the query that are successful retrieved.
: Retrieved documents
Relevant documents
So, we will have
2. Fall-out
Fall-out is the proportion of non-relevant documents that are retrieved, out of all non-relevant documents available:
It can be looked at as the probability that a non-relevant document is retrieved by a query.
3. F-measure
F-measure or F-score is the weighted harmonic mean of precision and recall.
The traditional F-measure or balanced F-score is:
The general formula for non-negative real
is
4. Average Precision
By computing a precision and recall at every position in the ranked sequence of documents, one can plot a precision-recall curve, plotting precision as
a function of recall
.
Average Precision computes the average value of over the interval from
to
.
This integral is in practice replaced with a finite sum over every position in the ranked sequence of documents.
Where k is the rank in the sequence of retrieved documents, n is the number of retrieved documents,P(k) is the precision at cut-off k in the list, and
is the change in recall from items k-1 to k.
5. R-Precision
Precision at
position in the ranking of results for a query that has R relevant documents.
6. Mean average precision
Mean average precision for a set of queries is the mean of the average precision scores for each query.
Where Q is the number of queries.
7. Discounted cumulative gain
DCG uses a graded relevance scale of documents from the results set to evaluate the usefulness or gain, of a document based on its position in the result list.
The DCG accumulated at a particular rank position p is defined as:
Precision and Recall
1. Information Retrieval
Precision is defined as the number of relevant documents retrieved by a search divided by the total number of documents retrieved by that search.
Recall is defined as the number of relevant documents retrieved by a search divided by the total number of existing relevant documents.
2. Classification task
Precision is defined as the number of true positives divided by the total number of elements labeled as belonging to the positive class
(i.e.the sum of true positives and false positives). Precision is also called positive predict value (PPV).
Recall is defined as the number of true positives divided by the total number of elements that actually belong to positive class (i.e.the
sum of true positives and false negatives). Recall is also called sensitivity or true positive rate.
3. Relationship
Often, there is an inverse relationship between precision and recall.Usually, precision and recall scores are not discussed in isolation. Instead,either values for one measure are compared for a fixed level at the other measure
or both are combined into a single measure (such as F-measure).
Confusion Matrix(contingency table)
Each column of the matrix represents the instance in a predicted class, while each row represents the instances in an actual class.
Confusion Matrix allows more detailed analysis than accuracy. Accuracy is not a reliable metric for the real performance of a classifier, because it will yield misleading results if the data set is unbalanced (that is, when the
number of samples in different classes vary greatly).
Reference:
[1] http://en.wikipedia.org/wiki/Information_retrieval
[2] http://en.wikipedia.org/wiki/Precision_and_recall
[3] http://en.wikipedia.org/wiki/Confusion_matrix

相关文章推荐
- Notes on <High Performance MySQL> -- Ch7: Operating System and Hardware Optimization
- 论文原稿:Research on the Status Quo and System architecture of the Web Information Resource Evaluation
- Handbook of Research on User Interface Design and Evaluation for Mobile Technology
- native and java performance on android
- Linux System and Performance Monitoring(Memory篇)
- Installing the Graphical Window System (X.org-X11) and the Default Desktop Environment on CentOS 6
- Queueing Networks and Markov Chains : Modeling and Performance Evaluation with Computer Science Appl
- 在64位系统下安装32位ODBC驱动问题How to install and configure a 32 bit ODBC driver on a 64 bit Operating System?
- native and java performance on android
- Linux System and Performance Monitoring(I/O篇)
- 输入法论文阅读一:Effects of Language Modeling and its Personalization on Touchscreen Typing Performance
- [转] KVM storage performance and cache settings on Red Hat Enterprise Linux 6.2
- [论文笔记] Evaluation on crowdsourcing research: Current status and future direction (Information Systems Frontiers, 2012) (第一部分)
- hadoop System times on machines may be out of sync. Check system time and time zones.
- Linux - Sysstat [ All-in-One System Performance and Usage Activity Monitoring Tool For Linux]
- Linux System and Performance Monitoring(Network篇)
- How to Setup NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu
- How to Setup NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu
- Performance Evaluation and Benchmarking