python基于mysql的用户认证
2014-02-28 11:07
288 查看
free 详解
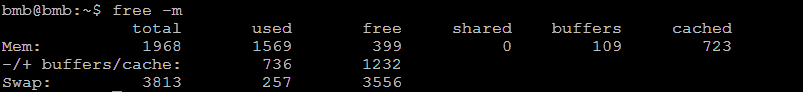
1. total: 内存总数
2. used:已经使用的内存数
3. free: 空闲的内存数
4. shared: 多个进程共享的内存总额
5. -buffers/cache: (已用)的内存数,即used-buffers-cached //反映实际被用掉的内存数
6. +buffers/cache: (可用)的内存数,即free+buffers+cached //反映可以使用的内存数
可用内存的计算公式为:
可用内存=free+buffers+cached,即399M+109M+723M=1232M
内存总数与已使用内存数和空闲内存数的关系:
total(1968M)=used(1569M)+free(399M)
注:观察Linux的内存使用情况时,只要没有发现用swap的交换空间,就不用担心自己的内存太少;如果常常看到swap用了很多,那么就要考虑增加物理内存了。这也是在Linux服务器上看内存是否够用的标准。
buffer与cache的区别
buffer与cache操作的对象不一样。
buffer(缓冲)是为了提高内存和硬盘(或其它I/O设备)之间的数据交换的速度而设计的。
cache(缓存)是为了提高cpu和内存之间的数据交换而设计的,也就是平常见到的一级缓存、二级缓存、三级缓存等。
cpu在执行程序所用的指令和读数据都是针对内存的,也就是从内存中取得的。犹豫内存的读写速度慢,为了提高cpu和内存之间的数据交换的速度,在cpu 和内存之间增加了cache,他的速度比内存块,但是造价高,又由于在cpu内不能集成太对集成电路,所以一般cache比较小,以后intel等公司为 了进一步提高速度,又增加了二级cache,甚至三级cache,它是根据程序的局部性原理而设计的,就是cpu执行的指令和访问的数据往往在集中的某一 块,所以把这块内容放入cache后,cpu就不用再访问内存了,这就提高了访问速度。当然若cache中没有cpu所需要的内容,还是要访问内存的。
缓冲(buffers) 是根据磁盘的读写设计的,把分散的写操作集中进行,减少了磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定期清空缓冲内容(既写 入磁盘),也可以通过sync命令手动清空缓冲。举个例子吧:我这里有一个ext2的U盘,我往里面copy一个3M的MP3.但U盘的灯没有跳动,过了 一会儿(或者手动输入sync)U盘的灯就跳动起来了。卸载设备时会清空缓冲,所以有些时候卸载一个设备要等上几秒钟。
修改/etc/sysctl.conf中的vm.swappiness右边的数字可以在下次开机时调节swap使用策略。该数字范围是0-100,数字越大越倾向于使用swap。默认为60,可以改一下试试。--两者都是RAM中的数据。
简单来说,buffer是即将要写入磁盘的,而cache是被从磁盘中读出来的。
buffer是由各种进程分配的,被用在如输入队列等方面。一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程就先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。
本文出自 “opensource” 博客,请务必保留此出处http://bmbwolf.blog.51cto.com/2684204/970338
1. total: 内存总数
2. used:已经使用的内存数
3. free: 空闲的内存数
4. shared: 多个进程共享的内存总额
5. -buffers/cache: (已用)的内存数,即used-buffers-cached //反映实际被用掉的内存数
6. +buffers/cache: (可用)的内存数,即free+buffers+cached //反映可以使用的内存数
可用内存的计算公式为:
可用内存=free+buffers+cached,即399M+109M+723M=1232M
内存总数与已使用内存数和空闲内存数的关系:
total(1968M)=used(1569M)+free(399M)
注:观察Linux的内存使用情况时,只要没有发现用swap的交换空间,就不用担心自己的内存太少;如果常常看到swap用了很多,那么就要考虑增加物理内存了。这也是在Linux服务器上看内存是否够用的标准。
buffer与cache的区别
buffer与cache操作的对象不一样。
buffer(缓冲)是为了提高内存和硬盘(或其它I/O设备)之间的数据交换的速度而设计的。
cache(缓存)是为了提高cpu和内存之间的数据交换而设计的,也就是平常见到的一级缓存、二级缓存、三级缓存等。
cpu在执行程序所用的指令和读数据都是针对内存的,也就是从内存中取得的。犹豫内存的读写速度慢,为了提高cpu和内存之间的数据交换的速度,在cpu 和内存之间增加了cache,他的速度比内存块,但是造价高,又由于在cpu内不能集成太对集成电路,所以一般cache比较小,以后intel等公司为 了进一步提高速度,又增加了二级cache,甚至三级cache,它是根据程序的局部性原理而设计的,就是cpu执行的指令和访问的数据往往在集中的某一 块,所以把这块内容放入cache后,cpu就不用再访问内存了,这就提高了访问速度。当然若cache中没有cpu所需要的内容,还是要访问内存的。
缓冲(buffers) 是根据磁盘的读写设计的,把分散的写操作集中进行,减少了磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定期清空缓冲内容(既写 入磁盘),也可以通过sync命令手动清空缓冲。举个例子吧:我这里有一个ext2的U盘,我往里面copy一个3M的MP3.但U盘的灯没有跳动,过了 一会儿(或者手动输入sync)U盘的灯就跳动起来了。卸载设备时会清空缓冲,所以有些时候卸载一个设备要等上几秒钟。
修改/etc/sysctl.conf中的vm.swappiness右边的数字可以在下次开机时调节swap使用策略。该数字范围是0-100,数字越大越倾向于使用swap。默认为60,可以改一下试试。--两者都是RAM中的数据。
简单来说,buffer是即将要写入磁盘的,而cache是被从磁盘中读出来的。
buffer是由各种进程分配的,被用在如输入队列等方面。一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程就先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。
本文出自 “opensource” 博客,请务必保留此出处http://bmbwolf.blog.51cto.com/2684204/970338

相关文章推荐
- Python读书笔记第十二章:异常
- Python读书笔记第十一章:输入/输出
- 使用python实现观察者思想
- python urllib2教程
- python入门地址
- Python基础函数学习笔记(三)
- 深入学习python(三) 闭包(Decorator)与装饰器(Closure)
- python抓取网页中的图片示例
- windows下python模拟鼠标点击和键盘输示例
- python发邮件实例
- python调用sendcloud接口实现邮件批量发送收取及url回调 推荐
- How to Install Pygame to Python 3 on Ubuntu
- 我对李杰的python YY公开课不满意
- Python初体验:三句话写个刷微博、博客、空间等的小爬虫
- Python中的除法
- Exercise 6: 字符串
- python中文json串创建与解析
- 优秀Python学习资源收集汇总(强烈推荐)
- python django 获取用户IP地址的方法
- python matploitlib 学习笔记(一)