用Hadoop构建电影推荐系统及其若干解释
2014-02-26 19:41
381 查看
参考文章:http://blog.fens.me/hadoop-mapreduce-recommend/
最近学习hadoop,用hadoop实现电影推荐系统,详细步骤请查看上面的链接。在最后一步计算推荐值时,对代码什么不解,一直不明白代码的意思,经过好几天的学习,终于弄懂了,随手把自己的理解记录下来以便以后回顾。hadoop版本是1.1.2。
最后一步的代码如下:
package com.hadoop.mapreduce.examples.movie_recommendation;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ComputeRecommend {
private final static Map<Integer, List> cooccurrenceMatrix = new HashMap<Integer, List>();
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = value.toString().split(",");
System.out.println(tokens[0]);
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0].trim());
int itemID2 = Integer.parseInt(v1[1].trim());
int num = Integer.parseInt(tokens[1].trim());
List list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
for (Object cob : cooccurrenceMatrix.get(itemID)) {
Cooccurrence co = (Cooccurrence)cob;
context.write(new Text(String.valueOf(userID)), new Text(co.getItemID2() + "," + pref * co.getNum()));
}
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, Text> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
Map<String, Double> result = new HashMap<String, Double>();
Iterator it = values.iterator();
while (it.hasNext()) {
String[] str = it.next().toString().split(",");
if (result.containsKey(str[0])) {
result.put(str[0], result.get(str[0]) + Double.parseDouble(str[1]));
} else {
result.put(str[0], Double.parseDouble(str[1]));
}
}
Iterator iter = result.keySet().iterator();
while (iter.hasNext()) {
String itemID = (String) iter.next();
double score = result.get(itemID);
context.write(key, new Text(itemID + "," + score));
}
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
// 创建作业
Job job = new Job(conf, "movie_recommendation_computerecommend");
job.setJarByClass(MovieTogether.class);
// 设置mr
job.setMapperClass(MyMapper.class);
// job.setReducerClass(MyReducer.class);
// 设置输出类型,和Context上下文对象write的参数类型一致
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("/test/computerecommend"), new Path("/test/computerecommend2"));
FileOutputFormat.setOutputPath(job, new Path("/out/movie_recommendation/computerecommend"));
// 执行
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class Cooccurrence {
private int itemID1;
private int itemID2;
private int num;
public Cooccurrence(int itemID1, int itemID2, int num) {
super();
this.itemID1 = itemID1;
this.itemID2 = itemID2;
this.num = num;
}
public int getItemID1() {
return itemID1;
}
public void setItemID1(int itemID1) {
this.itemID1 = itemID1;
}
public int getItemID2() {
return itemID2;
}
public void setItemID2(int itemID2) {
this.itemID2 = itemID2;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
其中/test/computerecommend的部分数据为:
101,5:4.0
101,1:5.0
101,2:2.0
101,3:2.0
101,4:5.0
102,1:3.0
102,5:3.0
102,2:2.5
103,2:5.0
103,5:2.0
103,1:2.5
103,4:3.0
104,2:2.0
104,5:4.0
……(完整数据请查看http://blog.fens.me/hadoop-mapreduce-recommend/,这里我修改了下数据格式)
和/test/computerecommend2中的部分数据为:
101:101,5
101:102,3
101:103,4
101:104,4
101:105,2
101:106,2
101:107,1
102:101,3
102:102,3
102:103,3
102:104,2
102:105,1
102:106,1
103:101,4
……(完整数据请查看http://blog.fens.me/hadoop-mapreduce-recommend/,这里我修改了下数据格式)
map函数执行完后,得到的部分数据:
……
2 105,5.0
2 104,15.0
2 103,20.0
3 107,5.0
3 101,10.0
3 102,6.0
3 103,8.0
3 104,8.0
3 105,4.0
3 106,4.0
3 107,2.0
3 101,16.0
3 102,8.0
3 103,12.0
3 104,16.0
3 105,8.0
3 106,8.0
3 107,4.0
3 101,9.0
3 102,4.5
3 103,4.5
3 104,9.0
3 105,9.0
3 106,4.5
3 107,4.5
3 101,5.0
3 104,5.0
3 105,5.0
……
这些数据是怎么得到的呢?如下图所示,A矩阵是电影同现矩阵,B矩阵是用户3对电影的评分矩阵。经过对基于物品的协同过滤算法的研究,我觉得A矩阵即同现矩阵中的各个值代表的就是两两电影之间的相似度,这是这种相似度的表示略为简单,也不准确。具体可以参靠文章http://blog.csdn.net/whkjlcw/article/details/19967873
矩阵 A 矩阵B 矩阵C
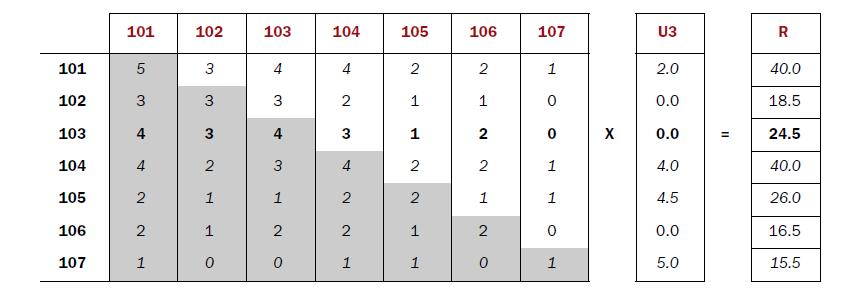
经过上述的讲解之后,我们再回到代码部分。其实map函数分为两个方面,一方面是对用户评分矩阵进行处理,一方面是对电影同现矩阵进行处理。首先我们来看对电影同现矩阵的处理。
String[] tokens = value.toString().split(",");
System.out.println(tokens[0]);
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0].trim());
int itemID2 = Integer.parseInt(v1[1].trim());
int num = Integer.parseInt(tokens[1].trim());
List list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
我们拿出一条数据按照上述代码进行分析:103:101,4。其实这条数据的意思是编号为103的电影和101的电影共同出现了4次,即相似度为4.经过上述处理后,cooccurrenceMatrix(定义成一个Map,数据格式是<Integer,List>)中存有如下格式的数据:key为103,value为<103,101,4>。类似的经过处理后数据变成如下格式:
103:101,4
103:102,3 key value
103:103,4 => 103 <103,101,4> <103,102,3> <103,103,4> <103,104,3> <103,105,3> <103,106,2>
103:104,3
103:105,1
103:106,2
再看对评分矩阵的处理:
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
for (Object cob : cooccurrenceMatrix.get(itemID)) {
Cooccurrence co = (Cooccurrence)cob;
context.write(new Text(String.valueOf(userID)), new Text(co.getItemID2() + "," + pref * co.getNum()));
}
}
拿出一条数据进行分析:103,2:5.0。即用户2对电影103的评分是5.0.按照代码分析,在cooccurrenceMatrix矩阵中取出其中key为103的value值即为<103,101,4> <103,102,3> <103,103,4> <103,104,3> <103,105,3> <103,106,2>,往文件中写入:
2 101,20.0(即5.0*4)
2 102,15.0(即5.0*3)
2 103,20.0(即5.0*4)
……
把103电影推荐给用户3的分数是这样算出来的,
map
101,101,5 101,3,2.0 => 3,101,5*2.0
101,102,3 101,3,2.0 => 3,102,3*2.0
101,103,4 101,3:2.0 => 3,103,4*2.0=8.0
……
102,101,3 102,3,0.0 => 3,101,3*0.0
102,102,3 102,3,0.0 => 3,102,3*0.0
102,103,3 102,3,0.0 => 3,103,3*0.0=0.0
……
103,101,4 103,3,0.0 => 3,101,4*0.0
103,102,3 103,3,0.0 => 3,102,3*0.0
103,103,4 103,3,0.0 => 3,103,4*0.0=0.0
……
104,101,4 104,3,4.0 => 3,101,4*4.0
104,102,2 104,3,4.0 => 3,102,2*4.0
104,103,3 104,3,4.0 => 3,103,3*4.0=12.0
……
105,101,2 105,3,4.5 => 3,101,4*4.5
105,102,1 105,3,4.5 => 3,102,2*4.5
105,103,1 105,3,4.5 => 3,103,1*4.5=4.5
……
106,101,2 104,3,4.0 => 3,101,2*4.0
106,102,1 104,3,4.0 => 3,102,1*4.0
106,103,2 102,3,5.0 => 3,103,2*0.0=0.0
……
107,101,1 104,3,4.0 => 3,101,4*4.0
107,102,0 104,3,4.0 => 3,102,2*4.0
107,103,0 107,3,5.0 => 3,103,0*5.0=0.0
……
红色字体就是计算103推荐给用户3的分数时所涉及到的数据,很明显 reduce => 3,103,24.5
总结:最重要的是理解如何利用MapReduce对数据进行处理,选择合适的key值再利用程序本身的reduce程序。我一开始想到的是如何使用MapReduce并行计算矩阵的乘法,但在这里并没有利用到这个。
最近学习hadoop,用hadoop实现电影推荐系统,详细步骤请查看上面的链接。在最后一步计算推荐值时,对代码什么不解,一直不明白代码的意思,经过好几天的学习,终于弄懂了,随手把自己的理解记录下来以便以后回顾。hadoop版本是1.1.2。
最后一步的代码如下:
package com.hadoop.mapreduce.examples.movie_recommendation;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ComputeRecommend {
private final static Map<Integer, List> cooccurrenceMatrix = new HashMap<Integer, List>();
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = value.toString().split(",");
System.out.println(tokens[0]);
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0].trim());
int itemID2 = Integer.parseInt(v1[1].trim());
int num = Integer.parseInt(tokens[1].trim());
List list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
for (Object cob : cooccurrenceMatrix.get(itemID)) {
Cooccurrence co = (Cooccurrence)cob;
context.write(new Text(String.valueOf(userID)), new Text(co.getItemID2() + "," + pref * co.getNum()));
}
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, Text> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
Map<String, Double> result = new HashMap<String, Double>();
Iterator it = values.iterator();
while (it.hasNext()) {
String[] str = it.next().toString().split(",");
if (result.containsKey(str[0])) {
result.put(str[0], result.get(str[0]) + Double.parseDouble(str[1]));
} else {
result.put(str[0], Double.parseDouble(str[1]));
}
}
Iterator iter = result.keySet().iterator();
while (iter.hasNext()) {
String itemID = (String) iter.next();
double score = result.get(itemID);
context.write(key, new Text(itemID + "," + score));
}
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
// 创建作业
Job job = new Job(conf, "movie_recommendation_computerecommend");
job.setJarByClass(MovieTogether.class);
// 设置mr
job.setMapperClass(MyMapper.class);
// job.setReducerClass(MyReducer.class);
// 设置输出类型,和Context上下文对象write的参数类型一致
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("/test/computerecommend"), new Path("/test/computerecommend2"));
FileOutputFormat.setOutputPath(job, new Path("/out/movie_recommendation/computerecommend"));
// 执行
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class Cooccurrence {
private int itemID1;
private int itemID2;
private int num;
public Cooccurrence(int itemID1, int itemID2, int num) {
super();
this.itemID1 = itemID1;
this.itemID2 = itemID2;
this.num = num;
}
public int getItemID1() {
return itemID1;
}
public void setItemID1(int itemID1) {
this.itemID1 = itemID1;
}
public int getItemID2() {
return itemID2;
}
public void setItemID2(int itemID2) {
this.itemID2 = itemID2;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
其中/test/computerecommend的部分数据为:
101,5:4.0
101,1:5.0
101,2:2.0
101,3:2.0
101,4:5.0
102,1:3.0
102,5:3.0
102,2:2.5
103,2:5.0
103,5:2.0
103,1:2.5
103,4:3.0
104,2:2.0
104,5:4.0
……(完整数据请查看http://blog.fens.me/hadoop-mapreduce-recommend/,这里我修改了下数据格式)
和/test/computerecommend2中的部分数据为:
101:101,5
101:102,3
101:103,4
101:104,4
101:105,2
101:106,2
101:107,1
102:101,3
102:102,3
102:103,3
102:104,2
102:105,1
102:106,1
103:101,4
……(完整数据请查看http://blog.fens.me/hadoop-mapreduce-recommend/,这里我修改了下数据格式)
map函数执行完后,得到的部分数据:
……
2 105,5.0
2 104,15.0
2 103,20.0
3 107,5.0
3 101,10.0
3 102,6.0
3 103,8.0
3 104,8.0
3 105,4.0
3 106,4.0
3 107,2.0
3 101,16.0
3 102,8.0
3 103,12.0
3 104,16.0
3 105,8.0
3 106,8.0
3 107,4.0
3 101,9.0
3 102,4.5
3 103,4.5
3 104,9.0
3 105,9.0
3 106,4.5
3 107,4.5
3 101,5.0
3 104,5.0
3 105,5.0
……
这些数据是怎么得到的呢?如下图所示,A矩阵是电影同现矩阵,B矩阵是用户3对电影的评分矩阵。经过对基于物品的协同过滤算法的研究,我觉得A矩阵即同现矩阵中的各个值代表的就是两两电影之间的相似度,这是这种相似度的表示略为简单,也不准确。具体可以参靠文章http://blog.csdn.net/whkjlcw/article/details/19967873
矩阵 A 矩阵B 矩阵C
经过上述的讲解之后,我们再回到代码部分。其实map函数分为两个方面,一方面是对用户评分矩阵进行处理,一方面是对电影同现矩阵进行处理。首先我们来看对电影同现矩阵的处理。
String[] tokens = value.toString().split(",");
System.out.println(tokens[0]);
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0].trim());
int itemID2 = Integer.parseInt(v1[1].trim());
int num = Integer.parseInt(tokens[1].trim());
List list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
我们拿出一条数据按照上述代码进行分析:103:101,4。其实这条数据的意思是编号为103的电影和101的电影共同出现了4次,即相似度为4.经过上述处理后,cooccurrenceMatrix(定义成一个Map,数据格式是<Integer,List>)中存有如下格式的数据:key为103,value为<103,101,4>。类似的经过处理后数据变成如下格式:
103:101,4
103:102,3 key value
103:103,4 => 103 <103,101,4> <103,102,3> <103,103,4> <103,104,3> <103,105,3> <103,106,2>
103:104,3
103:105,1
103:106,2
再看对评分矩阵的处理:
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
for (Object cob : cooccurrenceMatrix.get(itemID)) {
Cooccurrence co = (Cooccurrence)cob;
context.write(new Text(String.valueOf(userID)), new Text(co.getItemID2() + "," + pref * co.getNum()));
}
}
拿出一条数据进行分析:103,2:5.0。即用户2对电影103的评分是5.0.按照代码分析,在cooccurrenceMatrix矩阵中取出其中key为103的value值即为<103,101,4> <103,102,3> <103,103,4> <103,104,3> <103,105,3> <103,106,2>,往文件中写入:
2 101,20.0(即5.0*4)
2 102,15.0(即5.0*3)
2 103,20.0(即5.0*4)
……
把103电影推荐给用户3的分数是这样算出来的,
map
101,101,5 101,3,2.0 => 3,101,5*2.0
101,102,3 101,3,2.0 => 3,102,3*2.0
101,103,4 101,3:2.0 => 3,103,4*2.0=8.0
……
102,101,3 102,3,0.0 => 3,101,3*0.0
102,102,3 102,3,0.0 => 3,102,3*0.0
102,103,3 102,3,0.0 => 3,103,3*0.0=0.0
……
103,101,4 103,3,0.0 => 3,101,4*0.0
103,102,3 103,3,0.0 => 3,102,3*0.0
103,103,4 103,3,0.0 => 3,103,4*0.0=0.0
……
104,101,4 104,3,4.0 => 3,101,4*4.0
104,102,2 104,3,4.0 => 3,102,2*4.0
104,103,3 104,3,4.0 => 3,103,3*4.0=12.0
……
105,101,2 105,3,4.5 => 3,101,4*4.5
105,102,1 105,3,4.5 => 3,102,2*4.5
105,103,1 105,3,4.5 => 3,103,1*4.5=4.5
……
106,101,2 104,3,4.0 => 3,101,2*4.0
106,102,1 104,3,4.0 => 3,102,1*4.0
106,103,2 102,3,5.0 => 3,103,2*0.0=0.0
……
107,101,1 104,3,4.0 => 3,101,4*4.0
107,102,0 104,3,4.0 => 3,102,2*4.0
107,103,0 107,3,5.0 => 3,103,0*5.0=0.0
……
红色字体就是计算103推荐给用户3的分数时所涉及到的数据,很明显 reduce => 3,103,24.5
总结:最重要的是理解如何利用MapReduce对数据进行处理,选择合适的key值再利用程序本身的reduce程序。我一开始想到的是如何使用MapReduce并行计算矩阵的乘法,但在这里并没有利用到这个。

相关文章推荐
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 【hadoop2.x】构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 转】用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- hadoop实例--用Hadoop构建电影推荐系统
- hadoop1-构建电影推荐系统
- 【hadoop2.x】构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用Hadoop构建电影推荐系统
- 用 Hadoop 构建电影推荐系统 之 总结
- 用Hadoop构建电影推荐系统
- hadoop学习-Netflix电影推荐系统
- 《Hadoop进阶》利用Hadoop构建豆瓣图书推荐系统
- 电影推荐系统代码详细解释