lucene源代码学习之 lucene的经典打分过程
Lucene中默认的打分模型是VSM(Vector Space Model),其打分公式如下:
 看到很多文章都是对这个公式进行解析,但问题的关键在于看了一大段的解析之后,依然不懂其中的细节。我们直接从例子入手:
看到很多文章都是对这个公式进行解析,但问题的关键在于看了一大段的解析之后,依然不懂其中的细节。我们直接从例子入手:
建立如下的索引:
publicclass LuceneDemo {
Directory d;
Analyzer analyzer;
public LuceneDemo() throws IOException{
d=new SimpleFSDirectory(new File("D:/lucene_test"));
analyzer=new WhitespaceAnalyzer(Version.LUCENE_42);
}
publicvoid index() throws IOException{
IndexWriterConfig conf=new IndexWriterConfig(Version.LUCENE_42, analyzer);
IndexWriter iw=new IndexWriter(d, conf);
Document doc=new Document();
doc=new Document();
doc.add(new TextField("content", "common common common term",Store.YES));
iw.addDocument(doc);
doc=new Document();
doc.add(new TextField("content", "common common term term",Store.YES));
iw.addDocument(doc);
doc=new Document();
doc.add(new TextField("content", "common term term term",Store.YES));
iw.addDocument(doc);
doc=new Document();
doc.add(new TextField("content", "term term term term",Store.YES));
iw.addDocument(doc);
iw.commit();
iw.close();
}
publicvoid search() throws IOException, ParseException{
IndexReader r=DirectoryReader.open(d);
IndexSearcher is=new IndexSearcher(r);
// TermQuery query=new TermQuery(new Term("content", "common"));
Query query=new QueryParser(Version.LUCENE_42, "content", analyzer).parse("common term");
TopDocs td=is.search(query, 10);
ScoreDoc[] hits=td.scoreDocs;
System.out.println("hits "+hits.length+" docs!");
Document doc;
for (int i = 0; i < hits.length; i++) {
doc=is.doc(hits[i].doc);
System.out.println(hits[i].score);
System.out.println(doc.get("content"));
}
}
publicstaticvoid main(String[] args) throws IOException, ParseException{
LuceneDemo ld=new LuceneDemo();
//ld.index();
ld.search();
}
}[p]一共插入了4篇文本:
common common common termcommon common term termcommon term term termterm term term term两个查询词:common term搜索的结果是怎样的呢?hits 4 docs!0.92219996common common common term0.89540654common common term term0.80759263common term term term0.2382957term term term term这个分值是怎么算出来了呢?
Lucene在实现上并没有完全按照公式中的我们设想的步骤来计算,而对计算顺序进行了一调整。
第一步:计算queryNorm(q)
在一次搜索过程中,此值只计算一遍,对每个文档都是同一个值,所以queryNorm(q)不影响文档间的排序,仅仅是作为query向量的归一化因子。
计算公式如下:


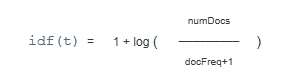
Query中一共有两个common和term两个单词,其计算的过程如下:
| numDocs[/p] | docFreq | idf | sumOfSquaredWeights | queryNorm | |
common | 4 | 3 | 1 | 1.6035059 | 0.7897047 |
term | 4 | 0.776856 |
第二步:归一化处理。
对每一个查询词,建立Weight对象,并把value=idf(t)*queryNorm*queryWeight预先存储起来。这里queryWeight的值就是idf
idf | queryNorm | queryWeight | value | |
common | 1 | 0.7897047 | 1 | 0.7897047 |
term | 0.776856 | 0.7897047 | 0.776856 | 0.4765914 |
第三步:计算coord(q,d)。
这是一个打分因子,其值取决于文档中包含查询关键词的个数。一般而言,一个文档中包含越多的查询关键词,则其打分会越高。这个计算很简单:
Coord(q,d)=overlap/maxOverlap (overlap为文档包含查询关键词的个数,maxOverlap为查询关键词的总个数,两个相同的词算两个词) lucene在实现的过程中,取了一个巧。直接把[0,maxOverlap]都计算了一遍,然后存储在数组中备用。对本例而言:一共有两个查询词,所以最多有三种结果:
文档不包含查询词 | 文档包含1个查询词 | 文档包含2个查询词 | |
coord(q,d) | 0 | 0.5 | 1 |
第四步:文档初打分。
对于query中的每个查询词分别计算tf(t in d) ,norm(t,d) 。这里需要注意的是idf(t)与文档无关;norm(t,d)是在建索引的时候就已经计算好的,计算方法见TFIDFSimilarity.
computeNorm()。其值如下:
docId | 0 | 1 | 2 | 3 |
Norm(t,d) | 0.5 | 0.5 | 0.5 | 0.5 |
这里提一下的是,norm其实与查询词无关,它只与文档的长短,更精确地说,与文档中的词数有关,Norm(t,d)=文档含词个数的倒数的平方根。由于4个文档的单词数都为4,所以,其值为0.5
tf(t in d)的计算公式如下:
 比如在文档common common common term中,common的frequency=3,所以其tf值为Math.sqrt(3),其它的值依此类推。
比如在文档common common common term中,common的frequency=3,所以其tf值为Math.sqrt(3),其它的值依此类推。
查询词 | docId | Norm(t,d) | tf(t in d) | Value=idf(t)*idf(t)*queryNorm | score=Norm*tf*value |
common | 0 | 0.5 | 1.7320508 | 0.7897047 | 0.683904329 |
1 | 0.5 | 1.4142135 | 0.558405524 | ||
2 | 0.5 | 1 | 0.39485235 | ||
3 | 0.5 | 0 | |||
term | 0 | 0.5 | 1 | 0.4765914 | 0.2382957 |
1 | 0.5 | 1.4142135 | 0.337001 | ||
2 | 0.5 | 1.7320508 | 0.412740 | ||
3 | 0.5 | 2 | 0.4765914 |
两个查询词的打分结果求和:
docId | 0 | 1 | 2 | 3 |
Score(Common) | 0.683904329 | 0.558405524 | 0.39485235 | 0 |
Score(term) | 0.2382957 | 0.337001 | 0.412740 | 0.4765914 |
Score(total) | 0.922200029 | 0.895406524 | 0.80759235 | 0.4765914 |
第五步:最终打分并排序
将第四步两个查询词的打分相加后,还有一个coord因子。除了文档3只含有一个查询词外,其它的文档都含有两个查询词,故最后的总得分为:final score=score*coord
docId | 0 | 1 | 2 | 3 |
score | 0.9222 | 0.8954 | 0.8075 | 0.4765 |
coord | 1 | 1 | 1 | 0.5 |
Final score | 0.9222 | 0.8954 | 0.8075 | 0.2382 |
第六步:将存储在优先队列中的计算结果排序返回。
这样,lucene的整个打分、排序过程就完成了。

- lucene源代码学习之 lucene的经典打分过程 推荐
- Lucene学习总结之四:Lucene索引过程分析(3)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之四:Lucene索引过程分析
- Lucene学习总结之七:Lucene搜索过程解析(3)
- 通过Lucene索引文件学习Lucene索引过程
- Lucene建立索引的过程学习
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之四:Lucene索引过程分析(4)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(8)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- 学习vc过程的经典书籍
- Lucene学习笔记: 五,Lucene搜索过程解析
- 学习外挂 -------- 成长过程(经典推荐)
- Lucene学习总结:Lucene搜索过程解析
- Lucene深入学习(7)Lucene的索引过程
- .net学习过程中一些经典链接
- Lucene学习总结之七:Lucene搜索过程解析(6)
- mysql 5.0存储过程学习总结 (经典)