hadoop的安装与配置(伪分布式模式安装)
2014-02-21 23:20
411 查看
最近偶然在研究hadoop看完网络上的配置文章居然在linux下安装成功的hadoop就把别人的文章进行说明一下,提供给需要的读者。
hadoop 的安装分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负
责存储,没有计算功能,不讲述。伪分布模式是在一台机器上模拟分布式部署,方便学
习和调试。集群模式是在多个机器上配置 hadoop,是真正的“分布式”。本文章讲述伪分布模式。
解压缩文件,并重命名为hadoop,方便后面的使用,重命名后完整路径为“/usr/local/hadoop”
解压及更名:
#tar -xzvf hadoop-1.0.4.tar.gz
#mv hadoop-1.0.4 hadoop
设置环境变量HADOOP HOME,修改文件“/etc/profile”,如图:
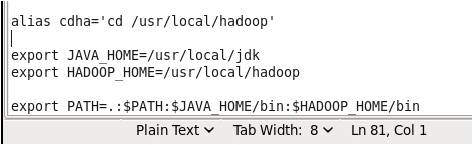
请读者与 jdk 设置时配置文件对照。这里我们设置了一个别名 cdha,可以快速转到
hadoop 的目录。
修改环境变量后,记得执行 source 命令哦。(source /etc/profile 是文件立即生效)
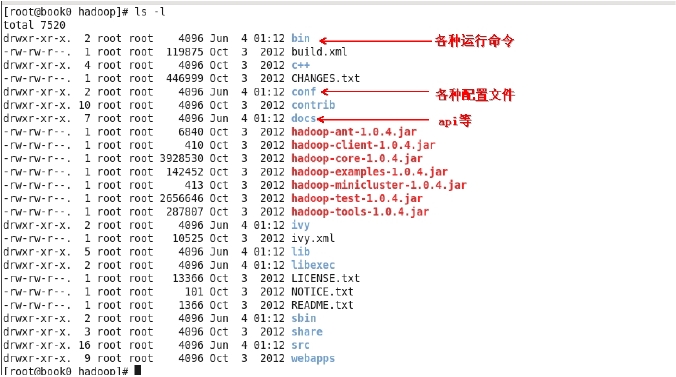
我们关注 bin 目录和 conf 目录。
$HADOOP_HOME/conf 目录下。
第一个是hadoop环境变量脚本文件hadoop-env.sh
修改第9行代码为
export JAVA_HOME=/usr/local/jdk
保存并关闭。这里设置的是 JAVA_HOME,注意去掉前面的“#”。
第二个是hadoop的核心配置文件core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>hadoop 的运行临时文件的主目录</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://book0:9000</value>
<description>HDFS 的访问路径</description>
</property>
</configuration>
第三个是hdfs配置文件hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>存储副本数</description>
</property>
</configuration>
第四个是MapReduce配置文件mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>book0:9001</value>
<description>JobTracker 的访问路径</description>
</property>
</configuration>
$HADOOP_HOME/bin/hadoop namenode –format
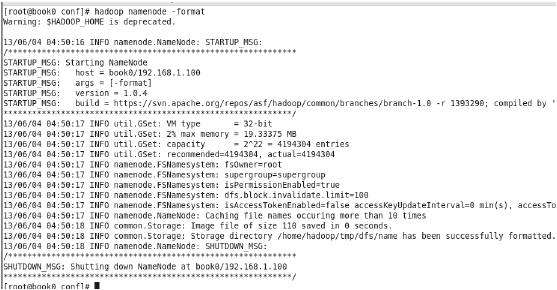
注意:只在第一次启动的时候格式化,不要每次启动都格式化。理解为我们新买了块
移动硬盘,使用之前总要格式化硬盘。
如果真的有必要再次格式化,请先把“$HADOOP_HOME/tmp”目录下的文件全部删除。
读者可以自己观察目录”$HADOOP_HOME/tmp”在格式化前后的变化情况。
格式化操作很少有出现失败的情况。如果真出现了,请检查配置是否正确
启动 hadoop 的命令脚本都在$HADOOP_HOME/bin/下,下面的所有命令都不再带有完整路
径名称。
这里讲述 hadoop 启动的三种方式:
第一种,一次性全部启动:
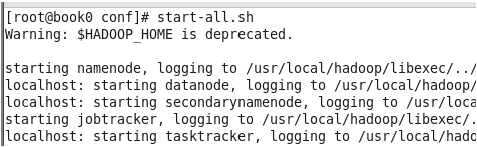
执行 start-all.sh 启动 hadoop,观察控制台的输出,见图 3-5,可以看到正在启动进程,分
别是 namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共 5 个,待执行
完毕后,并不意味着这 5 个进程成功启动,上面仅仅表示系统正在启动进程而已。
我们使用 jdk 的命令 jps 查看进程是否已经正确启动。执行以下 jps,如果看到了这 5 个
进程,见图 3-6,说明 hadoop 真的启动成功了。如果缺少一个或者多个,那就进入到“Hadoop
的常见启动错误”章节寻找原因了。
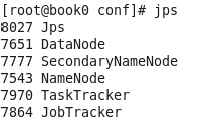
关闭 hadoop 的命令是stop-all.sh。
上面的命令是最简单的,可以一次性把所有节点都启动、关闭。除此之外,还有其他命
令,是分别启动的。
第二种,分别启动 HDFS和 MapReduce:
执行命令 start-dfs.sh,是单独启动 hdfs,见图 3-7。执行完该命令后,通过 jps 能够
看到 NameNode、DataNode、SecondaryNameNode 三个进程启动了,该命令适合于只执行 hdfs
存储不使用 MapReduce 做计算的场景。关闭的命令就是 stop-dfs.sh 了。
执行命令 start-mapred.sh,可以单独启动 MapReduce 的两个进程。关闭的命令就是
stop-mapred.sh 了。当然,也可以先启动 MapReduce,再启动 HDFS。这说明,HDFS 和MapReduce
的进程之间是互相独立的,没有依赖关系。
第三种,分别启动各个进程:
执行的命令是“hadoop-daemon.shstart [进程名称]”,这种启动方式适合于单独增加、
删除节点的情况,在安装集群环境的时候会看到。
root@book0 bin]# jps
14821 Jps
[root@book0 bin]# hadoop-daemon.sh start namenode
[root@book0 bin]# hadoop-daemon.sh start datanode
[root@book0 bin]# hadoop-daemon.sh startsecondarynamenode
[root@book0 bin]# hadoop-daemon.sh start jobtracker
[root@book0 bin]# hadoop-daemon.sh start tasktracker
[root@book0 bin]# jps
14855 NameNode
14946 DataNode
15043 SecondaryNameNode
15196 TaskTracker
15115 JobTracker
15303 Jps
至此hadoop的伪分布式安装已完成,读者接下来可以进行简单的MapReduce计算了。
(以上内容来源于网上的摘要结合自己的说明)
hadoop 的安装分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负
责存储,没有计算功能,不讲述。伪分布模式是在一台机器上模拟分布式部署,方便学
习和调试。集群模式是在多个机器上配置 hadoop,是真正的“分布式”。本文章讲述伪分布模式。
解压缩hadoop
使用winscp把软件包传输至linux下的usr/local目录下
解压及更名:
#tar -xzvf hadoop-1.0.4.tar.gz
#mv hadoop-1.0.4 hadoop
设置环境变量HADOOP HOME,修改文件“/etc/profile”,如图:
请读者与 jdk 设置时配置文件对照。这里我们设置了一个别名 cdha,可以快速转到
hadoop 的目录。
修改环境变量后,记得执行 source 命令哦。(source /etc/profile 是文件立即生效)
我们关注 bin 目录和 conf 目录。
修改配置文件
hadoop 配 置 文 件 默 认 是 本 地 模 式 , 我 们 修 改 四 个 配 置 文 件 , 这 些 文 件 都 位 于$HADOOP_HOME/conf 目录下。
第一个是hadoop环境变量脚本文件hadoop-env.sh
修改第9行代码为
export JAVA_HOME=/usr/local/jdk
保存并关闭。这里设置的是 JAVA_HOME,注意去掉前面的“#”。
第二个是hadoop的核心配置文件core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>hadoop 的运行临时文件的主目录</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://book0:9000</value>
<description>HDFS 的访问路径</description>
</property>
</configuration>
第三个是hdfs配置文件hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>存储副本数</description>
</property>
</configuration>
第四个是MapReduce配置文件mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>book0:9001</value>
<description>JobTracker 的访问路径</description>
</property>
</configuration>
格式化文件系统
hdfs 是 文 件 系 统 , 所 以 在 第 一 次 使 用 之 前 需 要 进 行 格 式 化 。 执 行 命 令$HADOOP_HOME/bin/hadoop namenode –format
注意:只在第一次启动的时候格式化,不要每次启动都格式化。理解为我们新买了块
移动硬盘,使用之前总要格式化硬盘。
如果真的有必要再次格式化,请先把“$HADOOP_HOME/tmp”目录下的文件全部删除。
读者可以自己观察目录”$HADOOP_HOME/tmp”在格式化前后的变化情况。
格式化操作很少有出现失败的情况。如果真出现了,请检查配置是否正确
hadoop的启动
格式化完成后,开始启动 hadoop 程序。启动 hadoop 的命令脚本都在$HADOOP_HOME/bin/下,下面的所有命令都不再带有完整路
径名称。
这里讲述 hadoop 启动的三种方式:
第一种,一次性全部启动:
执行 start-all.sh 启动 hadoop,观察控制台的输出,见图 3-5,可以看到正在启动进程,分
别是 namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共 5 个,待执行
完毕后,并不意味着这 5 个进程成功启动,上面仅仅表示系统正在启动进程而已。
我们使用 jdk 的命令 jps 查看进程是否已经正确启动。执行以下 jps,如果看到了这 5 个
进程,见图 3-6,说明 hadoop 真的启动成功了。如果缺少一个或者多个,那就进入到“Hadoop
的常见启动错误”章节寻找原因了。
关闭 hadoop 的命令是stop-all.sh。
上面的命令是最简单的,可以一次性把所有节点都启动、关闭。除此之外,还有其他命
令,是分别启动的。
第二种,分别启动 HDFS和 MapReduce:
执行命令 start-dfs.sh,是单独启动 hdfs,见图 3-7。执行完该命令后,通过 jps 能够
看到 NameNode、DataNode、SecondaryNameNode 三个进程启动了,该命令适合于只执行 hdfs
存储不使用 MapReduce 做计算的场景。关闭的命令就是 stop-dfs.sh 了。
执行命令 start-mapred.sh,可以单独启动 MapReduce 的两个进程。关闭的命令就是
stop-mapred.sh 了。当然,也可以先启动 MapReduce,再启动 HDFS。这说明,HDFS 和MapReduce
的进程之间是互相独立的,没有依赖关系。
第三种,分别启动各个进程:
执行的命令是“hadoop-daemon.shstart [进程名称]”,这种启动方式适合于单独增加、
删除节点的情况,在安装集群环境的时候会看到。
root@book0 bin]# jps
14821 Jps
[root@book0 bin]# hadoop-daemon.sh start namenode
[root@book0 bin]# hadoop-daemon.sh start datanode
[root@book0 bin]# hadoop-daemon.sh startsecondarynamenode
[root@book0 bin]# hadoop-daemon.sh start jobtracker
[root@book0 bin]# hadoop-daemon.sh start tasktracker
[root@book0 bin]# jps
14855 NameNode
14946 DataNode
15043 SecondaryNameNode
15196 TaskTracker
15115 JobTracker
15303 Jps
至此hadoop的伪分布式安装已完成,读者接下来可以进行简单的MapReduce计算了。
(以上内容来源于网上的摘要结合自己的说明)

相关文章推荐
- Hadoop_2.1.0 MapReduce序列图
- RedHat 5.8 安装Oracle 11gR2_Grid集群
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- Redis 集群搭建和简单使用教程
- 文件系统变为raw 无法访问的解决方法
- PHP 文件系统详解
- hadoop 单机安装配置教程
- ASP.NET通过分布式Session提升性能
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- php中的filesystem文件系统函数介绍及使用示例
- Hadoop安装感悟
- Spring3.2.0和Quartz1.8.6集群配置
- hadoop安装lzo
- HDFS 文件操作