【Hadoop】YARN详解与安装指南
2014-02-21 15:19
302 查看
一 背景介绍
自从Hadoop推出以来,在大数据计算上得到广泛使用。其他分布式计算框架也出现,比如spark等。随着Hadoop的使用和研究越来越透彻,它暴漏出来的问题也越来越明显。比如NameNode的单点故障,任务调度器JobTracker的单点故障和性能瓶颈。各个公司对这几个问题都做出了对源代码的改变,比如阿里对NameNode做出修改使Hadoop的集群可以跨机房,而腾讯也做出了改变让Hadoop可以管理更多的节点。相对于各个企业对Hadoop做出改变以适应应用需求,Apache基金也对Hadoop做出了升级,从Hadoop 0.2.2.0推出了Hadoop二代,即YARN。YARN对原有的Hadoop做出了多个地方的升级,对资源的管理与对任务的调度更加精准。下面就对YARN从集群本身到集群的安装做一个详细的介绍。
二 YARN介绍
在介绍YARN之前,Hadoop内容请查看相关附注中的连接。2.1 框架基本介绍
相对于第一代Hadoop,YARN的升级主要体现在两个方面,一个是代码的重构上,另外一个是功能上。通过代码的重构不在像当初一代Hadoop中一个类的源码几千行,使源代码的阅读与维护都不在让人望而却步。除了代码上的重构之外,最主要的就是功能上的升级。功能上的升级主要解决的一代Hadoop中的如下几个问题:
1:JobTracker的升级。这个其中有两个方面,一个是代码的庞大,导致难以维护和阅读;另外一个是功能的庞大,导致的单点故障和消耗问题。这也是YARN对原有Hadoop改善最大的一个方面。
2:资源的调度粗粒度。在第一代Hadoop中,资源调度是对map和reduce以slot为单位,而且map中的slot与reduce的slot不能相互更换使用。即就算执行map任务没有多余的slot,但是reduce有很多空余slot也不能分配给map任务使用。
3:对计算节点中的任务管理粒度太大。
针对上述相应问题,YARN对Hadoop做了细致的升级。YARN已经不再是一个单纯的计算平台,而是一个资源的监管平台。在YARN框架之上可以使用MapReduce计算框架,也可以使用其他的计算或者数据处理,通过YARN框架对计算资源管理。升级后的YARN框架与原有的Hadoop框架之间的区别可以用下图解释:
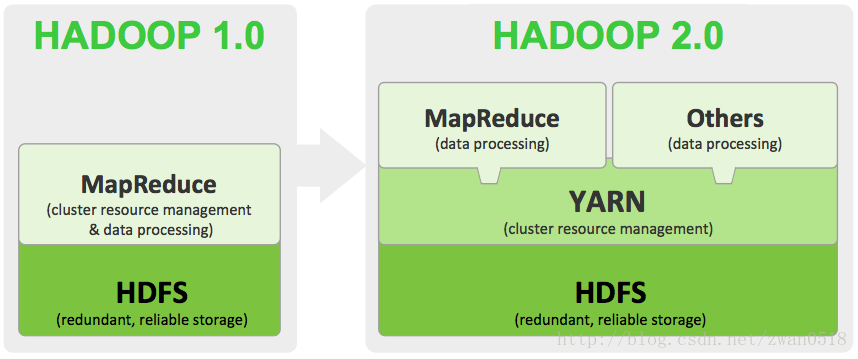
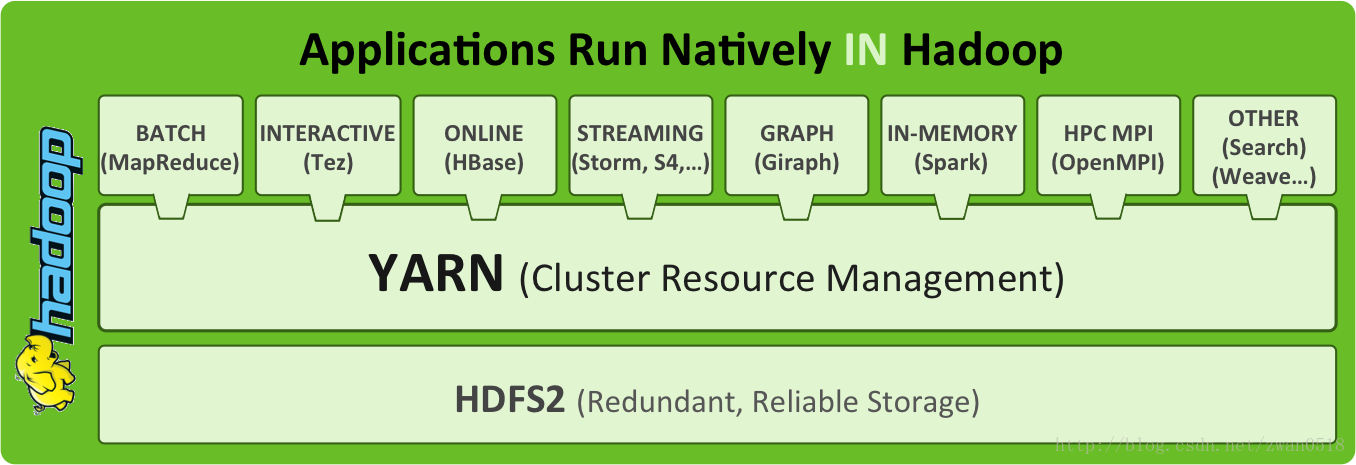
细节内容待补充。
2.2 框架架构解读
相对于一代Hadoop中计算框架的JobTracker与TaskTracker两个主要通信模块,YARN的模块变的更加丰富。在一代Hadoop中JobTracker负责资源调度与任务分配,而在YARN中则把这两个功能拆分由两个不同组件完成,这不仅减少了单个类的代码量(单个类不到1000行),也让每个类的功能更加专一。原有的JobTracker分为了如今的ResourceManager与ApplicationMaster
两个功能组件,一个负责任务的管理一个负责任务的管理。有人会问那任务的调度与计算节点的谁来负责。任务的调度有可插拔的调
度器ResourceScheduler,计算节点有NodeManager来完成。这在下面会细说。
YARN的架构设计如下图所示:
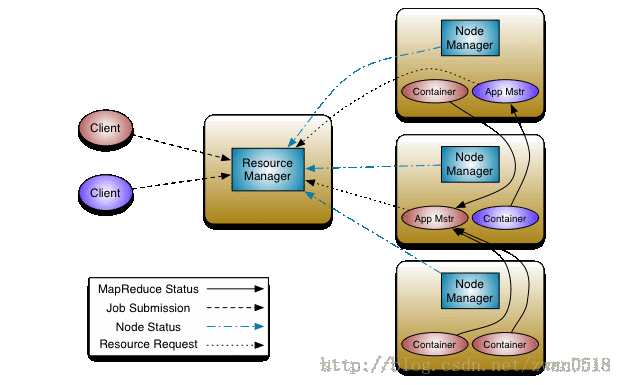
相对于第一代Hadoop,YARN把Hadoop中的资源控制、任务调度和具体任务计算的JobTracker/TaskTracker架构,变为下述的四个功能组件,让资源调度和任务调度更加细粒化。
集群唯一的ResourceManager
每个任务对应的ApplicationMaster
每个机器节点上的NodeManager
运行在每个NodeManager上针对某个任务的Container
通过上述四个功能组件的合作,解决了第一代Hadoop中JobTracker负责所有资源的调度和任务的调度的重任。除此之外还解决了,资源分配简单粗暴的问题。
2.3 功能组件细讲
ResourceManagerResourceManager是这一代Hadoop升级中最主要的一个功能组件。
NodeManager
ResourceScheduler
三 安装
相对于Hadoop的安装,YARN的安装稍微繁琐一点,因为它的组件更多。对于一代Hadoop,它大的组件就可以分为HDFS与MapReduce,HDFS主要是NameNode与Datanode,而MapReduce就是JobTracker与TaskTracker。YARN框架中HDFS部分虽然和一代Hadoop相同,但是启动方式则和一代完全不同;而MapReduce部分则更加复杂。所以安装起来稍微繁琐一点。下面我们就参考官方文档,开始慢慢讲解整个安装过程。在安装过程中遇到的问题都记录在附录中给出的连接中。YARN安装可以通过下载tar包或者通过源代码两种方式安装,我们集群是采用的下载tar包然后进行解压的安装方式,下载地址在附录中给出。为了方便安装,我们是解压到根目录/yarn。解压tar包后的YARN目录结构有一点需要注意,即配置文件conf所在的正确位置应该是/yarn/conf,但是解压后/yarn目录中是没有conf文件的,但是有有个/etc/hadoop目录。所有的配置文件就在该目录下,你需要做的是把该文件move到/yarn/conf位置。再做下一步的安装。如果你解压后的文件没有出现上面情况,那这一步操作可以取消。
对于YARN的安装主要是HDFS安装与MapReduce安装。我们的集群共有四台机器,其中一台作为NameNode所在,一台作为ResourceManager所在,剩下的两台则担任数据节点与计算节点。具体的机器安排如下:
linux-c0001:ResourceManager
linux-c0002:NameNode
linux-c0003:DataNode/NodeManager
linux-c0004:DataNode/NodeManager
因为我们的集群上已经安装有其他版本的Hadoop,比如Apache的Hadoop还有Intel推出的Intel Distributiong Hadoop,所以很多默认的端口号都要修改,数据文件的存储位置与运行Hadoop的用户都要修改。在安装的过程中因为已经安装的Hadoop的存在,也遇到了很多问题。这在下面还有附录中的连接中都会有说明。
下面针对每个安装进行介绍:
3.1 HDFS安装与配置
HDFS安装主要是NameNode与DataNode的安装与配置,其中NameNode还需要一步格式化formate操作。其中HDFS的配置主要存在于core-site.xml与hdfs-site.xml两个文件中。这两个配置文件的默认属性已经在附录中给出,但是在我们集群中不能采用。因为,我们集群中已经安装有其他Hadoop,如果全部采用默认配置则会出现冲突,在安装过程中出现Portin use 的BindException。主要需要配置的地方如下几点:
1:NameNode配置
在我们集群中c0002是NameNode所在的机器,在该机器的配置文件中需要修改的是两个文件core-site.xml与hdfs-site.xml。需要修改的配置文件指定namenode所在主机与端口号,NameNode的数据文件目录等几点。
下面分别给出我们的core-site.xml与hdfs-site.xml的配置:
core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://linux-c0002:9090</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>
对于HDFS的配置,因为有NameNode与DataNode两种节点身份,所以在NameNode与DataNode中配置文件不会完全一致,下面就会贴出两种节点上的不同配置。
hdfs-site.xml(NameNode):
<configuration> <property> <name>dfs.namenode.http-address</name> <value>linux-c0002:50071</value> </property> <property> <name>dfs.namenode.backup.address</name> <value>linux-c0002:50101</value> </property> <property> <name>dfs.namenode.backup.http-address</name> <value>linux-c0002:50106</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/YarnRun/name1,/home/hadoop/YarnRun/name2</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration>
2:DataNode的配置
DataNode的配置是在hdfs-site.xml中进行个性化配置的,主要包括DataNode的主机和对外端口号,数据文件位置。按照正常DataNode的主机与对外端口号是不用额外配置的,在安装的时候采用默认的端口号就好。但是,还是那个原因,因为我们集群中安装有其他的Hadoop版本,所以不得不对默认的DataNode中的端口号做一定的修改。
下面给出配置后的文件内容:
hdfs-site.xml(DataNode)
<configuration> <property> <name>dfs.namenode.http-address</name> <value>linux-c0002:50071</value> </property> <property> <name>dfs.datanode.address</name> <value>linux-c0003:50011</value> </property> <property> <name>dfs.datanode.http.address</name> <value>linux-c0003:50076</value> </property> <property> <name>dfs.datanode.ipc.address</name> <value>linux-c0003:50021</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/YarnRun/data1</value> </property> </configuration>
3:slaves文件的修改
slaves文件主要是指明子节点的位置,即数据节点和计算节点的位置。和一代Hadoop不同的是,在YARN中不需要配置masters文件,只有slaves配置文件。在slaves添加两个子节点主机名(整个集群的主机名在集群中的所有主机的hosts文件中已经注明):
linux-c0003
linux-c0004
4:Namenode的格式化
采用官方文档给出的格式化命令进行格式化(cluster_name没有指定则不需要添加该参数)
$HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>
5:Namenode启动
采用官方文档给出的启动命令直接启动就好。(注意:启动命令与格式化命令的脚本不再同一个文件中)
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
6:检查NameNode是否启动
输入jps命令,看是否有NameNode进程;或者访问其web链接看是否能正常访问。如果不能正常访问,则去看相应的日志进行相应的定向修改。
7:DataNode的启动
在YARN中DataNode的启动与第一代Hadoop的启动是不相同的,在第一代Hadoop中你执行一个start-all命令包括NameNode与各个节点上的DataNode都会相继启动起来,但是在YARN中你启动DataNode必须要去各个节点依次执行启动命令。当然你也可以自己写启动脚本,不去各个节点重复执行命令。
下面贴出启动命令:
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
3.2 MapReduce安装与配置
MapReduce其中需要配置安装的地方是ResourceManager与NodeManager的安装与配置。
1:ResourceManager的配置
ResourceManager与NameNode一样,都是单独在一个机器节点上,对ResourceManager的配置主要是在yarn-site.xml中进行配置的。可配置的属性主要包括主机与端口号,还有调度器的配置。
<configuration> <property> <name>yarn.resourcemanager.address</name> <value>linux-c0001:8032</value> <description>the host is the hostname of the ResourceManager and the port is the port on which the clients can talk to the Resource Manager. </description> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>linux-c0001:8031</value> <description>host is the hostname of the resource manager and port is the port on which the NodeManagers contact the Resource Manager. </description> </property> <!-- for scheduler --> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>linux-c0001:8030</value> <description>host is the hostname of the resourcemanager and port is the port on which the Applications in the cluster talk to the Resource Manager. </description> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> <description>In case you do not want to use the default scheduler</description> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value></value> <description>the local directories used by the nodemanager</description> </property> <!-- for nodemanager --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>10240</value> <description>the amount of memory on the NodeManager in GB</description> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/app-logs</value> <description>directory on hdfs where the application logs are moved to </description> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value></value> <description>the directories used by Nodemanagers as log directories</description> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>shuffle service that needs to be set for Map Reduce to run </description> </property> </configuration>
2:NodeManager的配置
NodeManager主要是配置计算节点上的对计算资源的控制和对外的端口号,它的配置也在yarn-site.xml中进行配置,所以这里的配置文件和上面贴出的配置文件代码是完全一样的,在这里就不再次粘贴文件具体内容。
3:mapreduce的配置
mapreduce的配置主要是在mapred-site.xml中,用来指明计算框架的版本(Hadoop/YARN)还有计算的中间数据位置等。
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.cluster.temp.dir</name> <value></value> </property> <property> <name>mapreduce.cluster.local.dir</name> <value></value> </property> </configuration>4:ResourceManager启动
具体代码
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
5:NodeManager的启动
NodeManager的启动和DataNode的启动也是一样,需要到各个计算节点上执行启动命令。具体代码如下:
$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start nodemanager
6:JobHistory的启动
JobHistory服务主要是负责记录集群中曾经跑过的任务,对完成的任务查看任务运行期间的详细信息。一般JobHistory都是启动在运行任务的节点上,即NodeManager节点上。如果不对JobHistory的配置进行修改,那么直接可以在NodeManager所在节点上运行启动命令即可,具体启动命令如下:
$HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh start historyserver --config $HADOOP_CONF_DIR
启动了之后就可以在集群运行任务页面查看具体的job history,通过点击每个任务条目的左后history链接就可以查看具体的任务细节。具体的截图如下:
四 关闭集群
当集群升级或者需要重启集群的时候,就需要执行关闭命令。分别关闭NameNode与DataNode,然后关闭ResourceManager与NodeManager。但是在关闭的时候可能会遇到no namenode to stop或者no resourcemanager to stop的问题。这是因为YARN在关闭的时候,它会首先获取当前系统中的YARN相关运行进程的ID,如果没有则就会爆出上述两个问题。但是系统中明明运行这YARN相关进程,为何还是会说没有进程stop。这是因为当YARN运行起来之后,运行中的进程ID会存储在/tmp文件夹下,而/tmp文件会定期删除文件,这就导致YARN停止脚本无法找到YARN相关进程的ID,导致不能停止。两个解决方案,第一个就是使用kill命令,而第二个则是修改YARN的进程ID的存放文件夹目录。
五 附录
YARN官方文档:YARN官方介绍YARN下载:Hadoop 0.2.2.0
安装中遇到的问题:http://blog.csdn.net/zwan0518/article/details/9164449
集群安装官方文档:http://hadoop.apache.org/docs/current2/hadoop-project-dist/hadoop-common/ClusterSetup.html#Hadoop_MapReduce_Next_Generation_-_Cluster_Setup
core-site默认配置:http://hadoop.apache.org/docs/current2/hadoop-project-dist/hadoop-common/core-default.xml
hdfs-site默认配置:http://hadoop.apache.org/docs/current2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
mapred-site默认配置:http://hadoop.apache.org/docs/current2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
yarn-site默认配置:http://hadoop.apache.org/docs/current2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml

相关文章推荐
- Spark on Yarn+Hbase环境搭建指南(二)Hadoop安装
- hadoop学习(五)Hadoop2.2.0完全分布式安装详解(1)
- 深度学习入门之一:Windows10(64)+Anaconda3(Python3.5)+TensorFlow-Gpu1.4+CUDA8.0+cuDNN6安装详解及Pycharm配置指南
- hadoop2.2.0 centos 编译安装详解
- hadoop2.2.0 centos 编译安装详解
- [Hadoop] Sqoop安装过程详解
- Hadoop 新 MapReduce 框架 Yarn 详解
- ubuntu下安装jdk,hadoop及其配置步骤详解
- hadoop配置文件详解、安装及相关操作补充版
- Hadoop 新 MapReduce 框架 Yarn 详解【转载】
- HA-Hadoop-yarn安装
- Hadoop 新 MapReduce 框架 Yarn 详解
- centos6.5 安装hadoop1.2.1的教程详解【亲测版】
- hadoop安装详解
- 安装Spark Standalone模式/Hadoop yarn模式并运行Wordcount
- Hadoop 新 MapReduce 框架 Yarn 详解
- Linux环境Hadoop伪分布模式安装详解
- Hadoop 详细安装配置指南
- Hadoop 新 MapReduce 框架 Yarn 详解
- Hadoop 新 MapReduce 框架 Yarn 详解