论文读书笔记-A text clustering framework for information retrieval
2014-02-18 17:09
369 查看
这篇文章提出了一种针对文本聚类的模型,在这个模型中首先是对文档之间的距离进行语义上的度量,然后是在这个基础上在RBF核函数定义的高维空间上进行映射,最终实现文档聚类。
下面是本文的一些要点:
1、 文本聚类的难点
文本聚类中主要涉及到三个方面的内容,一是定义文档的表现形式;二是相似度的度量方式;三是一个划分的标准(一般是用代价函数来衡量)。
在设计模型时存在三个主要的问题:
-维度的数目:文档的表现维度从几十到成百上千不等,有时候用整个词表作为标准,每篇文档的维度就会变得稀疏。一般需要进行维度压缩,常见的方法就是SVD
-相似度度量的定义:两个向量之间的相似度定义最常见的方式如下
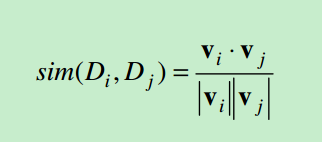
-聚类算法的选择:主要包括kmeans,SOM,EM算法等,有人也提出了基于图论的方法,例如Document index graph
2、 文档间距离度量
和常见的文档用一个向量表示不同,这里用一个向量对表示文档,记为v’和v’’。其中v’是对文档中词的表示,也就是通常见到的文档用词向量表示的形式,在这里进行归一化操作
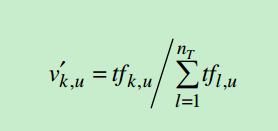
其中tfk是第k个短语在文档中的出现次数,v’中的权重也就是短语的频率
一篇文档除了能提取出每个短语及其出现的次数外,还能够提取出文档短语在单词表中的概率分布情况,每个短语和一个概率密度函数相关。V’’衡量的就是这种概率分布情况。
空间概率密度函数定义如下:
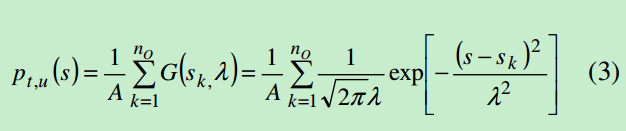
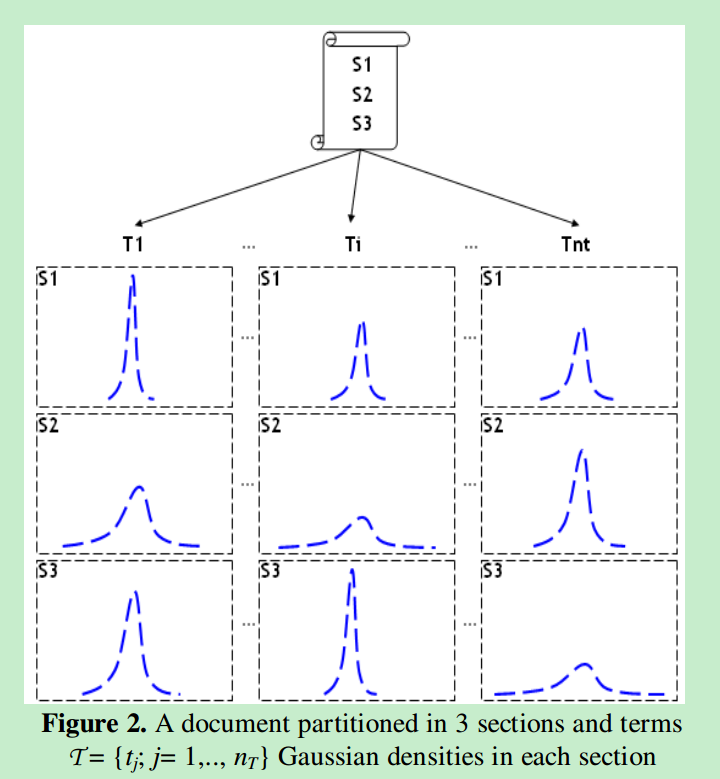
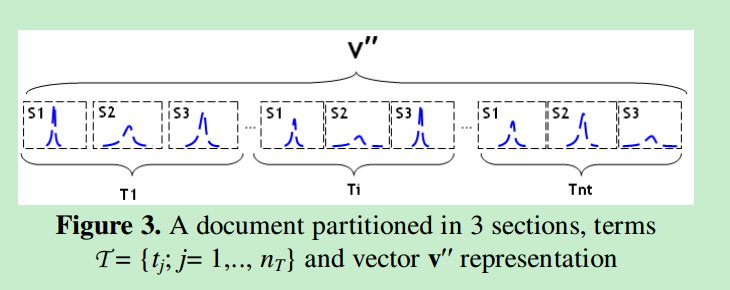
每个文档首先分割为S个段落,这S维的向量是由短语在对应文档中分布的概率产生的。V’’也就是一个包含nt个值向量,每个向量的维度为S。如下图:
定义好了v’和v’’之后,下面就是分别定义两个文档中对应v’和v’’的距离:
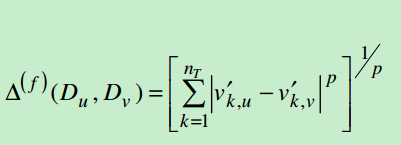
针对V’这里计算的是Minkowski距离,p是参数
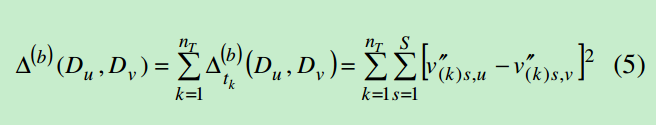
针对v’’这里计算的是欧几里得距离
最终两篇文档之间的距离就是这两个距离的加权求和:
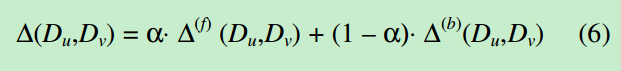
Alpha是参数,位于[0,1]
3、 kernel k-means
这里的kernel k-means是在基本k-means的基础上加以改进。最主要的变化是用一个函数把元素映射到高维空间
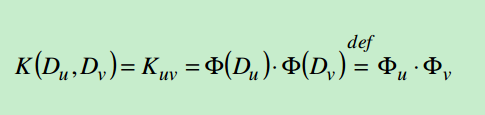
这样得到每个类的中心点计算公式:
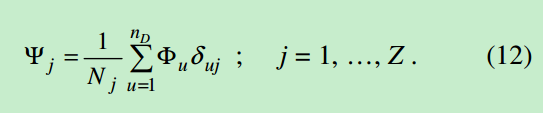
文档距离类的距离:
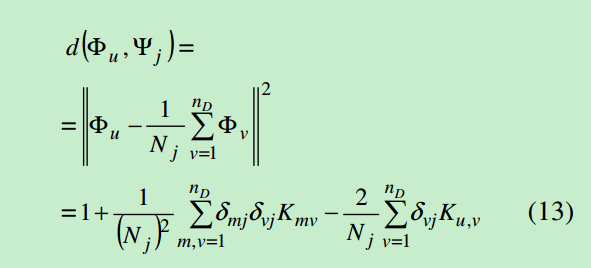
下面是本文的一些要点:
1、 文本聚类的难点
文本聚类中主要涉及到三个方面的内容,一是定义文档的表现形式;二是相似度的度量方式;三是一个划分的标准(一般是用代价函数来衡量)。
在设计模型时存在三个主要的问题:
-维度的数目:文档的表现维度从几十到成百上千不等,有时候用整个词表作为标准,每篇文档的维度就会变得稀疏。一般需要进行维度压缩,常见的方法就是SVD
-相似度度量的定义:两个向量之间的相似度定义最常见的方式如下
-聚类算法的选择:主要包括kmeans,SOM,EM算法等,有人也提出了基于图论的方法,例如Document index graph
2、 文档间距离度量
和常见的文档用一个向量表示不同,这里用一个向量对表示文档,记为v’和v’’。其中v’是对文档中词的表示,也就是通常见到的文档用词向量表示的形式,在这里进行归一化操作
其中tfk是第k个短语在文档中的出现次数,v’中的权重也就是短语的频率
一篇文档除了能提取出每个短语及其出现的次数外,还能够提取出文档短语在单词表中的概率分布情况,每个短语和一个概率密度函数相关。V’’衡量的就是这种概率分布情况。
空间概率密度函数定义如下:
每个文档首先分割为S个段落,这S维的向量是由短语在对应文档中分布的概率产生的。V’’也就是一个包含nt个值向量,每个向量的维度为S。如下图:
定义好了v’和v’’之后,下面就是分别定义两个文档中对应v’和v’’的距离:
针对V’这里计算的是Minkowski距离,p是参数
针对v’’这里计算的是欧几里得距离
最终两篇文档之间的距离就是这两个距离的加权求和:
Alpha是参数,位于[0,1]
3、 kernel k-means
这里的kernel k-means是在基本k-means的基础上加以改进。最主要的变化是用一个函数把元素映射到高维空间
这样得到每个类的中心点计算公式:
文档距离类的距离:

相关文章推荐
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
- 论文读书笔记-automatic text summarization for annotating images
- 对论文Synthetic Data for Text Localisation in Natural Images的理解
- 【CV论文阅读】Unsupervised deep embedding for clustering analysis
- 论文笔记:Research and Implementation of a Multi-label Learning Algorithm for Chinese Text Classification
- KDD 2014 “A Dirichlet Multinomial Mixture Model-based Approach for Short Text Clustering” 的主要思想
- 论文阅读理解 - Deep Learning of Binary Hash Codes for Fast Image Retrieval
- [实验室论文]A Planning based Framework for Essay Generation
- 【Paper Note】Convolutional Clustering for Unsupervised Learning 论文翻译
- 论文阅读:Synthetic Data for Text Localisation in Natural Images
- 【论文阅读】Sequential Matching Network: A New Architecture for Multi-turn Response Selection in Retrieval
- A Key Volume Mining Deep Framework for Action Recognition论文学习
- 论文笔记:IRGAN:A Minimax Game for Unifying Generative and Discriminative Information
- 论文读书笔记-large scale text classfication using semi-supervised multinomial naïve bayes
- Referenced file contains errors (http://www.springframework.org/schema/aop/spring-aop-3.0.xsd). For more information, right click on the message in th
- HCP: A Flexible CNN Framework for Multi-label Image Classification论文学习
- 阅读论文:Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation
- 论文读书笔记-keyword-based document clustering
- 【聚类论文笔记】Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions