hadoop之MapReduce框架JobTracker端心跳机制分析(源码分析第七篇) 推荐
2014-02-17 17:20
435 查看
一、小概述
JobTracker端的心跳机制主要任务是处理TaskTracker发送过来的心跳信息,判断TaskTrakcer是否存活、及时让JobTracker获取到各个节点上的资源使用情况和任务运行情况和为TaskTracker下达各种命令等功能。
二、心跳处理过程详解
JobTracker端的心跳机制处理代码只要是JobTracker类的heartbeat方法,通过逐步的分析其中大概的流程比较多,但是万变不离其中都是先各种容错性检测,对Task、TaskTracker、job状态信息的更新以及临时资源的清理,处理心跳信息,返回心跳应答信息等。下面看看简单的流程图:
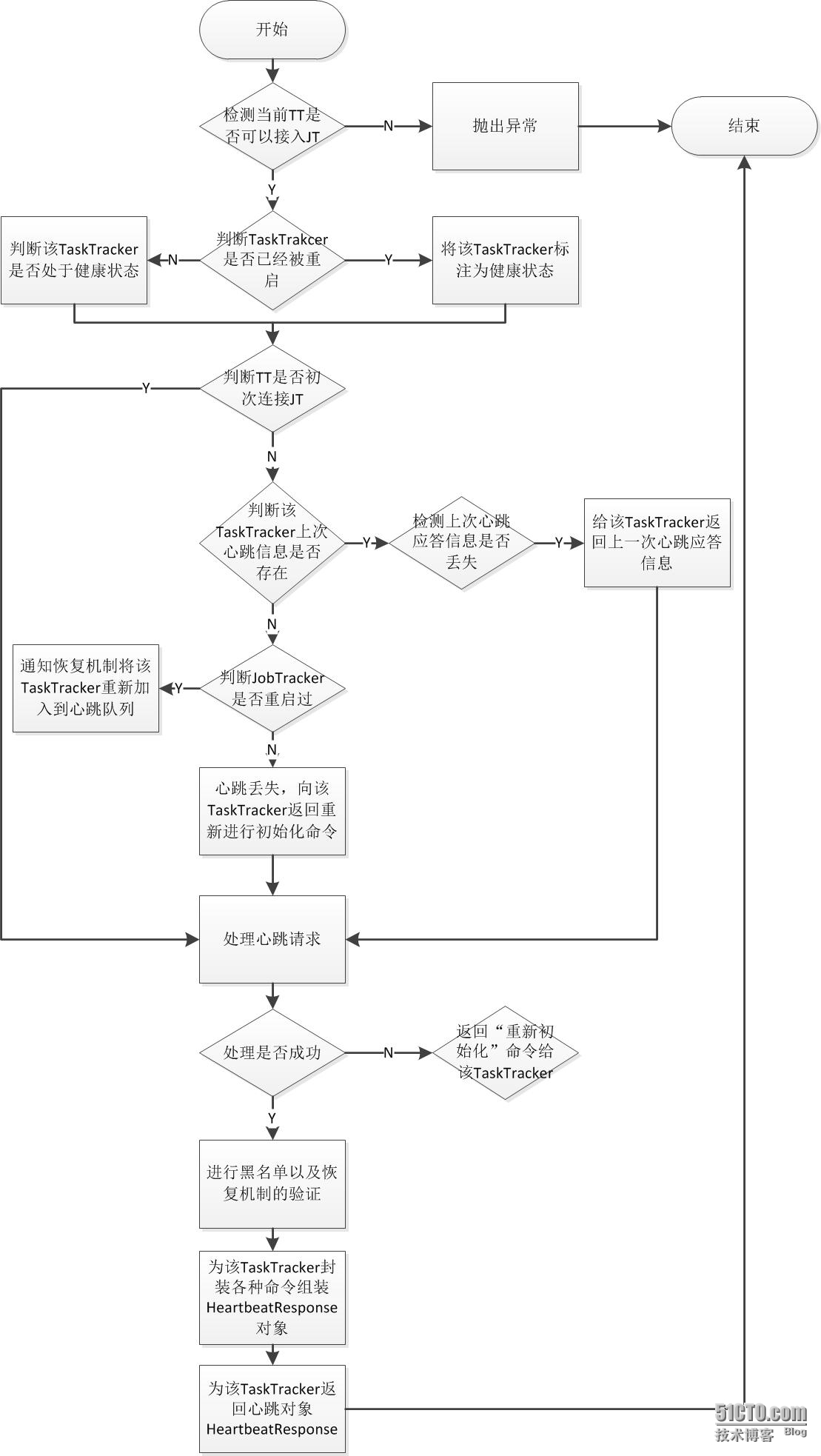
(1)过程一,检测当前TaskTracker是否可以接入JobTracker。
在该过程中,JobTracker会对TaskTracker是否可以进行连接进行检测。
当且仅当该TaskTracker在host list(由参数mapred.hosts配置)中,但是不在exclude list(由mapred.hosts.exclude指定)中,才允许接入。如果不允许接入则会直接抛出异常终止本次心跳处理。代码定位到JobTracker类的heartbeat方法:
在JobTracker允许TaskTracker接入的前提下,检查该TaskTracker是否已经被重启过了(是否重启过的restarted参数有TaskTracker通过心跳传给JobTracker)。如果TaskTracker被重启过,则将之标注为健康状态的TaskTracker,并且从黑名或者灰名单中清除,否则启动容错机制以检测它是否处于健康状态。
(3)过程三,检测TaskTracker是否是第一次连接JobTracker。
这是一个非常重要的容错步骤。如果是非初次心跳,正常情况下在JobTracker中的trackerToHeartbeatResponseMap对象中会存在该TaskTracker上一次的心跳应答对象信息HeartbeatResponse,初次心跳连接则不会有该TaskTracker上一次的应答对象。但是在非正常情况下会出现,非初次心跳,但是trackerToHeartbeatResponseMap没有该TaskTracker的应答对象信息存在,这是可能由于网络等各方面的原因造成的,另外重要的一点是initialContact标识是从TaskTracker端通过心跳发送过来的,JobTracker端记录的该TaskTracker状态不一定是一致的。因此,在这一步要进行比较多的容错性校验。
首先,通过TaskTracker通过心跳带来的initialContact标志判断该TaskTracker是否是初次链接,如果是则直接进入处理心跳信息环节。如果非初次连接并且上一次心跳应答对象不存在,则会去判断该JobTracker是否被重启过,如果不是,说明上次心跳应答丢失那么直接给该TaskTracker组装重新初始化命令让其重新初始化,如果JobTracker被重启过则会自动先检测是否存在需要恢复运行状态的作业。如果有,则可以通过日志恢复这些作业的运行状态,并重新调度那么些没有运行的tasks,当然也包括了已经产生部分结果的tasks(前提是启用作业恢复机制,有参数mapred.jobtracker.restart.recover配置,具体地内容可以参考我的blog源码分析系列第4篇)。在JobTracker重启过程中各个TaskTracker依旧还活着的,此时通知RecoveryManager该TaskTracker已经重新连接,并且从recoveryManager中remove掉。另外的一种情况,非初次连接并且针对该TaskTracker的上次的心跳应答对象信息还存在,则判断JobTracker端的上一次对该TaskTracker的心跳应答ID是否与该TaskTracker带过来的应答ID一致,如果不一致,属于丢失心跳情况,返回上一次心跳信息给该TaskTracker,这样可以防止处理重复的心跳请求你。这部分的容错校验比较复杂步骤比较多,想整体了解还是看上面的流程图吧。贴一下这段代码:
处理心跳请求环节是整个JobTracker心跳的机制的核心。这里最主要的任务就是根据心跳带来的TraskTracker状态信息去更新当前集群的资源使用情况、Task信息和节点健康信息。代码如下:
该过程主要是遍历JobTracker中的各种对象映射集合(可以看我源码分析第二篇文章的第三点http://zengzhaozheng.blog.51cto.com/8219051/1352280),取得相关命令,然后为TaskTracker下达命令。
ReinitTrackerAction,重新初始化命令
上面的过程分析中,已经多次提到过ReinitTrackerAction命令,它在容错性检测出错的时候往往会被执行,JobTracker发送这个命令对TaskTracker重新进行初始化。在JobTracker端的整个心跳处理过程中,运行ReinitTrackerAction命令大体有2种(在上面的分析过程中都有提到,可以回头看看):
丢失上次心跳应道信息:JobTracker保存了向每个TaskTracker发送的最近心跳应答信息。如果JobTracker不是刚刚重启并且TaskTracker不是初次链接JobTracker,而最近的心跳应答信息 丢失,这会造成不一致情况。
丢失TaskTracker的状态信息:JobTracker接收到任何一个心跳信息后,都会将其TaskTracker的对象信息(TaskTrackerStatus类)保存起来。如果一个TaskTracker 非初次连接JobTracker但是其状态信息又不存在,造成不一致的情况。
LaunchTaskAction
该类封装了TaskTracker分配的新任务,新任务的类型分两种:计算型任务和辅助型任务。其中计算型任务负责处理实际数据的任务,也就是我们常说的Reduce和Map任务,他们由专门的任务调度器去调用(默认是FIFO调度器)。另外辅助型任务包括:job-setup task、job-cleanup task和task-cleanup task三种。task-cleanup task的主要作用是清理失败的map或者reduce任务的部分结果数据,它由jobTracker直接调度,而且其调度的优先级比map和reduce任务都要高。至于job-setup task和job-cleanup task任务的作用我认为比较简单,主要是标志map和reduce作业运行开始和运行结束的同步标志。jobTracker为一个有空闲slot并且不在黑名单中的taskTracker分配任务的选择顺序是先辅助型任务然后计算型任务,这点我们可以从heartbeat方法看出来:
该类封装了TaskTracker需要杀死的任务。TaskTracker收到该任务后会杀掉对应的任务以及清理掉工作目录和释放slot。JobTracker主要在下面情况下会向TrackerTracker发送KillTaskAction命令(不全):
(1)整个作业运行失败,其他正在运行的Task也会被杀死。
(2)启动推测执行任务机制(默认启动)后,同一份数据可能有2个Task Attempt处理。只要一个Task Attempt运行成功后,两外一个处理同一份数据的任务就会被kill掉。
(3)TaskTracker在指定时间内没有向JobTracker汇报心跳,则JobTracker会任务它已经死掉,那么在它上面运行的所有task就会被标注为死亡。
(4)用户自己直接调用命令"bin/hadoop job -kill-task"或者"bin/hadoop job -fail-task",使一个或者多个任务失败。
KillTaskAction
KillTaskAction封装了TaskTracker待清理的作业。当TaskTracker接收到KillTaskAction命令后会清理此作业工作目录。下面几个主要的场景会出现这种情况:
(1)用户主动杀死作业,调用"bin/hadoop job -kill"或者"bin/hadoop job -fail"命令。
(2)作业运行完毕,通知TaskTracker清理作业目录。
(3)作业运行失败,通知TaskTracker清理作业目录。
CommitTaskAction
该类封装了TaskTracker需要提交的任务。为了防止同一个TaskInProgress的两个同时运行的Task Attempt(例如打开推测执行功能,一个任务可能有多个备份任务)同时打开一个文件或者往同一个文件中写数据而生产冲突,Hadoop让每个Task Attempt写到单独一个文件中(以taskAttemptID命名,比如attempt_201402171212_0009_r_000000_0)中。通常而言,Hadoop让每个Task Attempt将计算结果写到临时目录${mapred.output.dir}/_tmporary/_${taskID}中,当某个Task Attempt运行成功后,再将运行结果转移到最终目录${mapred.output.dir}中。Hadoop将一个成功运行的Task Attempt结果文件从临时目录移动到最终目录的过程,称为“任务提交”。当TaskProgress中的一个任务被提交后,其他任务将被杀死,同时意味着该TaskTracker运行完成。
三、集群规模调整动态调整心跳间隔
从在上一篇blog中分析TaskTracker端的心跳机制中,我们知道TaskTracker会通过“外带心跳”和根据Task完成数目来动态调整心跳间距。 JobTracker端的心跳处理也有相应的机制以用来调整TaskTracker心跳的汇报时间间隔。这种调整的意义在于可以提高系统的吞吐量,避免心跳间隔过小造成JobTracker要进行并发处理的请求压力大,和心跳间隔过大造成资源浪费不能是TaskTracker及时汇报资源信息给JobTracker,进而为之分配任务。JobTracker监控者整个集群的规模情况,可以通过这个动态地调整每个TaskTracker下次汇报心跳的时间间隔,并通过心跳机制告诉TaskTracker。 最重要的是这种机制还是可控制的,JobTracker允许用户通过参数设置心跳的时间间隔加速比例,简单说就是每增加mapred.heartbeats.in.second(最小是1,默认为100)个节点,心跳时间间隔就增加mapreduce.jobtracker.heartbeats.scaling.factor(最小是0.01,默认1)秒,简单说默认情况下增加100个节点心跳就增加1秒。但是,为了防止用户参数设置不合理而对JobTracker产生较大负载,JobTracker要求心跳间隔大于或者等于3秒。具体算法看代码,JobTracker类的getNextHeartbeatInterval方法:
参考文献:[1]《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》[2] http://hadoop.apache.org
JobTracker端的心跳机制主要任务是处理TaskTracker发送过来的心跳信息,判断TaskTrakcer是否存活、及时让JobTracker获取到各个节点上的资源使用情况和任务运行情况和为TaskTracker下达各种命令等功能。
二、心跳处理过程详解
JobTracker端的心跳机制处理代码只要是JobTracker类的heartbeat方法,通过逐步的分析其中大概的流程比较多,但是万变不离其中都是先各种容错性检测,对Task、TaskTracker、job状态信息的更新以及临时资源的清理,处理心跳信息,返回心跳应答信息等。下面看看简单的流程图:
(1)过程一,检测当前TaskTracker是否可以接入JobTracker。
在该过程中,JobTracker会对TaskTracker是否可以进行连接进行检测。
当且仅当该TaskTracker在host list(由参数mapred.hosts配置)中,但是不在exclude list(由mapred.hosts.exclude指定)中,才允许接入。如果不允许接入则会直接抛出异常终止本次心跳处理。代码定位到JobTracker类的heartbeat方法:
...
//JobTracker检测该TaskTracker是否可以进行连接,当且仅当该TaskTracker在host list(由参数mapred.hosts配置)中,
//但是不在exclude list(由mapred.hosts.exclude指定)中,才允许接入。
if (!acceptTaskTracker(status)) {
throw new DisallowedTaskTrackerException(status);
}
...追踪进入acceptTaskTracker方法,可以清楚的看到:...
/**
* Returns true if the tasktracker is in the hosts list and
* not in the exclude list.
*/
private boolean acceptTaskTracker(TaskTrackerStatus status) {
return (inHostsList(status) && !inExcludedHostsList(status));
}
...(2)过程二,检测TaskTracker是否已经被重启在JobTracker允许TaskTracker接入的前提下,检查该TaskTracker是否已经被重启过了(是否重启过的restarted参数有TaskTracker通过心跳传给JobTracker)。如果TaskTracker被重启过,则将之标注为健康状态的TaskTracker,并且从黑名或者灰名单中清除,否则启动容错机制以检测它是否处于健康状态。
(3)过程三,检测TaskTracker是否是第一次连接JobTracker。
这是一个非常重要的容错步骤。如果是非初次心跳,正常情况下在JobTracker中的trackerToHeartbeatResponseMap对象中会存在该TaskTracker上一次的心跳应答对象信息HeartbeatResponse,初次心跳连接则不会有该TaskTracker上一次的应答对象。但是在非正常情况下会出现,非初次心跳,但是trackerToHeartbeatResponseMap没有该TaskTracker的应答对象信息存在,这是可能由于网络等各方面的原因造成的,另外重要的一点是initialContact标识是从TaskTracker端通过心跳发送过来的,JobTracker端记录的该TaskTracker状态不一定是一致的。因此,在这一步要进行比较多的容错性校验。
首先,通过TaskTracker通过心跳带来的initialContact标志判断该TaskTracker是否是初次链接,如果是则直接进入处理心跳信息环节。如果非初次连接并且上一次心跳应答对象不存在,则会去判断该JobTracker是否被重启过,如果不是,说明上次心跳应答丢失那么直接给该TaskTracker组装重新初始化命令让其重新初始化,如果JobTracker被重启过则会自动先检测是否存在需要恢复运行状态的作业。如果有,则可以通过日志恢复这些作业的运行状态,并重新调度那么些没有运行的tasks,当然也包括了已经产生部分结果的tasks(前提是启用作业恢复机制,有参数mapred.jobtracker.restart.recover配置,具体地内容可以参考我的blog源码分析系列第4篇)。在JobTracker重启过程中各个TaskTracker依旧还活着的,此时通知RecoveryManager该TaskTracker已经重新连接,并且从recoveryManager中remove掉。另外的一种情况,非初次连接并且针对该TaskTracker的上次的心跳应答对象信息还存在,则判断JobTracker端的上一次对该TaskTracker的心跳应答ID是否与该TaskTracker带过来的应答ID一致,如果不一致,属于丢失心跳情况,返回上一次心跳信息给该TaskTracker,这样可以防止处理重复的心跳请求你。这部分的容错校验比较复杂步骤比较多,想整体了解还是看上面的流程图吧。贴一下这段代码:
...
if (initialContact != true) {//该TaskTracker不是是第一次连接JobTracker
// If this isn't the 'initial contact' from the tasktracker,
// there is something seriously wrong if the JobTracker has
// no record of the 'previous heartbeat'; if so, ask the
// tasktracker to re-initialize itself.
//TaskTracker非第一次连接JobTracker,并且上一次心跳应答对象为空
if (prevHeartbeatResponse == null) {
// This is the first heartbeat from the old tracker to the newly
// started JobTracker
if (hasRestarted()) {//判断JobTracker是否重启过
addRestartInfo = true;
// inform the recovery manager about this tracker joining back
recoveryManager.unMarkTracker(trackerName);
} else {//心跳丢失,向该TaskTracker返回重新进行初始化命令
// Jobtracker might have restarted but no recovery is needed
// otherwise this code should not be reached
LOG.warn("Serious problem, cannot find record of 'previous' " +
"heartbeat for '" + trackerName +
"'; reinitializing the tasktracker");
return new HeartbeatResponse(responseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}
} else {//TaskTracker非第一次连接JobTracker,并且上一次心跳应答对象不为空
// It is completely safe to not process a 'duplicate' heartbeat from a
// {@link TaskTracker} since it resends the heartbeat when rpcs are
// lost see {@link TaskTracker.transmitHeartbeat()};
// acknowledge it by re-sending the previous response to let the
// {@link TaskTracker} go forward.
//判断JobTracker端的上一次对该TaskTracker的心跳应答ID是否与该TaskTracker带过来的应答ID一致
if (prevHeartbeatResponse.getResponseId() != responseId) {//不一致,属于丢失心跳情况,返回上一次心跳信息给该TaskTracker
LOG.info("Ignoring 'duplicate' heartbeat from '" +
trackerName + "'; resending the previous 'lost' response");
return prevHeartbeatResponse;
}
}
}
...(4)过程四,处理心跳请求。处理心跳请求环节是整个JobTracker心跳的机制的核心。这里最主要的任务就是根据心跳带来的TraskTracker状态信息去更新当前集群的资源使用情况、Task信息和节点健康信息。代码如下:
// Process this heartbeat
short newResponseId = (short)(responseId + 1);//心跳相应加1
//记录心跳的发送时间,以便发现在一定时间内未发送心跳的TaskTracker,并将之标注为死亡状态,以后不再向其分配新的Tasks
status.setLastSeen(now);
if (!processHeartbeat(status, initialContact, now)) {
//如果存在针对该TaskTracker的上一次心跳应答时,将其清空以便将新的应答放进来
if (prevHeartbeatResponse != null) {
trackerToHeartbeatResponseMap.remove(trackerName);
}
//当处理心跳请求失败时将返回“重新初始化”给该TaskTracker
return new HeartbeatResponse(newResponseId,
new TaskTrackerAction[] {new ReinitTrackerAction()});
}其他的小的细节可以自己看代码和注释,这个主要讲讲processHeartbeat方法,跟进去:/**
* Process incoming heartbeat messages from the task trackers.
*/
private synchronized boolean processHeartbeat(
TaskTrackerStatus trackerStatus,
boolean initialContact,
long timeStamp) throws UnknownHostException {
getInstrumentation().heartbeat();
String trackerName = trackerStatus.getTrackerName();
synchronized (taskTrackers) {
synchronized (trackerExpiryQueue) {
//通过旧的以及当前心跳传来的TaskTracker状态信息更新TaskTracker对象记录的状态资源信息,seenBefore返回值代表是否在JobTracker端的上一次存在的该TaskTracker的状态信息(true表示存在)
boolean seenBefore = updateTaskTrackerStatus(trackerName,
TaskTracker taskTracker = getTaskTracker(trackerName);
if (initialContact) {//初次心跳连接
// If it's first contact, then clear out
// any state hanging around
if (seenBefore) {//在JobTracker端,存在上一次该TaskTracker的状态信息,则将其清空
lostTaskTracker(taskTracker);
}
} else {//非初次连接
// If not first contact, there should be some record of the tracker
if (!seenBefore) {//在JobTracker端,不存在上一次该TaskTracker的状态信息
LOG.warn("Status from unknown Tracker : " + trackerName);
updateTaskTrackerStatus(trackerName, null);//更新该TaskTrakcer的资源状况
return false;
}
}
if (initialContact) {
// if this is lost tracker that came back now, and if it's blacklisted
// increment the count of blacklisted trackers in the cluster
if (isBlacklisted(trackerName)) {//判断该TaskTracker是否在黑名单中
faultyTrackers.incrBlacklistedTrackers(1);
}
// This could now throw an UnknownHostException but only if the
// TaskTracker status itself has an invalid name
addNewTracker(taskTracker);
}
}
}
updateTaskStatuses(trackerStatus);//更新Task信息
updateNodeHealthStatus(trackerStatus, timeStamp);//更新节点健康状态信息
return true;
}该方法处理新的心跳请求,简单地来说就是通过旧的TaskTracker状态信息和当前心跳带来的TaskTracker对象的状态信息去更新集群当前的资源信息。另外还会去更新该TraskTracker上的Tasks信息和更新发来当前心跳节点的健康状态信息。上面处理心跳信息的代码中,还会判断是否是TT和JT的初次连接,如果非初次连接并且上次的TaskTracker状态信息不存在则该次心跳处理失败直接返回false,对该TaskTracker下重新初始化命令,让其重启初始化。再看看具体的更新方法updateTaskTrackerStatusprivate boolean updateTaskTrackerStatus(String trackerName,
TaskTrackerStatus status) {
TaskTracker tt = getTaskTracker(trackerName);
//获得上一次TT在JT中的状态信息对象
TaskTrackerStatus oldStatus = (tt == null) ? null : tt.getStatus();
//根据上一次TT在JT中的状态信息对象存在时,更新资源信息。
if (oldStatus != null) {
totalMaps -= oldStatus.countMapTasks();
totalReduces -= oldStatus.countReduceTasks();
occupiedMapSlots -= oldStatus.countOccupiedMapSlots();
occupiedReduceSlots -= oldStatus.countOccupiedReduceSlots();
getInstrumentation().decRunningMaps(oldStatus.countMapTasks());
getInstrumentation().decRunningReduces(oldStatus.countReduceTasks());
getInstrumentation().decOccupiedMapSlots(oldStatus.countOccupiedMapSlots());
getInstrumentation().decOccupiedReduceSlots(oldStatus.countOccupiedReduceSlots());
...
//根据当前心跳传过来的TaskTracker状态信息对象更新当前资源信息。
if (status != null) {
totalMaps += status.countMapTasks();
totalReduces += status.countReduceTasks();
occupiedMapSlots += status.countOccupiedMapSlots();
occupiedReduceSlots += status.countOccupiedReduceSlots();
getInstrumentation().addRunningMaps(status.countMapTasks());
getInstrumentation().addRunningReduces(status.countReduceTasks());
getInstrumentation().addOccupiedMapSlots(status.countOccupiedMapSlots());
getInstrumentation().addOccupiedReduceSlots(status.countOccupiedReduceSlots());
...
getInstrumentation().setMapSlots(totalMapTaskCapacity);
getInstrumentation().setReduceSlots(totalReduceTaskCapacity);
...(5)过程五,为TaskTracker下达命令过程。该过程主要是遍历JobTracker中的各种对象映射集合(可以看我源码分析第二篇文章的第三点http://zengzhaozheng.blog.51cto.com/8219051/1352280),取得相关命令,然后为TaskTracker下达命令。
...
// Check for tasks to be killed
List<TaskTrackerAction> killTasksList = getTasksToKill(trackerName);
if (killTasksList != null) {
actions.addAll(killTasksList);
}
// Check for jobs to be killed/cleanedup
List<TaskTrackerAction> killJobsList = getJobsForCleanup(trackerName);
if (killJobsList != null) {
actions.addAll(killJobsList);
}
// Check for tasks whose outputs can be saved
List<TaskTrackerAction> commitTasksList = getTasksToSave(status);
if (commitTasksList != null) {
actions.addAll(commitTasksList);
}
// calculate next heartbeat interval and put in heartbeat response
int nextInterval = getNextHeartbeatInterval();//生成下一次心跳汇报时间
response.setHeartbeatInterval(nextInterval);
response.setActions(
actions.toArray(new TaskTrackerAction[actions.size()]));
// check if the restart info is req
if (addRestartInfo) {
response.setRecoveredJobs(recoveryManager.getJobsToRecover());
}
// Update the trackerToHeartbeatResponseMap
trackerToHeartbeatResponseMap.put(trackerName, response);
// Done processing the hearbeat, now remove 'marked' tasks
removeMarkedTasks(trackerName);
...详细说说各种命令:ReinitTrackerAction,重新初始化命令
上面的过程分析中,已经多次提到过ReinitTrackerAction命令,它在容错性检测出错的时候往往会被执行,JobTracker发送这个命令对TaskTracker重新进行初始化。在JobTracker端的整个心跳处理过程中,运行ReinitTrackerAction命令大体有2种(在上面的分析过程中都有提到,可以回头看看):
丢失上次心跳应道信息:JobTracker保存了向每个TaskTracker发送的最近心跳应答信息。如果JobTracker不是刚刚重启并且TaskTracker不是初次链接JobTracker,而最近的心跳应答信息 丢失,这会造成不一致情况。
丢失TaskTracker的状态信息:JobTracker接收到任何一个心跳信息后,都会将其TaskTracker的对象信息(TaskTrackerStatus类)保存起来。如果一个TaskTracker 非初次连接JobTracker但是其状态信息又不存在,造成不一致的情况。
LaunchTaskAction
该类封装了TaskTracker分配的新任务,新任务的类型分两种:计算型任务和辅助型任务。其中计算型任务负责处理实际数据的任务,也就是我们常说的Reduce和Map任务,他们由专门的任务调度器去调用(默认是FIFO调度器)。另外辅助型任务包括:job-setup task、job-cleanup task和task-cleanup task三种。task-cleanup task的主要作用是清理失败的map或者reduce任务的部分结果数据,它由jobTracker直接调度,而且其调度的优先级比map和reduce任务都要高。至于job-setup task和job-cleanup task任务的作用我认为比较简单,主要是标志map和reduce作业运行开始和运行结束的同步标志。jobTracker为一个有空闲slot并且不在黑名单中的taskTracker分配任务的选择顺序是先辅助型任务然后计算型任务,这点我们可以从heartbeat方法看出来:
HeartbeatResponse response = new HeartbeatResponse(newResponseId, null);
List<TaskTrackerAction> actions = new ArrayList<TaskTrackerAction>();
//faultyTrackers队列,当该TaskTracker上有任务运行失败,那么其对应的host会被添加到此列表中,
//同时错误信息以及发生错误的时间、错误次数也会被记录起来.按一定的规则(没有详细研究)组成黑名单和灰名单。
boolean isBlacklisted = faultyTrackers.isBlacklisted(status.getHost());
// Check for new tasks to be executed on the tasktracker
if (recoveryManager.shouldSchedule() && acceptNewTasks && !isBlacklisted) {
//获得所有TT状态信息
TaskTrackerStatus taskTrackerStatus = getTaskTrackerStatus(trackerName);
if (taskTrackerStatus == null) {
LOG.warn("Unknown task tracker polling; ignoring: " + trackerName);
} else {
//有限选择辅助型任务,选择优先顺序为:job-cleanup task、task-cleanup task和job-setup task
//这样可以让运行完成的作业快速结束,新提交的作业立刻进入到运行状态
List<Task> tasks = getSetupAndCleanupTasks(taskTrackerStatus);
//如果没有辅助型任务就选择执行计算行任务
if (tasks == null ) {
//直接有任务调度器去选择一个或者多个计算行任务
tasks = taskScheduler.assignTasks(taskTrackers.get(trackerName));
}
if (tasks != null) {
for (Task task : tasks) {
expireLaunchingTasks.addNewTask(task.getTaskID());
if(LOG.isDebugEnabled()) {
LOG.debug(trackerName + " -> LaunchTask: " + task.getTaskID());
}
actions.add(new LaunchTaskAction(task));
}
}
}KillTaskAction该类封装了TaskTracker需要杀死的任务。TaskTracker收到该任务后会杀掉对应的任务以及清理掉工作目录和释放slot。JobTracker主要在下面情况下会向TrackerTracker发送KillTaskAction命令(不全):
(1)整个作业运行失败,其他正在运行的Task也会被杀死。
(2)启动推测执行任务机制(默认启动)后,同一份数据可能有2个Task Attempt处理。只要一个Task Attempt运行成功后,两外一个处理同一份数据的任务就会被kill掉。
(3)TaskTracker在指定时间内没有向JobTracker汇报心跳,则JobTracker会任务它已经死掉,那么在它上面运行的所有task就会被标注为死亡。
(4)用户自己直接调用命令"bin/hadoop job -kill-task"或者"bin/hadoop job -fail-task",使一个或者多个任务失败。
KillTaskAction
KillTaskAction封装了TaskTracker待清理的作业。当TaskTracker接收到KillTaskAction命令后会清理此作业工作目录。下面几个主要的场景会出现这种情况:
(1)用户主动杀死作业,调用"bin/hadoop job -kill"或者"bin/hadoop job -fail"命令。
(2)作业运行完毕,通知TaskTracker清理作业目录。
(3)作业运行失败,通知TaskTracker清理作业目录。
CommitTaskAction
该类封装了TaskTracker需要提交的任务。为了防止同一个TaskInProgress的两个同时运行的Task Attempt(例如打开推测执行功能,一个任务可能有多个备份任务)同时打开一个文件或者往同一个文件中写数据而生产冲突,Hadoop让每个Task Attempt写到单独一个文件中(以taskAttemptID命名,比如attempt_201402171212_0009_r_000000_0)中。通常而言,Hadoop让每个Task Attempt将计算结果写到临时目录${mapred.output.dir}/_tmporary/_${taskID}中,当某个Task Attempt运行成功后,再将运行结果转移到最终目录${mapred.output.dir}中。Hadoop将一个成功运行的Task Attempt结果文件从临时目录移动到最终目录的过程,称为“任务提交”。当TaskProgress中的一个任务被提交后,其他任务将被杀死,同时意味着该TaskTracker运行完成。
三、集群规模调整动态调整心跳间隔
从在上一篇blog中分析TaskTracker端的心跳机制中,我们知道TaskTracker会通过“外带心跳”和根据Task完成数目来动态调整心跳间距。 JobTracker端的心跳处理也有相应的机制以用来调整TaskTracker心跳的汇报时间间隔。这种调整的意义在于可以提高系统的吞吐量,避免心跳间隔过小造成JobTracker要进行并发处理的请求压力大,和心跳间隔过大造成资源浪费不能是TaskTracker及时汇报资源信息给JobTracker,进而为之分配任务。JobTracker监控者整个集群的规模情况,可以通过这个动态地调整每个TaskTracker下次汇报心跳的时间间隔,并通过心跳机制告诉TaskTracker。 最重要的是这种机制还是可控制的,JobTracker允许用户通过参数设置心跳的时间间隔加速比例,简单说就是每增加mapred.heartbeats.in.second(最小是1,默认为100)个节点,心跳时间间隔就增加mapreduce.jobtracker.heartbeats.scaling.factor(最小是0.01,默认1)秒,简单说默认情况下增加100个节点心跳就增加1秒。但是,为了防止用户参数设置不合理而对JobTracker产生较大负载,JobTracker要求心跳间隔大于或者等于3秒。具体算法看代码,JobTracker类的getNextHeartbeatInterval方法:
/**
* Calculates next heartbeat interval using cluster size.
* Heartbeat interval is incremented by 1 second for every 100 nodes by default.
* @return next heartbeat interval.
*/
public int getNextHeartbeatInterval() {
// get the no of task trackers
//获得当前集群的TaskTracker数目
int clusterSize = getClusterStatus().getTaskTrackers();
int heartbeatInterval = Math.max(
(int)(1000 * HEARTBEATS_SCALING_FACTOR *
Math.ceil((double)clusterSize /
NUM_HEARTBEATS_IN_SECOND)),
HEARTBEAT_INTERVAL_MIN) ;
return heartbeatInterval;
}其中HEARTBEATS_SCALING_FACTOR对应上面所说的mapreduce.jobtracker.heartbeats.scaling.factor参数,NUM_HEARTBEATS_IN_SECOND对应着mapred.heartbeats.in.second参数,HEARTBEAT_INTERVAL_MIN默认值为3 * 1000。参考文献:[1]《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》[2] http://hadoop.apache.org

相关文章推荐
- hadoop之MapReduce框架TaskTracker端心跳机制分析(源码分析第六篇) 推荐
- Hadoop源码分析24 JobTracker启动和心跳处理流程
- Hadoop源码分析27 JobTracker空载处理心跳
- Hadoop之MapReduce框架心跳机制分析
- hadoop运行原理之Job运行(四) JobTracker端心跳机制分析
- Hadoop源码分析之心跳机制
- Hadoop源码分析23:MapReduce的Job提交过程
- MapReduce job在JobTracker初始化源码级分析
- Hadoop源码分析26 JobTracker主要容器和线程
- Hadoop源码分析28 JobTracker 处理JobClient请求
- Hadoop源码分析之心跳机制
- Hadoop源码分析之心跳机制
- Hadoop源码分析--MapReduce作业(job)提交源码跟踪
- mapreduce源码分析之JobTracker
- Hadoop之JobTracker源码分析
- mapreduce中jobtracker进程的分析
- Hadoop源码分析(MapReduce概论)
- Hama框架学习(一) 从源码角度分析job的提交和运行过程
- hadoop中job提交的源码分析
- MapReduce源码分析之JobSplitWriter