熵(信息论中)
2014-01-15 19:08
162 查看
1.在信息论中,熵表示的是不确定性的量度。用来消除不确定性的东西,对难以准确计算的信息进行准确的描述。
2.随机变量,都有数学期望,但是不一定存在。
3.计算
熵的计算
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。因此,使用一枚正常硬币进行若干次抛掷,这个事件的熵是一比特,因为结果不外乎两个——正面或者反面,可以表示为
另一个稍微复杂的例子是假设一个随机变量
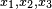
,(数据压缩,
二分搜索树 ,x1在根部,路径长度为1,x2,3在路径长度为2处)概率分别为
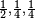
,那么编码平均比特长度是:

。其熵为3/2。
因此熵实际是对随机变量的比特量和顺次发生概率相乘再总和的数学期望。
下面出处:http://blog.sciencenet.cn/u/physicsxuxiao
【最近经常有人在科学网上讨论汉字改革的问题,最关心的人有李小文老师和张能立老师。但是有些基本概念的模糊,影响了这个问题的讨论。按照李小文老师的要求,我在此做一个简单的文字熵的介绍,来消除不必要的误解和推证。】
有人望文生义,在没有对问题有清楚理解的基础上,不断使用“熵”这个词,还稀里糊涂地将热力学熵和信息熵混同。以为汉字的熵大,就说明汉字的表示水平就不行。还因此推论,汉字的信息熵大,说明汉字不精确,我们思考能力也不行,思维也不精确,所以我们要改革,从文字到思想应该向英文这种熵小的语言靠齐。
我现在声明一下,以下我谈的熵都是“信息熵”。
信息熵是什么意思?就是“每个符号的平均信息量”的意思。
首先说说什么叫信息量。
其实这个概念一点也不神秘,就是说我要表达一个信息,需要多少个符号的意思。比如我要赞扬YC的文章写得好,我可以像下面这样说:
(1) YC 好!
(2)YC的文章好!
(3)YC文章实在是太好了!
就我要表达的信息来说,(2)就够了,(1)则表达不清楚,(3)则表达过头了。因此我所要表达的信息,按照科学网常用的符号系统中的符号来表达,就需要7个符号。这“7个符号”,就是信息量。
但是,我们表达同样的信息,用不同符号集的符号,需要的符号个数并不相同,不如我们用英文表达(2):
YC‘s articles are excellent.
我们可以数一下,这一共是28个符号(含空格)。
所以为了给“信息量”一个统一的计量标准,我们将采用统一的一个符号系统计算表达一个信息所需要符号个数。
由于计算机信息技术的发展,现在最常用的,我们是采用(0,1)作为符号集或者符号系统,而其一个符号的长度,我们称为“位”(bit)。(其实莫尔斯电码也是二进制符号系统。)
那么怎么计算一个符号系统的某个符号所携带的信息量呢?在采用bit为单位的情况下,我们采用以下公式:
I(ai)=−log2P(ai)
这个公式是说,在一个符号系统中,若第i个符号(我们用ai表示)出现的概率为P(ai) ,
而此符号的信息量I(ai)如果用bit计量,则用以上公式计算。为什么这样计算呢?在一个符号系统中,出现频率越高的符号,其含有的信息量越低,反之则越高。我们可以想想一个极端情况,如果一个符号系统只有一个符号,出现来出现去,就是那个符号。因此这个符号含的信息量就是零,出现不出现对接收者都没啥差别。再想想一种情况,如果一个符号系统中的某个符号出现的概率接近于零,那么这个符号要么长久不出现,要么一出现就带来惊人的信息量,极限情况下是趋向于无穷大。比如,我们这一生,几乎不可能中大奖,但是如果哪天晚上你接到电话,原来是NB委员会通知你得了NB奖,这个消息的信息量是不是接近无穷大?
其实计算文字的信息量,由于很多情况,我们并不清楚使用一种语言,表达特定的信息,怎么样讲用字或者字符最少,所以,计算本身也是困难的。
最简单的办法,我们只能统计一个符号集中间出现某个符号的概率,然后针对特定的一个短语或者句子,来讨论相关的信息量。比如 “YC的文章好!”是在约有3000个字符常用中文字符集中选用的7个符号,假定每个字符出现的概率完全相等,则其大致估算的信息量为:
7∗log23000=7∗11.55≈81(bits)
平均每个符号的平均信息量为11.55bits。
同样的办法,我们也可以计算 ‘YC‘s articles are excellent. ’的信息量,假定英文用的符号集含60个(含26个字母大小写,空格与常用标点。)符号,每个符号出现概率相同,则其信息量估算为:
28∗log260=28∗5.91≈166(bits)
符号的平均信息量为5.91bits。
粗粗一看,好像表达同样信息,汉语使用的信息量低于英语(还有读者认为这说明汉语不精确),但是细心的读者应该留意到,我这样算信息量和平均信息量是不对的,因为,不论中英文,我假定每个符号出现的概率相同明显不可能,比如中文中的“的”出现频率就相当高,而英文字母符号中的“空格”出现频率也非常大。对于中文而言,我的计算大致靠谱,因为中文字符多,所以就是有误差,算起来问题也不会特别大;但是英文字母少,算起来问题就大了。
事实上,我们规定单个符号的信息熵,即平均信息量如下:
H(X)=−∑Ni=1P(ai)log2P(ai)(bits/sign)
其中X代表“从符号集取单符号”的意思(严谨点说,X是一个“随机变量”); P(ai)表示取符号ai的概率,而小标i从1取到N,N是符号集的符号个数。而单位“bits/sign”是表示每个符号平均有多少信息量的意思。
通过考虑符号间的关联和汉字出现的频度,最后我们大致知道,汉字的信息熵是9.65bits/sign,而英文的信息熵是4.03bits/sign。
这是什么意思呢?这是说如果表达某个意思,如果我们需要100个汉字的话,那么我们大致需要965/4.03约=240个英文字母。换言之一个汉字所包含的信息量大约是一个英文字母的两倍多。这也是为什么我们将一篇中文翻译成英文,篇幅明显变长的原因。再说清楚些,这说明一个汉字表达的意思要比一个英文字母的意思要精确得多。
所以,文字的熵越大,其包含的信息量越大,其单个符号表达则越清楚。
这里必须讲点题外话。
我们应当清楚,将一个汉字和一个字母去比较是不公平的。因为单个汉字已经有很大程度上有独立的含义,英文字母则不同,虽然每个字母的来源如同汉语一样,从象形符号(古埃及)演化而来,但是现在的单个符号基本没有具体含义。英文字母更类似汉字的点横撇捺或者某个部首而已。
那么一个一个汉字同一个英文词汇比较呢?这同样是不公平的,因为现代汉语以双字词或者三字词为主,所以单个字包含的信息量也大不到可以和一个独立的英文词汇去比较的水平。
那么,最好的对应,应该是词对词。这时候,我们大致统计一下,就容易发现,两种语言的差距,并不太大。因为在大多数情况下,一个英文词,就正好可以翻成一个汉语词。
2.随机变量,都有数学期望,但是不一定存在。
3.计算
熵的计算
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。因此,使用一枚正常硬币进行若干次抛掷,这个事件的熵是一比特,因为结果不外乎两个——正面或者反面,可以表示为
0, 1编码,而且两个结果彼此之间相互独立。若进行
n次独立实验,则熵为
n,因为可以用长度为
n的比特流表示。[1]但是如果一枚硬币的两面完全相同,那个这个系列抛硬币事件的熵等于零,因为结果能被准确预测。现实世界里,我们收集到的数据的熵介于上面两种情况之间。
另一个稍微复杂的例子是假设一个随机变量
X,取三种可能值
,(数据压缩,
二分搜索树 ,x1在根部,路径长度为1,x2,3在路径长度为2处)概率分别为
,那么编码平均比特长度是:
。其熵为3/2。
因此熵实际是对随机变量的比特量和顺次发生概率相乘再总和的数学期望。
下面出处:http://blog.sciencenet.cn/u/physicsxuxiao
【最近经常有人在科学网上讨论汉字改革的问题,最关心的人有李小文老师和张能立老师。但是有些基本概念的模糊,影响了这个问题的讨论。按照李小文老师的要求,我在此做一个简单的文字熵的介绍,来消除不必要的误解和推证。】
有人望文生义,在没有对问题有清楚理解的基础上,不断使用“熵”这个词,还稀里糊涂地将热力学熵和信息熵混同。以为汉字的熵大,就说明汉字的表示水平就不行。还因此推论,汉字的信息熵大,说明汉字不精确,我们思考能力也不行,思维也不精确,所以我们要改革,从文字到思想应该向英文这种熵小的语言靠齐。
我现在声明一下,以下我谈的熵都是“信息熵”。
信息熵是什么意思?就是“每个符号的平均信息量”的意思。
首先说说什么叫信息量。
其实这个概念一点也不神秘,就是说我要表达一个信息,需要多少个符号的意思。比如我要赞扬YC的文章写得好,我可以像下面这样说:
(1) YC 好!
(2)YC的文章好!
(3)YC文章实在是太好了!
就我要表达的信息来说,(2)就够了,(1)则表达不清楚,(3)则表达过头了。因此我所要表达的信息,按照科学网常用的符号系统中的符号来表达,就需要7个符号。这“7个符号”,就是信息量。
但是,我们表达同样的信息,用不同符号集的符号,需要的符号个数并不相同,不如我们用英文表达(2):
YC‘s articles are excellent.
我们可以数一下,这一共是28个符号(含空格)。
所以为了给“信息量”一个统一的计量标准,我们将采用统一的一个符号系统计算表达一个信息所需要符号个数。
由于计算机信息技术的发展,现在最常用的,我们是采用(0,1)作为符号集或者符号系统,而其一个符号的长度,我们称为“位”(bit)。(其实莫尔斯电码也是二进制符号系统。)
那么怎么计算一个符号系统的某个符号所携带的信息量呢?在采用bit为单位的情况下,我们采用以下公式:
I(ai)=−log2P(ai)
这个公式是说,在一个符号系统中,若第i个符号(我们用ai表示)出现的概率为P(ai) ,
而此符号的信息量I(ai)如果用bit计量,则用以上公式计算。为什么这样计算呢?在一个符号系统中,出现频率越高的符号,其含有的信息量越低,反之则越高。我们可以想想一个极端情况,如果一个符号系统只有一个符号,出现来出现去,就是那个符号。因此这个符号含的信息量就是零,出现不出现对接收者都没啥差别。再想想一种情况,如果一个符号系统中的某个符号出现的概率接近于零,那么这个符号要么长久不出现,要么一出现就带来惊人的信息量,极限情况下是趋向于无穷大。比如,我们这一生,几乎不可能中大奖,但是如果哪天晚上你接到电话,原来是NB委员会通知你得了NB奖,这个消息的信息量是不是接近无穷大?
其实计算文字的信息量,由于很多情况,我们并不清楚使用一种语言,表达特定的信息,怎么样讲用字或者字符最少,所以,计算本身也是困难的。
最简单的办法,我们只能统计一个符号集中间出现某个符号的概率,然后针对特定的一个短语或者句子,来讨论相关的信息量。比如 “YC的文章好!”是在约有3000个字符常用中文字符集中选用的7个符号,假定每个字符出现的概率完全相等,则其大致估算的信息量为:
7∗log23000=7∗11.55≈81(bits)
平均每个符号的平均信息量为11.55bits。
同样的办法,我们也可以计算 ‘YC‘s articles are excellent. ’的信息量,假定英文用的符号集含60个(含26个字母大小写,空格与常用标点。)符号,每个符号出现概率相同,则其信息量估算为:
28∗log260=28∗5.91≈166(bits)
符号的平均信息量为5.91bits。
粗粗一看,好像表达同样信息,汉语使用的信息量低于英语(还有读者认为这说明汉语不精确),但是细心的读者应该留意到,我这样算信息量和平均信息量是不对的,因为,不论中英文,我假定每个符号出现的概率相同明显不可能,比如中文中的“的”出现频率就相当高,而英文字母符号中的“空格”出现频率也非常大。对于中文而言,我的计算大致靠谱,因为中文字符多,所以就是有误差,算起来问题也不会特别大;但是英文字母少,算起来问题就大了。
事实上,我们规定单个符号的信息熵,即平均信息量如下:
H(X)=−∑Ni=1P(ai)log2P(ai)(bits/sign)
其中X代表“从符号集取单符号”的意思(严谨点说,X是一个“随机变量”); P(ai)表示取符号ai的概率,而小标i从1取到N,N是符号集的符号个数。而单位“bits/sign”是表示每个符号平均有多少信息量的意思。
通过考虑符号间的关联和汉字出现的频度,最后我们大致知道,汉字的信息熵是9.65bits/sign,而英文的信息熵是4.03bits/sign。
这是什么意思呢?这是说如果表达某个意思,如果我们需要100个汉字的话,那么我们大致需要965/4.03约=240个英文字母。换言之一个汉字所包含的信息量大约是一个英文字母的两倍多。这也是为什么我们将一篇中文翻译成英文,篇幅明显变长的原因。再说清楚些,这说明一个汉字表达的意思要比一个英文字母的意思要精确得多。
所以,文字的熵越大,其包含的信息量越大,其单个符号表达则越清楚。
这里必须讲点题外话。
我们应当清楚,将一个汉字和一个字母去比较是不公平的。因为单个汉字已经有很大程度上有独立的含义,英文字母则不同,虽然每个字母的来源如同汉语一样,从象形符号(古埃及)演化而来,但是现在的单个符号基本没有具体含义。英文字母更类似汉字的点横撇捺或者某个部首而已。
那么一个一个汉字同一个英文词汇比较呢?这同样是不公平的,因为现代汉语以双字词或者三字词为主,所以单个字包含的信息量也大不到可以和一个独立的英文词汇去比较的水平。
那么,最好的对应,应该是词对词。这时候,我们大致统计一下,就容易发现,两种语言的差距,并不太大。因为在大多数情况下,一个英文词,就正好可以翻成一个汉语词。

相关文章推荐
- google play v2支付修改 android:targetSdkVersion 这个大于11出现异常问题
- 黑马程序员_多线程
- 《黑马程序员》 网络编程 TCP、UDP、文本转化器、上传文本等练习
- IS-IS
- jQuery AJAX —开篇 $.load()
- svn switch
- NULL:缺失数据本身也可能是有价值的
- cocos2d-x 节点操作 -->J2ME
- 数据库中插入不进数据现象
- 迷一样的c
- php 上传文件到ftp上
- 浅谈算法和数据结构: 一 栈和队列
- 生产环境主从复制出错
- 四元数
- 本地管理表空间(LMT)
- 16个HTML5 框架、模板以及生成工具
- 递推数列
- 香港招行费用真贵
- NO6.java笔记【三维数组】
- Linux下面oracle安装方法总结