FW:分布式实时计算storm 原理…
2014-01-15 12:22
281 查看
http://my.oschina.net/leejun2005/blog/147607?from=20130804
storm 原理简介及单机版安装指南
141人收藏此文章, 我要收藏发表于12天前(2013-07-2804:44) , 已有4101次阅读,共2个评论
目录:[ - ]
1、准备工作
2、一个Storm集群的基本组件
3、Topologies
4、Stream
5、数据模型(Data Model)
6、一个简单的Topology
7、流分组策略(Stream grouping)
8、使用别的语言来定义Bolt
9、可靠的消息处理10、单机版安装指南
本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial
Storm是一个分布式的、高容错的实时计算系统。
Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
在这个教程里面我们将学习如何创建Topologies,
并且把topologies部署到storm的集群里面去。Java将是我们主要的示范语言,
个别例子会使用python以演示storm的多语言特性。
1、准备工作
这个教程使用storm-starter项目里面的例子。我推荐你们下载这个项目的代码并且跟着教程一起做。先读一下:配置storm开发环境和新建一个strom项目这两篇文章把你的机器设置好。2、一个Storm集群的基本组件
storm的集群表面上看和hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job,而在Storm上面你运行的是Topology。它们是非常不一样的 — 一个关键的区别是:
一个MapReduce Job最终会结束,
而一个Topology运永远运行(除非你显式的杀掉他)。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker
node)。控制节点上面运行一个后台程序: Nimbus,
它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点(类似
TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要
启动/关闭工作进程。每一个工作进程执行一个Topology(类似
Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似
Child)组成。
原理简介及单机版安装指南(1)" /> storm
topology结构
原理简介及单机版安装指南(1)" /> Storm VS MapReduce
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面,
要么在本地磁盘上。这也就意味着你可以用kill -9来杀死nimbus和supervisor进程,
然后再重启它们,它们可以继续工作, 就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
3、Topologies
为了在storm上面做实时计算,你要去建立一些topologies。一个topology就是一个计算节点所组成的图。Topology里面的每个处理节点都包含处理逻辑,
而节点之间的连接则表示数据流动的方向。
运行一个Topology是很简单的。首先,把你所有的代码以及所依赖的jar打进一个jar包。然后运行类似下面的这个命令。
1 | strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2 |
backtype.strom.MyTopology, 参数是arg1,
arg2。这个类的main函数定义这个topology并且把它提交给Nimbus。storm
jar负责连接到nimbus并且上传jar文件。
因为topology的定义其实就是一个Thrift结构并且nimbus就是一个Thrift服务,
有可以用任何语言创建并且提交topology。上面的方面是用JVM
-based语言提交的最简单的方法, 看一下文章: 在生产集群上运行topology去看看怎么启动以及停止topologies。
4、Stream
Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。比如:你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
spout的流的源头。比如一个spout可能从Kestrel队列里面读取消息并且把这些消息发射成一个流。又比如一个spout可以调用twitter的一个api并且把返回的tweets发射成一个流。
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。

原理简介及单机版安装指南(1)" />
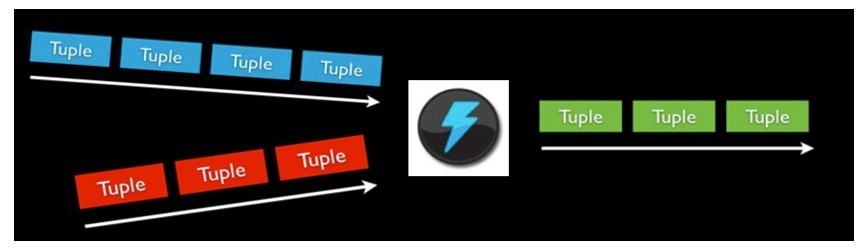
bolt可以接收任意多个输入stream,
作一些处理, 有些bolt可能还会发射一些新的stream。一些复杂的流转换,
比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个bolt。 Bolt可以做任何事情: 运行函数,
过滤tuple, 做一些聚合, 做一些合并以及访问数据库等等。
Bolt处理输入的Stream,并产生新的输出Stream。Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute(Tuple
input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
原理简介及单机版安装指南(1)" />
spout和bolt所组成一个网络会被打包成topology,
topology是storm里面最高一级的抽象(类似 Job),
你可以把topology提交给storm的集群来运行。topology的结构在Topology那一段已经说过了,这里就不再赘述了。
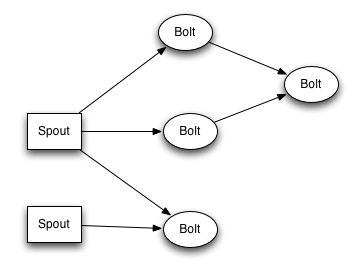
topology结构
topology里面的每一个节点都是并行运行的。 在你的topology里面, 你可以指定每个节点的并行度,
storm则会在集群里面分配那么多线程来同时计算。
一个topology会一直运行直到你显式停止它。storm自动重新分配一些运行失败的任务, 并且storm保证你不会有数据丢失,
即使在一些机器意外停机并且消息被丢掉的情况下。
5、数据模型(Data Model)
storm使用tuple来作为它的数据模型。每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型,在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型,
只要你实现对应的序列化器(serializer)。
一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性。

原理简介及单机版安装指南(1)" />
Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value
List。
一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream。

原理简介及单机版安装指南(1)" />
topology里面的每个节点必须定义它要发射的tuple的每个字段。
比如下面这个bolt定义它所发射的tuple包含两个字段,类型分别是: double和triple。
01 | publicclassDoubleAndTripleBoltimplementsIRichBolt { |
02 | privateOutputCollectorBase _collector; |
03 |
04 | @Override |
05 | publicvoidprepare(Map
conf, TopologyContext context, OutputCollectorBase collector)
{ |
06 | _collector = collector; |
07 | } |
08 |
09 | @Override |
10 | publicvoidexecute(Tuple
input) { |
11 | intval = input.getInteger( 0 ); |
12 | _collector.emit(input,newValues(val* 2 , val* 3 )); |
13 | _collector.ack(input); |
14 | } |
15 |
16 | @Override |
17 | publicvoidcleanup()
{ |
18 | } |
19 |
20 | @Override |
21 | publicvoiddeclareOutputFields(OutputFieldsDeclarer
declarer) { |
22 | declarer.declare(newFields( "double" , "triple" )); |
23 | } |
24 | } |
"triple"]。这个bolt的其它部分我们接下来会解释。

相关文章推荐
- FW:分布式实时计算storm 原理…
- FW:分布式实时计算storm 原理…
- FW:分布式实时计算storm 原理…
- FW:分布式实时计算storm 原理…
- 实时可靠的开源分布式实时计算系统——Storm
- (第8篇)实时可靠的开源分布式实时计算系统——Storm
- 从Storm和Spark 学习流式实时分布式计算的设计
- Storm分布式实时流计算框架相关技术总结
- Storm 实时计算分布式锁 Curator的使用
- (第8篇)实时可靠的开源分布式实时计算系统——Storm
- FW: WebGIS设计与实现原理 - ATL S…
- Storm是一个分布式的、高容错的实时计算系统。
- 学习总结十五:分布式实时计算系统storm简介
- Storm实时分布式计算系统简介
- 一脸懵逼学习Storm的搭建--(一个开源的分布式实时计算系统)
- 一脸懵逼学习Storm---(一个开源的分布式实时计算系统)
- 从Storm和Spark 学习流式实时分布式计算的设计
- 一脸懵逼学习Storm---(一个开源的分布式实时计算系统)
- 从Storm和Spark 学习流式实时分布式计算的设计
- 实时可靠的开源分布式实时计算系统——Storm